CPU、内存、I/O速度大比拼
CPU的读写速度是内存的100倍左右,而内存的读写速度又是I/O的10倍左右。根据"木桶理论",速度取决于最慢的I/O。为了解决速度不匹配的问题,通常在CPU和主内存间增加了缓存,内存和I/O之间增加了操作系统层面的进程和线程。
我们都知道"技术是把双刃剑",解决了速度不匹配问题,又引入了高并发场景下的线程安全问题。将并发安全时,应该先讲一下JMM概念。
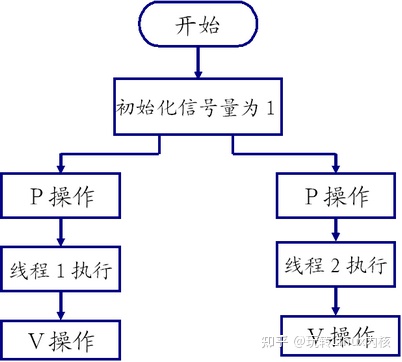
JMM的工作线程模型
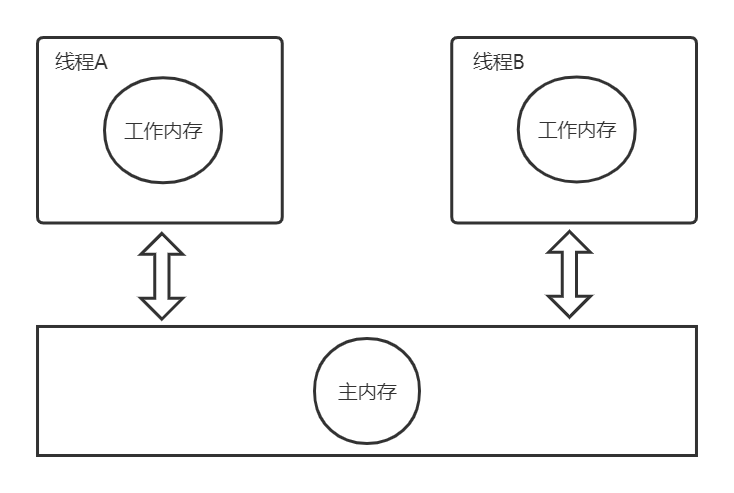
图1 JMM的工作线程模型
.
图1为JMM的工作线程模型,线程访问变量并不是在主内存中直接操作的,而是拷贝主内存的变量值到自己的工作内存中,操作后再写回主内存。
例如图1中的线程A、B,主内存存在变量i,值为0。线程A、B都拷贝i到自己的工作内存,此时在线程A、B的工作内存中,i的值都为0。线程A、B都对i进行+1操作,期望结果本是2,但结果却是1。这是为何呢?
可见性和原子性
public class Main {
private static int i = 0;
public static void main(String[] args) throws InterruptedException {
Main main = new Main();
Thread a = new Thread(() -> {
main.add10K();
}, "A"); // 线程A
Thread b = new Thread(() -> {
main.add10K();
}, "B"); // 线程B
a.start(); // 启动线程A
b.start(); // 启动线程B
a.join(); // 等待线程A执行完毕
b.join(); // 等待线程B执行完毕
System.out.println(i); // 打印i的值,期望20000
}
// +10000操作
public void add10K(){
for (int j = 0; j < 10000; j++) {
i++;
}
}
}上面程序很简单,也有注释,就不做多解释了。讲一下运行结果,多次运行的结果都是小于20000。这是为什么呢?其实就是可见性和原子性问题。
i++其实不是一条CPU指令,他是三条CPU指令构成的。
加载i的值
对i的值进行+1
转载i的值
因此线程A、B进行i++操作时,无法及时感知到在其他工作内存空间变量的值。解决办法自然就是在工作内存改变后,即使通知其他工作内存,将该变量的值丢掉,重新取主内存拷贝一个新的。可以通过volatile、synchronized等关键字解决可见性问题。原子性只有synchronized能保证,volatile只能保证可见性,由于i++此类非单条CPU指令,操作系统无法保证原子性,所以需要通过高级语言保证操作的原子性。
有序性
class Instance{
private Instance instance;
public Instance getInstance(){
if(instance == null){
synchronized (Instance.class){
if (instance == null){
instance = new Instance();
}
}
}
return instance;
}
}有序性通过经典的单例模式的双重检测来解释。
线程A获取实例,发现实例为null,则进入同步代码块,进行对象的实例化。
此时,线程B获取实例,发现对象被创建,则直接返回实例。
看似没什么问题,但是了解JVM的同学,会发现其实是存在问题的。
对象的创建分为三步:
分配内存空间
对象初始化
将对象放入申请的内存空间
其实2、3步在单线程下互换顺序是没问题的,也就是这句话(单线程互换没问题),所以JVM在编译代码的时候,会将代码进行优化,只要在单线程下执行结果与先前不变,都可以进行一定的优化(包括调整指令顺序)。如果2、3互换位置,那么此时实例的内存空间是不为null的,如果此时又恰好线程A的时间片执行完了,把CPU资源给了线程B,那线程B此时判断实例不为null了,但是线程A又还没对对象进行初始化,这是线程B返回的对象其实也是一个空对象。这就是典型的有序性问题。可以通过使用volatile防止指令重排来规避这个问题。
以上就是并发下的可见性、原子性、有序性所有的概述,欢迎共勉。