目录
1--linux报错汇总
1-1 使用 nvcc 命令编译报错
1-2--使用 CMake 编译源码报错
2--源码解读
1--linux报错汇总
1-1 使用 nvcc 命令编译报错
使用 nvcc ./julia_gpu.cu -lglut -lGLU -lGL 运行时,显示 cannot find -lglut 的错误,定位 "gl_helper.h" 时(即下图所示),无法找到 “glut.h”;

解决方法:在 linux 下安装 glut 的开源版本,即 freeglut :
sudo apt-get install build-essential freeglut3 freeglut3-dev binutils-gold安装后,可以在路径 “/usr/include/GL” 找到头文件 glut.h;

测试:重新编译 julia_gpu.cu 文件
nvcc ./julia_gpu.cu -lglut -lGLU -lGL
运行可执行文件 a.out:
./a.out
1-2--使用 CMake 编译源码报错
使用 CMake 编译提供的源码时,出现以下错误:
undefined reference to `glClearColor';
undefined reference to `glClear';
undefined reference to `glDrawPixels';
undefined reference to `glFlush';
解决方法:在 CMakeLists.txt 中增加库的链接:
cmake_minimum_required(VERSION 3.14)
project(Test1 LANGUAGES CUDA) # 添加支持CUDA语言
add_executable(main julia_gpu.cu)
target_link_libraries(main -lglut -lGLU -lGL)测试:运行可执行文件 main:
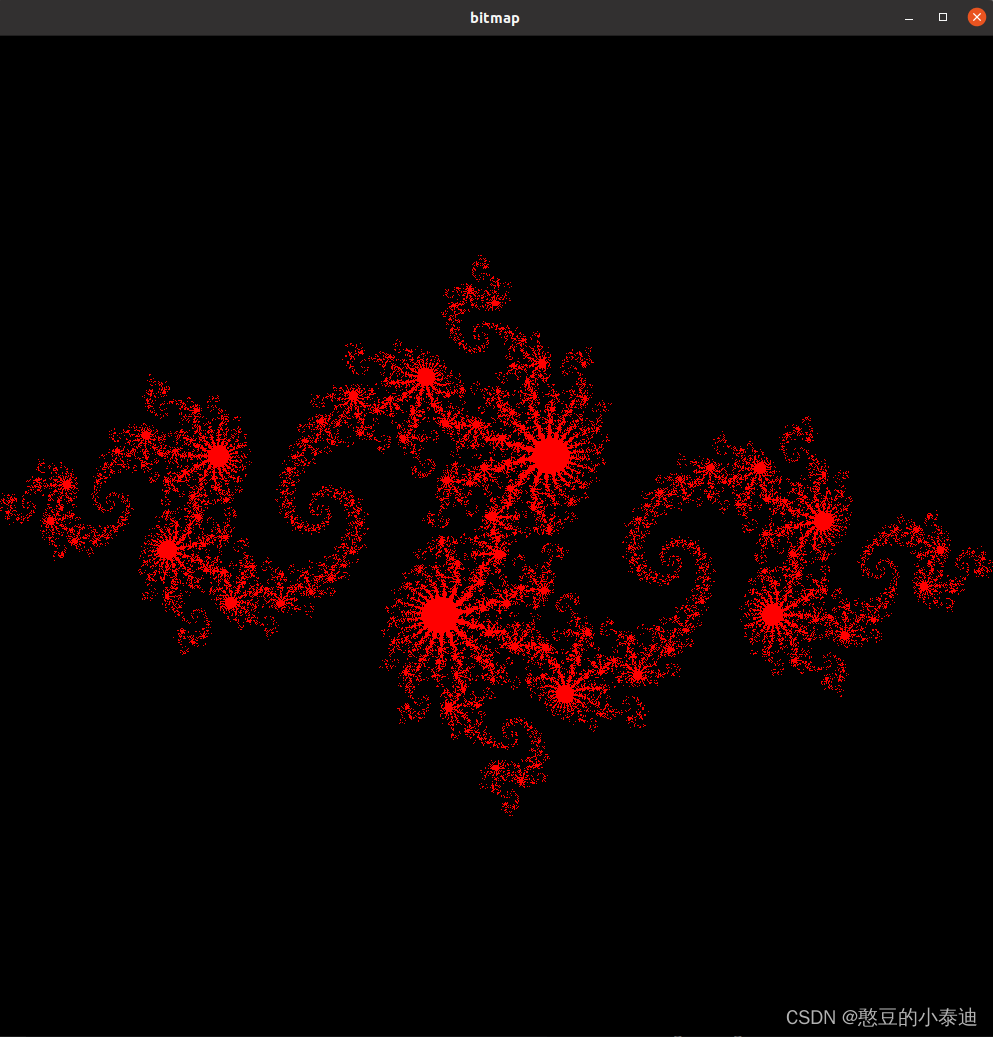
2--源码解读
#include "./common/book.h"
#include "./common/cpu_bitmap.h"
#define DIM 1000
struct cuComplex {
float r;
float i;
__device__ cuComplex( float a, float b ) : r(a), i(b) {}
__device__ float magnitude2( void ) {
return r * r + i * i;
}
__device__ cuComplex operator*(const cuComplex& a) {
return cuComplex(r*a.r - i*a.i, i*a.r + r*a.i);
}
__device__ cuComplex operator+(const cuComplex& a) {
return cuComplex(r+a.r, i+a.i);
}
};
// 判断点(x, y)是否属于 julia 集
__device__ int julia( int x, int y ) {
const float scale = 1.5;
float jx = scale * (float)(DIM/2 - x)/(DIM/2);
float jy = scale * (float)(DIM/2 - y)/(DIM/2);
cuComplex c(-0.8, 0.156);
cuComplex a(jx, jy);
int i = 0;
for (i=0; i<200; i++) {
a = a * a + c;
if (a.magnitude2() > 1000)
return 0;
}
return 1;
}
__global__ void kernel( unsigned char *ptr ) {
// 在声明二维线程格时,线程格每一维的大小与图像每一维的大小相等
// 则(0, 0)和(DIM-1, DIM-1)之间每个像素点(x, y)都能获得一个线程块
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x; // 行索引 y 乘以线程块宽度 gridDim.x,再加上列索引 x,得到每一个(x, y)的指针索引
int juliaValue = julia( x, y ); // 判断点(x, y)是否属于julia集
ptr[offset*4 + 0] = 255 * juliaValue;
ptr[offset*4 + 1] = 0;
ptr[offset*4 + 2] = 0;
ptr[offset*4 + 3] = 255;
}
int main( void ) {
CPUBitmap bitmap(DIM, DIM); // 创建位图图像
unsigned char *dev_bitmap; // 创建指针,申请GPU内存
HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap, bitmap.image_size() ) );
dim3 grid(DIM,DIM); // 用于指定启动的线程块数量,这里用到的是二维线程格
kernel<<<grid,1>>>( dev_bitmap ); // 执行定义的核函数,计算julia集
HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(), dev_bitmap,
bitmap.image_size(),
cudaMemcpyDeviceToHost ) ); // 将计算结果从 device 传递到 host
HANDLE_ERROR( cudaFree( dev_bitmap ) ); // 释放在 GPU 申请的内存
bitmap.display_and_exit(); // 可视化位图
}
核心代码分析:
dim3 grid(DIM,DIM); // 用于指定启动的线程块数量,这里用到的是二维线程格代码创建了一个二维线程格,其维度大小为 (DIM, DIM),即共有 DIM*DIM 个线程块,每一个线程块对应一个位图像素点(x, y),用于计算其是否属于 julia 集;
__global__ void kernel( unsigned char *ptr ) {
// 在声明二维线程格时,线程格每一维的大小与图像每一维的大小相等
// 则(0, 0)和(DIM-1, DIM-1)之间每个像素点(x, y)都能获得一个线程块
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x; // 行索引 y 乘以线程块宽度 gridDim.x,再加上列索引 x,得到每一个(x, y)的指针索引
int juliaValue = julia( x, y ); // 判断点(x, y)是否属于julia集
ptr[offset*4 + 0] = 255 * juliaValue;
ptr[offset*4 + 1] = 0;
ptr[offset*4 + 2] = 0;
ptr[offset*4 + 3] = 255;
}使用__global__声明核函数,gridDim 是一个常数用于保存线程格每一维的大小;由于每一个线程块对应一个像素点,则可以通过 x + y * gridDim.x 计算每一个像素点相应的偏移量;
kernel 函数是这个例子并行计算的核心代码,通过为每一个像素点分配一个线程块,通过并行计算快速判断每一个像素点是否属于 julia 集,无需在CPU中通过循环每次只能判断一个像素点 (x, y);