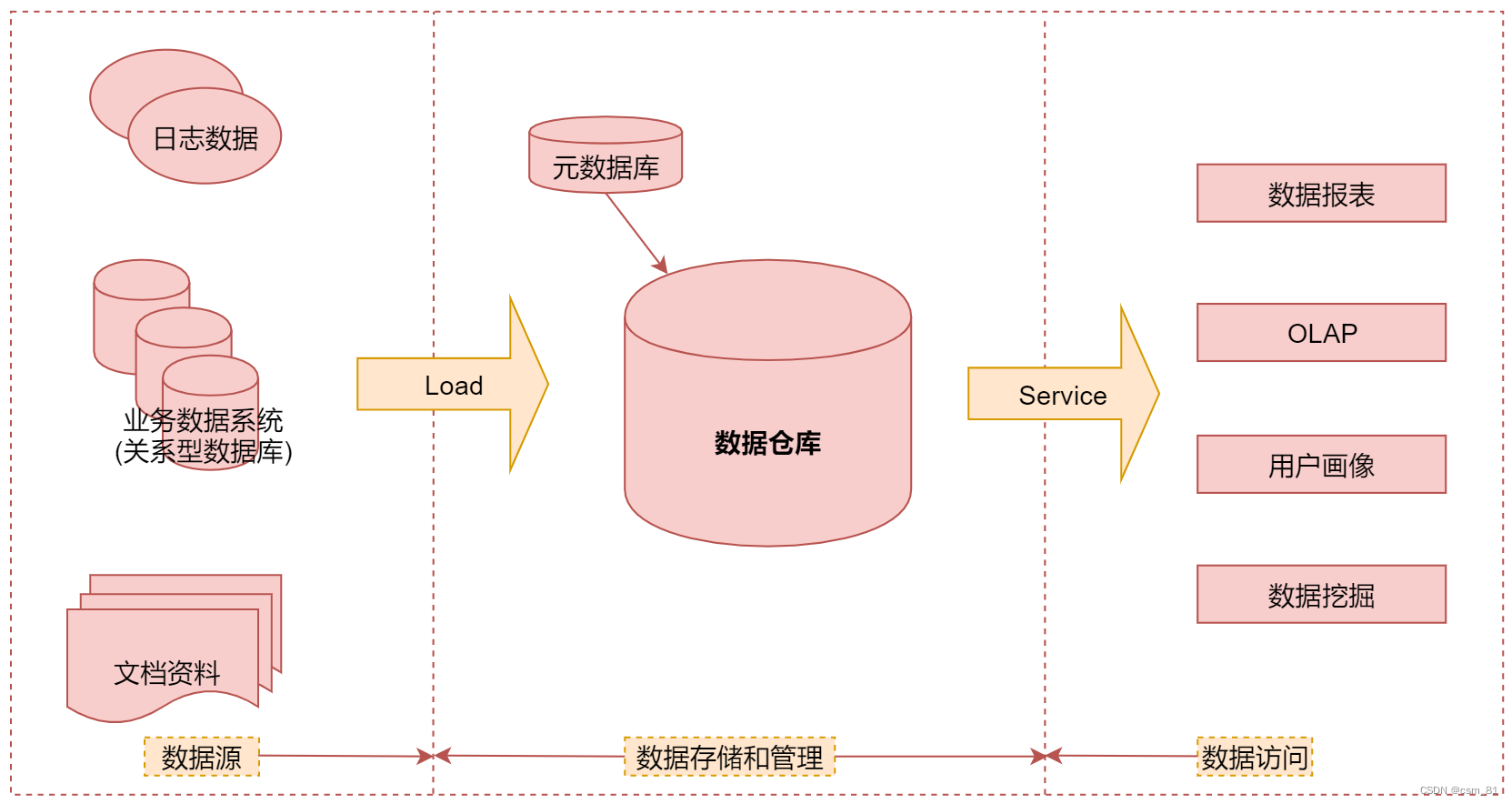
C++内存分布
我们先来看一下下面的一段代码相关问题
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = {1, 2, 3, 4};
char char2[] = "abcd";
char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof (int)*4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int)*4);
free (ptr1);
free (ptr3);
}
1. 选择题:
选项: A.栈 B.堆 C.数据段 D.代码段
globalVar在哪里?__c__ staticGlobalVar在哪里?__c__
staticVar在哪里?__c__ localVar在哪里?__a__
num1 在哪里?__a__
char2在哪里?__a__ *char2在哪里?__d__
pChar3在哪里?__a__ *pChar3在哪里?__d__
ptr1在哪里?__a__ *ptr1在哪里?__b__
2. 填空题:
sizeof(num1) = __40__;
sizeof(char2) = __5__; strlen(char2) = __4__;
sizeof(pChar3) = __8__; strlen(pChar3) = __4__;
sizeof(ptr1) = __8__;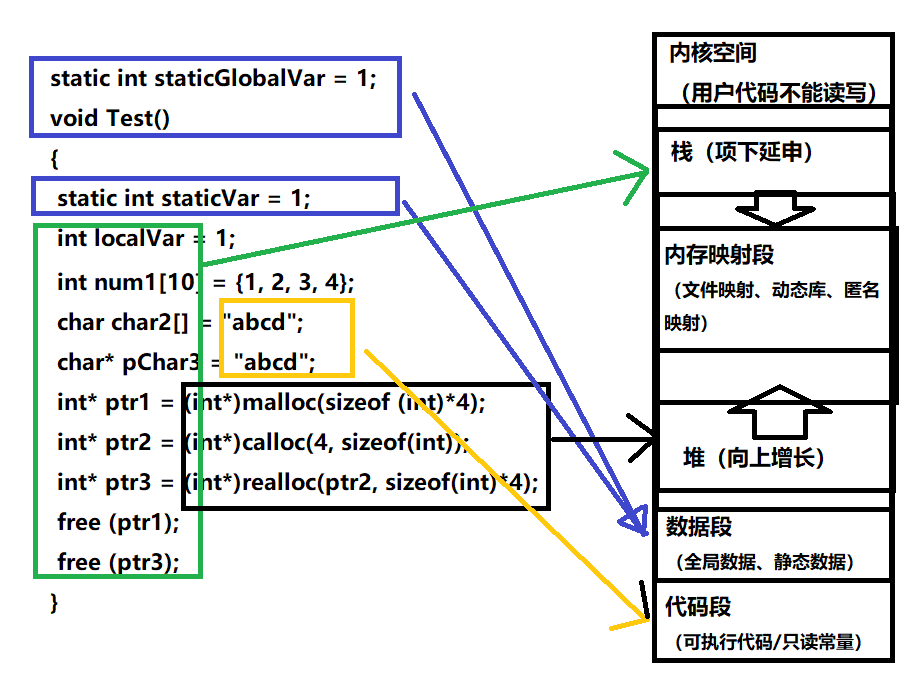
【说明】
堆又叫堆栈,非静态局部变量/函数参数/返回值等等,栈是向下增长的。
内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。(Linux课程如果没学到这块,现在只需要了解一下)。
堆用于程序运行时动态内存分配,堆是可以上增长的。
数据段--存储全局数据和静态数据。
代码段--可执行的代码/只读常量。
C语言当中动态内存管理方式
malloc/calloc/realloc/free
void Test ()
{
int* p1 = (int*) malloc(sizeof(int));
free(p1);
// 1.malloc/calloc/realloc的区别是什么?
int* p2 = (int*)calloc(4, sizeof (int));
int* p3 = (int*)realloc(p2, sizeof(int)*10);
// 这里需要free(p2)吗?
free(p3 );
}【面试题分享】
malloc/calloc/realloc的区别?
C++内存管理方式
C语言内存管理方式在C++当中可以继续使用,但是有些地方就无能为力而且使用起来比较繁琐,因此C++又提出了自己的内存管理方式:通过new和delete操作符来进行动态内存管理。
new/delete操作内置类型
void Test()
{
// 动态申请一个int类型的空间
int* ptr4 = new int;
// 动态申请一个int类型的空间并初始化为10
int* ptr5 = new int(10);
// 动态申请10个int类型的空间
int* ptr6 = new int[10];
delete ptr4;
delete ptr5;
delete[] ptr6;
}
【注意】申请和释放单个元素的空间,使用new和delete操作符,申请和释放连续的空间,使用new[]和delete[]。
new和delete操作自定义类型
class Test
{
public:
Test()
: _data(0)
{
cout<<"Test():"<<this<<endl;
}
~Test()
{
cout<<"~Test():"<<this<<endl;
}
private:
int _data;
};
void Test2()
{
// 申请单个Test类型的空间
Test* p1 = (Test*)malloc(sizeof(Test));
free(p1);
// 申请10个Test类型的空间
Test* p2 = (Test*)malloc(sizoef(Test) * 10);
free(p2);
}
void Test2()
{
// 申请单个Test类型的对象
Test* p1 = new Test;
delete p1;
// 申请10个Test类型的对象
Test* p2 = new Test[10];
delete[] p2;
}【注意】
在申请自定义类型的空间时,new会调用构造函数,delete会调用析构函数,而malloc和free不会。
operator new与operator delete函数(重要)
operator new与operator delete函数(重点)
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间。
/*
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间失败,
尝试执行空 间不足应对措施,如果改应对措施用户设置了,则继续申请,否则抛异常。
*/
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{
// try to allocate size bytes
void *p;
while ((p = malloc(size)) == 0)
if (_callnewh(size) == 0)
{
// report no memory
// 如果申请内存失败了,这里会抛出bad_alloc 类型异常
static const std::bad_alloc nomem;
_RAISE(nomem);
}
return (p);
}
/*
operator delete: 该函数最终是通过free来释放空间的
*/
void operator delete(void *pUserData)
{
_CrtMemBlockHeader * pHead;
RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));
if (pUserData == NULL)
return;
_mlock(_HEAP_LOCK); /* block other threads */
__TRY
/* get a pointer to memory block header */
pHead = pHdr(pUserData);
/* verify block type */
_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));
_free_dbg( pUserData, pHead->nBlockUse );
__FINALLY
_munlock(_HEAP_LOCK); /* release other threads */
__END_TRY_FINALLY
return;
}
/*
free的实现
*/
#define free(p) _free_dbg(p, _NORMAL_BLOCK)通过上述两个全局函数的实现知道,operator new 实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete 最终是通过free来释放空间的。
operator new与operator delete的类专属重载(了解)
下面代码演示了,针对链表的节点ListNode通过重载类专属 operator new/ operator delete,实现链表节点使用内存池申请和释放内存,提高效率。
struct ListNode
{
ListNode* _next;
ListNode* _prev;
int _data;
void* operator new(size_t n)
{
void* p = nullptr;
p = allocator<ListNode>().allocate(1);
cout << "memory pool allocate" << endl;
return p;
}
void operator delete(void* p)
{
allocator<ListNode>().deallocate((ListNode*)p, 1);
cout << "memory pool deallocate" << endl;
}
};
class List
{
public:
List()
{
_head = new ListNode;
_head->_next = _head;
_head->_prev = _head;
}
~List()
{
ListNode* cur = _head->_next;
while (cur != _head)
{
ListNode* next = cur->_next;
delete cur;
cur = next;
}
delete _head;
_head = nullptr;
}
private:
ListNode* _head;
};
int main()
{
List l;
return 0;
}new和delete的实现原理
内置类型
如果申请的是内置类型的空间,new和malloc,delete和free基本类似,不同的地方是:new/delete申请和释放的是单个元素的空间,new[]和delete[]申请的是连续空间,而且new在申请空间失败时会抛异常,malloc会返回NULL。
自定义类型
new的原理
1. 调用operator new函数申请空间
2. 在申请的空间上执行构造函数,完成对象的构造
delete的原理
1. 在空间上执行析构函数,完成对象中资源的清理工作
2. 调用operator delete函数释放对象的空间
new T[N]的原理
1. 调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
2. 在申请的空间上执行N次构造函数
delete[]的原理
1. 在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
2. 调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释放空间
定位new表达式(placement-new)
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
使用格式:
new (place_address) type或者new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
使用场景:
定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new的定义表达式进行显示调构造函数进行初始化。
class Test
{
public:
Test()
: _data(0)
{
cout<<"Test():"<<this<<endl;
}
~Test()
{
cout<<"~Test():"<<this<<endl;
}
private:
int _data;
};
void Test()
{
// pt现在指向的只不过是与Test对象相同大小的一段空间,还不能算是一个对象,因为构造函数没有执行
Test* pt = (Test*)malloc(sizeof(Test));
new(pt) Test; // 注意:如果Test类的构造函数有参数时,此处需要传参
}常见面试题
malloc/free和new/delete的区别
mallo/free和new/delete的共同点:
都从堆上申请空间,并且需要用户手动释放。
不同点:
1.malloc和free是函数,new和delete是操作符;
2.malloc申请的空间不会初始化,new可以初始化;
3.malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间类型就行;
4.malloc的返回值为void*,在使用时必须强转,new不需要,因为new后跟的是控件类型;
5.malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常;
6.申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造析构函数,而new会在申请空间后调用构造函数完成对对象的初始化,delete在释放空间钱会调用析构函数完成空间中资源的清理。
内存泄露
1.什么是内存泄漏:
内存泄漏指因为疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并不是指内存在物理上的消失,而是应用程序分配某段内存后,因为设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
2.内存泄露的危害:
长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死。
3.内存泄漏的分类(了解):
堆内存泄漏(heap leak):
堆内存指的是程序执行中依据须要分配通过malloc / calloc / realloc / new等从堆中分配的一块内存,用完后必须通过调用相应的 free或者delete 删掉。假设程序的设计错误导致这部分内存没有被释放,那么以后这部分空间将无法再被使用,就会产生Heap Leak。
系统资源泄漏:
指程序使用系统分配的资源,比方套接字、文件描述符、管道等没有使用对应的函数释放掉,导致系统资源的浪费,严重可导致系统效能减少,系统执行不稳定。
3.如何避免内存泄漏:
工程前期良好的设计规范,养成良好编码规范,申请内存空间记得匹配的去释放;
采用RAII思想或者智能指针来管理资源;
有些公司内部规范使用内部实现的私有内存管理库,这套库自带内存泄露检测的功能选项;
出问题了使用内存泄露工具检测。
4.总结:
内存泄漏非常常见,解决方案分为两种:
一是事前预防型,如智能指针等;二是事后差错型,如泄漏检测工具。
如何一次在堆上申请4G的内存
// 将程序编译成x64的进程,运行下面的程序试试?
#include <iostream>
using namespace std;
int main()
{
void* p = new char[0xfffffffful];
cout << "new:" << p << endl;
return 0;
}泛型编程
如何实现一个通用函数的交换呢?
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
......虽然函数重载可以实现,但是有以下几个不好的地方:
重载的函数仅仅是类型不同,代码的复用率比较低,只要有新类型出现,就需要增加对应的函数;
代码的维护性可能比较低,一个出错所有重载均出错!
那么能都告诉编译器一个模子,让编译器根据不同类型利用这个模子来生成代码呢?
如果在C++中也能够存在这样一个模子,通过给这个模子不断填充不同材料(类型),来获得不同的成品(生成具体类型的代码),那将会节省许多头发,巧的是前人早已将树栽好。
函数模板
函数模板的概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参型产生函数的特定类型版本。
函数模板格式
template<typename T1,typename T2, ... ... ,typename Tn>
返回值类型 函数名(参数列表){}
template<typename T>
void Swap( T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}注意:typrname是用来定义模板参数的关键字,也可以使用class(切记:不能使用struct代替class)
函数模板原理
函数模板是一个蓝图,它本身并不是函数,是编译器有使用方式生产特定具体类型函数的模具,所以其实模板就是将本来应该我们做的重复的事情交给了编译器。
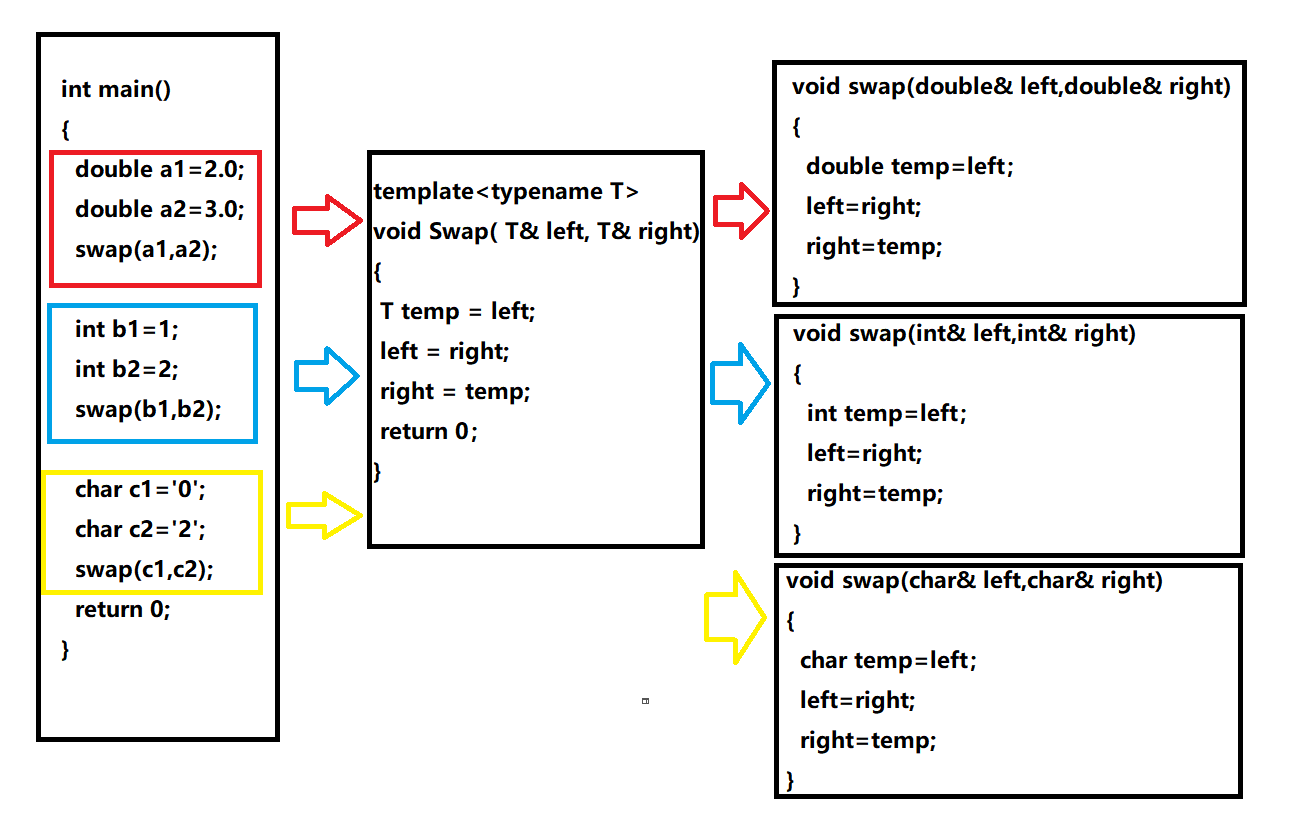
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
函数模板的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
/*
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
Add(a1, d1);
*/
// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
Add(a1, (int)d1);
return 0;
}显式实例化:在函数名后的<>中指定模板参数的实际类型
int main(void)
{
int a = 10;
double b = 20.0;
// 显式实例化
Add<int>(a, b);
return 0;
}如果类型不匹配,编译器会尝试进行隐式转换,如果无法转换成功就会报错。
模板参数的匹配原则
1、一个非模板函数可以和一个同名的函数模板同时存在,而且改模板函数还可以被实例化这个非模板函数:
// 专门处理int的加法函数
int Add(int left, int right)
{
cout << "非模板" << endl;
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
cout << "模板" << endl;
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}2、对于非模板函数和同名函数模板,如果其他条件都相同,会在调用时优先调用非模板函数,而不会从模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数,那么将选择模板。
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}3、模板函数不允许自动类型转换,但普通函数可以进行自动类型转换。
类模板
类模板的定义格式
template<class T1, class T2, ..., class Tn>
class 类模板名
{
// 类内成员定义
}; // 动态顺序表
// 注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
template<class T>
class Vector
{
public :
Vector(size_t capacity = 10): _pData(new T[capacity]), _size(0), _capacity(capacity)
{}
// 使用析构函数演示:在类中声明,在类外定义。
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size() {return _size;}
T& operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
}
private:
T* _pData;
size_t _size;
size_t _capacity;
};
// 注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template <class T>
Vector<T>::~Vector()
{
if(_pData)
delete[] _pData;
_size = _capacity = 0;
}类模板的实例化
类模板的实例化与函数模板实例化不同,类模板实例化需要在类模板名字后面跟<>,然后将实例化放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
// Vector类名,Vector<int>才是类型
Vector<int> s1;
Vector<double> s2;非类型模板参数
模板参数分类类型形参与非类型形参
类型形参即:出现在模板参数列表中,跟class或者typename之类的参数类型名称。
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
namespace bite
{
// 定义一个模板类型的静态数组
template<class T, size_t N = 10>
class array
{
public:
T& operator[](size_t index){return _array[index];}
const T& operator[](size_t index)const{return _array[index];}
size_t size()const{return _size;}
bool empty()const{return 0 == _size;}
private:
T _array[N];
size_t _size;
};
}注意:
浮点数、类对象以及字符串是不允许作为非类型模板参数的。
非类型的模板参数必须在编译期就能确认结果。
模板的特化
概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,比如:
template<class T>
bool IsEqual(T& left, T& right)
{
return left == right;
}
void Test()
{
const char* p1 = "hello";
const char* p2 = "world";
if(IsEqual(p1, p2))
cout<<p1<<endl;
else
cout<<p2<<endl;
}此时,就需要对模板进行特化,即在原模板类的基础上,针对特殊类型所进行特殊化的实现方式,模板特化中分为函数模板特化与类模板特化。
函数模板的特化
函数模板特化的步骤:
必须要现有一个基础的函数模板
关键字template后接一对空的尖括号<>
函数名后跟一对尖括号,尖括号中指定需要特化的类型
函数形参表:必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误
template<>
bool IsEqual<char*>(char*& left, char*& right)
{
if(strcmp(left, right) > 0)
return true;
return false;
}注意:
一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。
bool IsEqual(char* left, char* right)
{
if(strcmp(left, right) > 0)
return true;
return false;
}类模板的特化
全特化:
全特化即是将模板参数列表中所有的参数都确定化
template<class T1, class T2>
class Data
{
public:
Data() {cout<<"Data<T1, T2>" <<endl;}
private:
T1 _d1;
T2 _d2;
};
template<>
class Data<int, char>
{
public:
Data() {cout<<"Data<int, char>" <<endl;}
private:
T1 _d1;
T2 _d2;
};
void TestVector()
{
Data<int, int> d1;
Data<int, char> d2;
} 偏特化:
任何针对模版参数进一步进行条件限制设计的特化版本。比如对于以下模板类:
template<class T1, class T2>
class Data
{
public:
Data() {cout<<"Data<T1, T2>" <<endl;}
private:
T1 _d1;
T2 _d2;
};部分特化:
将模板参数类表中的一部分参数特化。
// 将第二个参数特化为int
template <class T1>
class Data<T1, int>
{
public:
Data() {cout<<"Data<T1, int>" <<endl;}
private:
T1 _d1;
int _d2;
}; 参数更进一步的限制
偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。
//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:
Data() {cout<<"Data<T1*, T2*>" <<endl;}
private:
T1 _d1;
T2 _d2;
};
//两个参数偏特化为引用类型
template <typename T1, typename T2>
class Data <T1&, T2&>
{
public:
Data(const T1& d1, const T2& d2): _d1(d1), _d2(d2)
{
cout<<"Data<T1&, T2&>" <<endl;
}
private:
const T1 & _d1;
const T2 & _d2;
};
void test2 ()
{
Data<double , int> d1; // 调用特化的int版本
Data<int , double> d2; // 调用基础的模板
Data<int *, int*> d3; // 调用特化的指针版本
Data<int&, int&> d4(1, 2); // 调用特化的指针版本
}模板分离编译
什么是模板分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
// a.h
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}分析:

解决方法
将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。推荐使用这种。
模板定义的位置显式实例化。这种方法不实用,不推荐使用。
模板总结
优点
模板服用了代码,节省资源,更快的迭代开发。
增强了代码的灵活性。
缺点
模板会导致代码膨胀的问题。
出现模板编译错误时,错误信息会非常凌乱,不易定位。