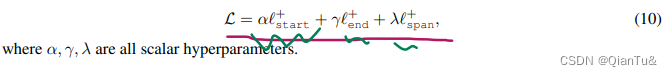A continual learning-guided training framework for pansharpening
(一种持续学习引导的全色锐化训练框架)
基于监督学习的全色锐化方法自出现以来一直受到批评,因为它们依赖于尺度移位假设,即这些方法在降低分辨率时的性能通常比在全分辨率时好得多。为了解决这个问题,本文提出了一个基于监督学习的全色锐化的通用训练框架。我们的培训过程包括两个阶段:第一阶段是传统的监督方法,其应用于降低的分辨率数据集以获得收敛模型,而在第二阶段中,通过无监督学习方案训练从阶段一获得的模型。此外,我们开发了一个新的损失函数,由两项组成,保证模型在降低和全分辨率下的高性能。此外,我们开发了一个新的损失函数,由两项组成,以保证模型在降低和全分辨率下的高性能。据我们所知,这是第一次尝试将持续学习的概念引入到全色化中。该框架具有通用性,可应用于任何基于监督学习的全色锐化网络。此外,所提出的方法对于用于提供待融合数据的卫星传感器的改变表现出鲁棒性。
介绍
大多数光学卫星传感器产生全色(PAN)和多光谱(MS)图像,它们提供同一场景的冗余、互补和协作信息。术语全色锐化指的是聚合互补信息以作为最终结果递送具有MS图像的光谱分辨率和PAN图像的空间分辨率的图像的融合方法。新的高质量全色锐化图像允许获得更准确和全面的地球观测和更广泛的应用。
由于遥感数据的数量和多样性不断增加,加上越来越高的应用要求,全色化是一个具有挑战性的领域,许多问题尚未解决。在过去的三十年中,开发了大量的全色锐化技术。最常用的技术分为三大类:(i)组件替代(CS)方法;(ii)多分辨率分析(MRA)方法;(iii)基于变分优化(VO)的技术。
CS由于其简单的实现和低的计算成本而被遥感界广泛使用。该方法的主要特征在于将MS图像变换到特定域中,其中结构成分被空间丰富的PAN图像替代或部分替代。然后应用逆变换以获得期望的锐化图像。强度-色调-饱和度(IHS)、主成分分析(PCA)、Brovey和Gram-Schmidt(GS)是属于CS家族的先驱方法。这些较早的方法在保留空间细节以及它们对空间失准的鲁棒性方面实现了最高性能。由于这些原因,CS技术被广泛研究。最近,出现了许多改进的CS方法,如部分替换自适应CS(PRACS),基于Brovey变换的雾度校正方法(BT-H)、频带相关空间细节注入方法(BDSD)及其不同的变体。
相反,MRA方法与CS不同,从空间角度解决全色化。基于MRA的方法的基本假设是缺乏的空间细节位于PAN图像的高频部分。通过多分辨率分析,从高分辨率PAN图像中提取高频信息,并注入到MS波段。
基于VO的方法是近年来兴起的一种新方法,其特点是对表示模型进行变分优化。这一类别下的方法通常表示为解释模型,其中观察到的PAN和MS图像被视为理想高分辨率MS图像的降级版本。高质量图像可以通过优化算法来恢复。此类中的代表性方法包括SR-D(基于稀疏表示,基于注入细节的稀疏表示的全色锐化)、PWMBF(基于贝叶斯、使用PCA和小波的基于模型的融合)、RR(基于模型的降秩全色锐化)、VP-Net和VO + Net。
由于实现卷积神经网络(CNN)所获得的巨大优势,深度学习在不同的研究领域中带来了优异的性能,激励遥感社区研究人员开发依赖于深度学习技术的全色锐化方法。据我们所知,Masi等人率先在全色锐化中使用全卷积神经网络,取得了最先进的结果。此后,深度学习(DL)技术已广泛用于全色锐化域。最近,Transformer成为一个值得注意的新趋势,引起了泛锐化社区的关注。Zhou等人迈出了将Transformer技术应用于全色锐化任务的第一步。其他一些研究遵循这一研究路线,提出了许多代表性的方法,甚至解决了高光谱和多光谱图像融合问题。
相对于传统方法,基于DL的方法成为最流行的方法,提供了更好的空间和光谱信息保存。然而,主要问题与以下事实有关:对于共同监督训练,没有地面实况图像。作为替代方案,遵循Wald方案,原始PAN-MS图像对被降级并用作输入样本,而原始MS图像被视为地面实况。按照这种方法,在完全监督框架下训练网络,尽管是在降低的分辨率域中。然后,将收敛后的模型应用于原始全分辨率PAN-MS数据的融合。显然,该解决方案基于这样的假设,即在低分辨率下训练的网络将在更高分辨率下表现得同样好,就好像它已经在更高分辨率的数据上训练过一样(尺度不变性假设)。这一假设绝非显而易见。因此,基于监督学习的方法有时在降低分辨率域表现良好,而在目标全分辨率域表现较差。
为了克服与尺度不变性相关的问题,Vitale和Scarpa设计了一种包含降低分辨率和全分辨率图像的新型损失函数。该网络是在一个充分监督的框架下培训的。对于降低的分辨率损失项,选择原始MS图像作为地面实况,对于另一项,选择具有高通调制注入模型的MTF-GLP(MTF-GLP-HPM)的输出的方法,作为参考。尽管非常创新,该算法性能不是令人满意的。首先,空间保存不能比辅助MTF-GLP-HPM算法。其次,小全分辨率的改善领域得到失去质量在降低分辨率域。Shen等人提出了一种双输出上,跨策略来克服相同的问题,但计算效率较低的费用。PancolorGAN采用了随机下采样方法,使模型对物体大小的变异性更具鲁棒性。然而,随机下采样仅适用于基于监督学习的方法,其中训练在降低分辨率的数据集上执行。当该方法基于无监督学习时,随机下采样可能不适用。
Ciotola等人最近也提出了一个基于DL的全色锐化的全分辨率框架,提供了一个很好的解决方案。Luo等人采用了完全无监督的方法,避免了尺度不变假设。然而,这种方法严重依赖于一个相当复杂的损失函数,其中包括一个欧几里得范数项,一个结构一致性项,和一个无参考质量项。UPSAM也遵循了基于CNN的无监督框架的齐次方案,并依赖于相当复杂的损失函数。此外,PanGan)、PGMAN、PercepPAN和UCGAN建立了基于生成对抗网络(GANs)的无监督架构以避免尺度移位假设。UPanGAN采用了一种由光谱和纹理损失函数约束的迭代无监督全色锐化GAN模型。他们的创新公式是成功的,并且在高分辨率域上具有良好的性能,然而,GANs的训练过程是脆弱的,容易导致较差的结果。此外,用于空间结构损失概念的假设不够可靠。
这些宝贵方法的缺点可归纳如下:
1)有的严重依赖于相当复杂的损失函数或训练过程敏感;
2)对于其中的大多数,损失函数是否可以推广到不同的网络架构尚不清楚;
3)虽然很多注意力集中在全分辨率域,但分辨率降低的情况通常会被忽略。
为了克服上述问题,我们提出了一个通用的训练框架,为全色锐化配备了一个非常简单的无参考质量损失函数。具体而言,培训包括两个阶段:在第一阶段中,执行常规的监督训练。在第二阶段,采用无人监督的培训:实现损失函数以提高高分辨率域上的性能并使降低分辨率域中的质量降级最小化。值得注意的是,该通用训练框架可以应用于各种基于监督学习的全色锐化架构。
贡献
1)提出了一种通用的全色锐化训练框架,可以应用于任何基于监督学习的体系结构;
2)基于连续学习思想,构造了一种新的损失函数,保证了降维和全分辨率域的性能;
3)在几个典型数据集上对三种经典的基于DL的全色锐化结构进行了大量实验,实验结果验证了所提框架的有效性和优越性。
Background and motivation
为了解决与尺度不变假设相关的问题,文献中提供了以下方法:(i)基于监督学习的方法;(ii)基于无监督学习的方法。第一类指的是在全分辨率下使用未知地面事实的代理,通过简单的欧几里得距离作为损失函数来测量相似性。然而,全分辨率性能的改进并不那么显著。第二种方法在目标分辨率方面有了很大的改进,但损失函数相当复杂和敏感,而且分辨率降低时会损失精度。这两种方法具有互补和合作的特点。在这份手稿中,我们开发了一种将两者结合使用的方法。
在实际应用中,我们要处理多个学习任务。一般而言,单个模型容易遭受来自先前学习任务的灾难性遗忘问题。要克服这一问题,可以实行多任务联合训练。然而,该解决方案在存储和计算时间方面要求很高。因此,最好的替代选择是实施持续学习战略。
为了克服灾难性遗忘,许多连续学习方法被开发出来。它们分为三类:排练机制、迁移学习方法和参数正则化方法。与前两种方法相比,参数正则化更具成本效益,因此得到了更广泛的应用,因为它通过正则化对网络中的参数权重施加一些约束来解决灾难性遗忘。EWC(elastic weight consolidation)和LWF(learning without forgetting)代表了两种最常用的参数正则化方法。EWC定量评估每个参数对任务的重要程度。然后,关键参数被设置为具有较高权重以防止在新任务期间被训练时被更新,而较不重要的参数将更容易被修改以从新任务中学习。与EWC不同的是,LWF采用了一种整体约束的方法来防止遗忘从旧任务中学习到的知识。详细地说,除了对新数据的新任务的约束之外,LWF最小化更新的模型对新数据的旧任务的输出与原始模型对新数据的旧任务的输出之间的损失。这样,LWF能够在为新任务更新时防止从旧模型获得的权重的大的变化,因此可以缓解灾难性遗忘问题。
早期,持续学习主要应用于图像分类任务,并逐渐扩展到其他视觉领域。例如,Xu等人采用序贯训练的方式训练单个模型完成多个融合任务(包括多模态图像融合、多曝光图像融合和多聚焦图像融合),其中只需要存储当前任务的数据。为了克服遗忘问题,采用了EWC算法,取得了满意的结果。Le等人提出了一种用于统一图像融合的无监督连续学习生成对抗网络,并使用EWC避免灾难性遗忘。Zhou等人提出了一种基于一阶和二阶参数重要性指导的权值修正方法,并将其应用于去训练任务。
与传统的将全色化描述为单个任务的观点不同,在本文中,我们重新阐述了将全色化问题分解为两个任务:降低分辨率融合任务和全分辨率融合任务。然后,在连续学习框架下应用全色锐化,采用合适的连续学习方法来提高单个模型的性能。然后,在连续学习框架下应用全色锐化,采用合适的连续学习方法来提高单个模型的性能。理论上,有很多可供选择的连续学习方法用于全色锐化,但是,为了优化计算时间和存储空间,我们使用LWF算法依次执行这两个子任务,以避免遗忘问题。具体地,针对第一任务(所谓的降低分辨率数据融合)训练模型,然后针对第二任务(所谓的全分辨率数据融合)顺序地训练模型。对于第二个任务,除了对全分辨率数据融合的约束之外,我们还约束新数据(即全分辨率数据)上的新模型的输出与原始模型(第一个任务之后的收敛模型)的输出之间的距离。通过这种方式,我们保证了在执行第二个任务时模型在第一个任务上的性能。利用该方法,则可以获得在降低的分辨率图像和全分辨率图像上都具有非常好的性能的单个模型。
方法
Overview
在本节中,𝑃和𝑀将分别表示PAN和MS图像。分辨率级别由下标指示,其中0表示最高空间分辨率。不同分辨率的图像是使用恒定分辨率获得的𝑅,每个图像表示为𝑛和𝑛+1𝑛。从最初可用的𝑃0和𝑀1,本方法的目标是获得理想但未知的较高分辨率MS图像𝑀0。拟议框架的概要见图1。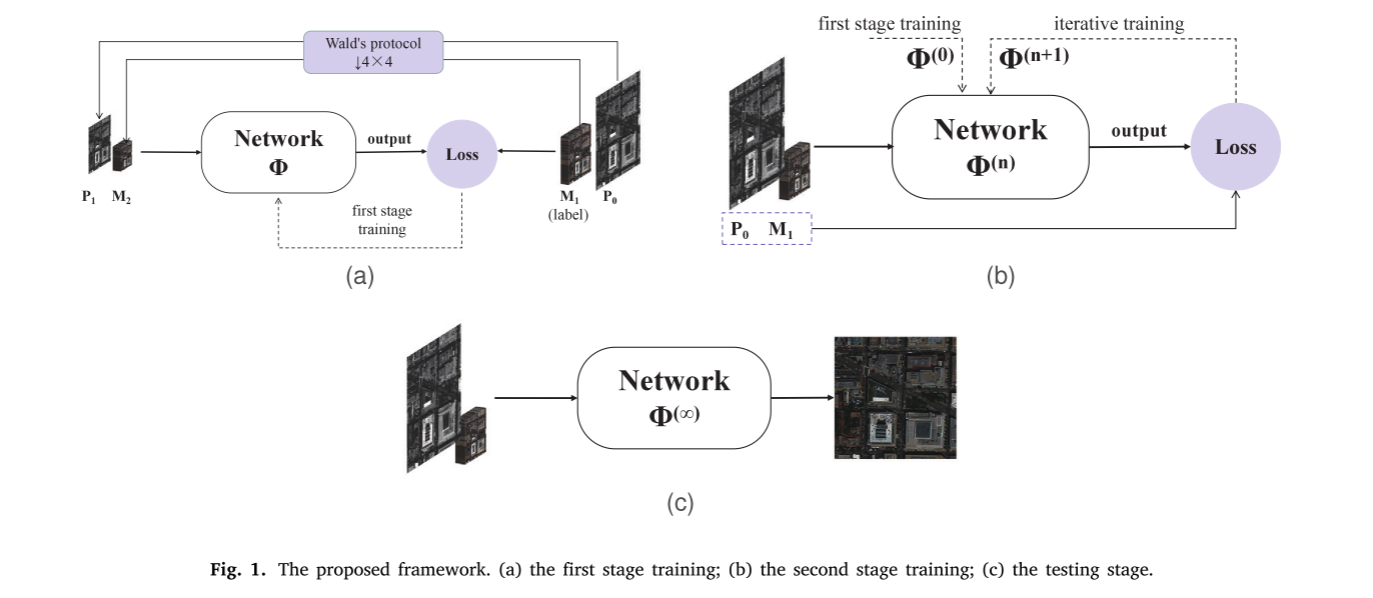
培训过程包括两个连续的阶段。如图1(a)所示,在第一阶段,以监督学习方式在分辨率降低的图像上训练网络,其中𝑃1和𝑀2用作输入图像,𝑀1用作地面实况。为方便起见,我们分别使用𝛷和𝛷(0)来表示网络和收敛模型。在第二阶段,如图1(b)所示,我们继续使用前一阶段的结果训练相同的网络,但不同的是,现在使用以无监督的方式在全分辨率下执行训练过程𝑃0和𝑀1。与第一阶段不同的是,我们用 𝛷(𝑛)表示网络,用𝛷(∞)表示收敛模型。一旦完成两个阶段的训练,网络参数被优化并应用于随后的评估,如图1(c)所示。
该方法可以应用于现有的监督式全色锐化方法(基于CNN或基于GAN)。这项工作的主要目标是设计第二阶段应用的损失函数,而不是网络体系结构。在基于GAN的架构的情况下,仅收敛的生成器(没有鉴别器)涉及到第二训练阶段。
Loss function
在第二训练阶段期间应用的损失函数由两项组成,如(1)中所示,将它们与两个加权系数𝛼和𝛽组合。第一项𝐿𝑜𝑠𝑠𝑛𝑒𝑤是新任务优化(全分辨率下的融合质量),另一项𝐿𝑜𝑠𝑠𝑟𝑒𝑔是用于保持旧任务性能的正则化项(即,在降低的分辨率下的融合质量):
对于公式(1)中的第一项,我们引入无参考损耗,在我们的实验中,广泛使用(用于测量全分辨率下的性能)的无参考质量(QNR)指数,表示为𝑄𝑁𝑅(⋅,⋅,⋅),公式如下: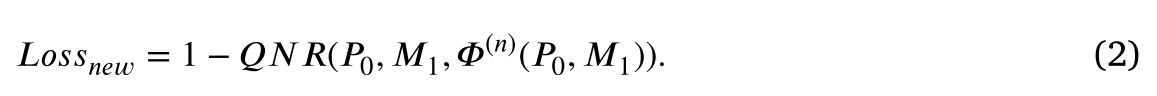
第二项可以定义为:
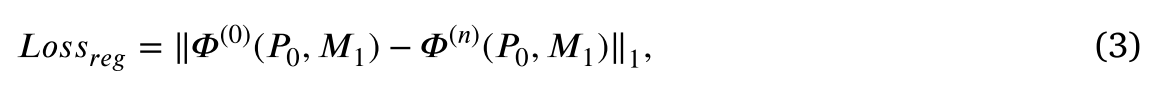
其中𝛷(0)表示第一训练阶段之后的收敛模型。这一项限制了应用新模型(𝛷(𝑛))的新数据融合结果与旧模型(𝛷(0))的结果相匹配。换句话说,新模型的结果应尽可能接近旧模型的结果。这也意味着新模型在旧数据上的性能与旧模型不会有太大差别。因此,该正则化项避免了新模型在旧(降低的分辨率)任务上的性能降级。
通常,我们假设两个损失函数项表示两个相反方向上的优化。为此,我们必须通过对这两项任务进行线性加权求和来取得平衡。例如,如果𝛼设置为0,则仅应用调节项。这意味着新任务不会优化模型。否则,如果𝛽= 0,则相反,即,将仅使用新任务。
这意味着,在上述两种情况下,将分别实现降低分辨率数据和全分辨率数据的最佳性能。然而,新旧任务高度相关,可能相辅相成。
Characteristics of the proposed approach
存在两种类型的方法来解决由分辨率偏移引起的问题。CTACNN代表第一种类型,即基于监督学习的方法。该方法的特征在于一个精细调整步骤,在该步骤中,跨尺度损失函数被公式化,并且包括降低的分辨率和全分辨率图像。此外,在监督学习过程中,CTACNN必须与辅助MTF-GLP-HPM算法协调以生成全分辨率的伪标签。通常,该任务是复杂的并且构造具有高计算成本。此外,在全分辨率下获得微小的改进,但在降低的分辨率下性能下降。不同的是,我们的方法在第二训练步骤中只涉及全分辨率图像,这大大降低了计算成本。
对于第二种类型的方法,即基于无监督学习的方法,应用完全无监督的方法,基于CNN或GAN,与设计良好但通常相当复杂的损失函数配对。这种类型的方法在全分辨率下表现出非常高的性能,但是在降低的分辨率下会损失质量。此外,复杂的损失函数也给系统带来了更大的灵敏度,增加了陷入局部最小值的风险。我们的方法改为在第二个训练步骤中使用与正则化项配对的简单QNR损失项。
最后,应评估该方法对网络结构变化的敏感程度。特别是,如果网络的架构被替换,设计良好的损失函数是否会起到同样的作用?换句话说,不能保证通用性。相反,我们的方法论独立于具体的架构,并通过新颖的训练框架不断提高效果。