文章目录
- 1、了解程序地址测试代码
- 2、理解程序地址空间
- 3、程序地址空间存在的意义
1、了解程序地址测试代码
1 #include <stdio.h>
2 #include <assert.h>
3 #include <unistd.h>
4
5 int g_value = 100;
6 int main()
7 {
8 pid_t id = fork();
9 assert(id >= 0);
10 if(id == 0)
11 {
12 //child
13 while(1)
14 {
15 printf("我是子进程, 我的id是: %d, 我的父进程是: %d, g_value: %d, &g_value: %p\n", \
16 getpid(), getppid(), g_value, &g_value);
17 sleep(1);
18 }
19 }
20 else
21 {
22 //father
23 while(1)
24 {
25
26 printf("我是父进程, 我的id是: %d, 我的父进程是: %d, g_value: %d, &g_value: %p\n", \
27 getpid(), getppid(), g_value, &g_value);
28 sleep(2);
29 }
30 }
31 }
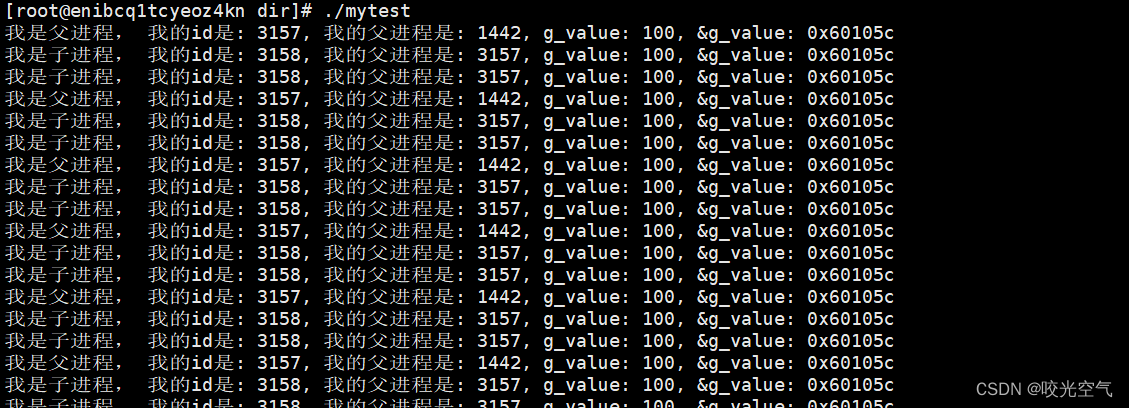
如果在子进程循环里写上g_value++,虽然它是全局变量,但对父进程没有影响。
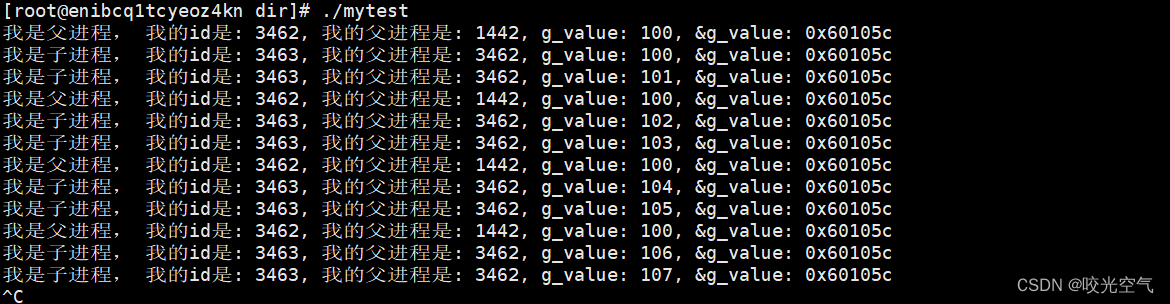
这就是进程具有独立性。之前写过进程 = 内核数据结构 + 代码和数据,两个各自也都有独立性,保证相互独立的做法就是写时拷贝。
再看最后的地址。全都一样。g_value经过写时拷贝会变成两个变量,打印出来的地址应当是不一样的。如果是物理地址,读取同一个变量的地址,那么不会出现不同。子进程对变量进行了修改,但是父进程没有读取到,所以这个地址并不是物理地址。那么现在用的这个地址叫虚拟地址或者线性地址。
2、理解程序地址空间
操作系统会给进程分配好该有的内存量,比如有10g内存,3个进程,分别给他们仨3 3 4g内存。系统要管理进程地址空间,空间本质是一个内核数据结构,struct mm_struct{}。进程在申请空间时,不会之间把所有分配给的空间全要上,只要够这次程序用的空间,如果要得太多,系统也会拒绝。
地址空间会被分成很多区,比如栈区堆区等。所以存入地址空间的数据最终都会进入物理内存中。程序在访问数据时会访问地址空间,用的就是虚拟地址。
==程序地址空间的各个区域如何理解?==区域的划分就是对线性区域进行指定start和end即可完成区域划分。程序地址空间是一个线性区域,从低地址到高地址分布,32位下每个地址是1个字节。这和真实内存一样,32位机器下,CPU访问内存中某个地址或者数据时,会先编址,编成只有0和1,而CPU与内存之间有2的32次方种连接,也就是2的32次方个地址,差不多4G,CPU就需要在这里面寻址,CPU寻址的最小大内单位是1字节。程序地址空间也是如此,地址是连续的,每个都保证了唯一性,所以是线性区域,每个地址所能存储的最大空间是1字节。程序地址空间的地址是从0x全0到0x全F。
一个整数存进去时,占连续的4个字节,而整数的地址就是4个字节中最低的那个地址,数据类型则确定了从这个地址往后读几位。
程序地址空间是一个线性空间,系统对它的大小是早就计算好的,32位和64位的源代码不一样,32位的结构体就直接是4G。空间中每个区域会这样定义:
long code_start
long code_end
long init_start
long init_end
每个区域对应各自的变量名。
如果限定了区域,区域之间的数据就是虚拟地址或者线性地址。
区域的扩大缩小就是修改边界值start和end。
虽然有程序地址空间,但实际上数据只能存在内存中。虚拟地址在系统中会通过页表转为物理地址。
-------------------------------------------------------------
回到刚才的问题,子进程修改数值不影响父进程。父进程和子进程都有各自的地址空间,通过页表连接到物理空间,当子进程想修改数据,内存会给他再申请另一块空间,数据也拷贝过去,子进程就连接到这个新的空间,所以他们的虚拟地址一样,但是连接到物理空间后数值不一样,因为在物理空间中访问的空间不一样。
-------------------------------------------------------------
代码中还有一个问题,为什么if和else都能运行?这是因为fork在返回的时候,父子进程都有了,所以会return两次,id是pid_t类型定义的局部变量,而return的本质,就是在写入,所以谁先返回,谁就会让操作系统发生写时拷贝。
3、程序地址空间存在的意义
如果只有物理内存,那么一个个程序在写入数据时,如果存在越界,或者野指针,那么其他区域的数据就可能被改变了,所以引入地址空间和页表,通过地址空间和页表向物理空间的映射,系统检测映射成功后就可以找到地址和数据。
malloc的本质
malloc申请的时候,返回的也是物理空间上一个堆区的地址,也要通过地址空间和页表。申请并不一定会马上就给空间,而是系统认为你需要才会给你,系统一定要以高效为主。malloc申请空间时,系统开辟空间后,会先进入闲置状态,这时候别人无法用,并且页表也不会去映射,物理内存也没有开辟空间,页表倒是会有虚拟地址。当用户开始写入时,系统就会重新做一遍,把映射加上,物理上开辟空间,用户才能正常用,这就是缺页中断。
地址空间的调整,和页表的连接属于进程管理,页表和物理空间的映射,物理空间的管理属于内存管理。
重新理解地址空间
源代码被编译的时候,会按照虚拟地址空间的方式对代码和数据进行编制,地址空间不仅会影响系统,也会让编译器遵守它的规则。
Linux中可执行程序的格式一般是ELF格式。
读取程序的时候,数据中包含的地址都是虚拟地址,用来更便利地找到相应的物理地址。程序中的地址是虚拟地址,内存中是物理地址。
地址空间和页表存在的意义:
1、防止地址随意访问,保护物理内存与其他进程
2、进程管理和内存管理进行解耦合
3、可以让进程以统一的视角看待自己的代码和数据
结束。





![BUU [ZJCTF 2019]Login](https://img-blog.csdnimg.cn/3fa72c9431b04bbea8243b402f909242.png)
![[极客大挑战 2019]EasySQL 1](https://img-blog.csdnimg.cn/8a69d7cf6b7d4280bb799291661198a9.png)