基于Qt Widgets的Qt程序,控件的刷新默认状况下都是在UI线程中依次进行的,换言之,各个控件的QWidget::paintEvent方法会在UI线程中串行地被调用。若是某个控件的paintEvent很是耗时(等待数据时间+CPU处理时间+GPU渲染时间),会致使刷新帧率降低,界面的响应速度变慢。
假如这个paintEvent耗时的控件没有使用OpenGL渲染,彻底使用CPU渲染。这种状况处理起来比较简单,只须要另外开一个线程用CPU往QImage里面渲染,当主线程调用到这个控件的paintEvent时,再把渲染好的QImage画出来就能够了,单纯绘制一个QImage仍是很快的。
若是这个paintEvent耗时的控件使用了OpenGL渲染,状况会复杂一些,由于想要把OpenGL渲染过程搬到另一个线程中并非直接把OpenGL调用从UI线程搬到渲染线程就能够的,是须要作一些准备工做的。另外,UI线程如何使用渲染线程的渲染结果也是一个须要思考的问题。
以绘制一个迭代了15次的Sierpinski三角形为例,它总共有3^15=14348907个三角形,在个人MX150显卡上绘制一次需要30ms左右的时间。所以若是我在UI线程渲染这些顶点的话,UI线程的刷新帧率就会掉到30帧左右。如今咱们来看一下如何在另外一个线程中渲染这些三角形。
软硬件环境
CPU:Intel® Core™ i5-8250U CPU @ 1.60GHz多线程
GPU:NVIDIA GeForce MX150(Driver:388.19)svg
OS:Microsoft Windows 10 Home 10.0.18362性能
Compiler:MSVC 2017测试
Optimization flag:O2this
Qt version:5.12.1spa
OpenGL version:4.6.0
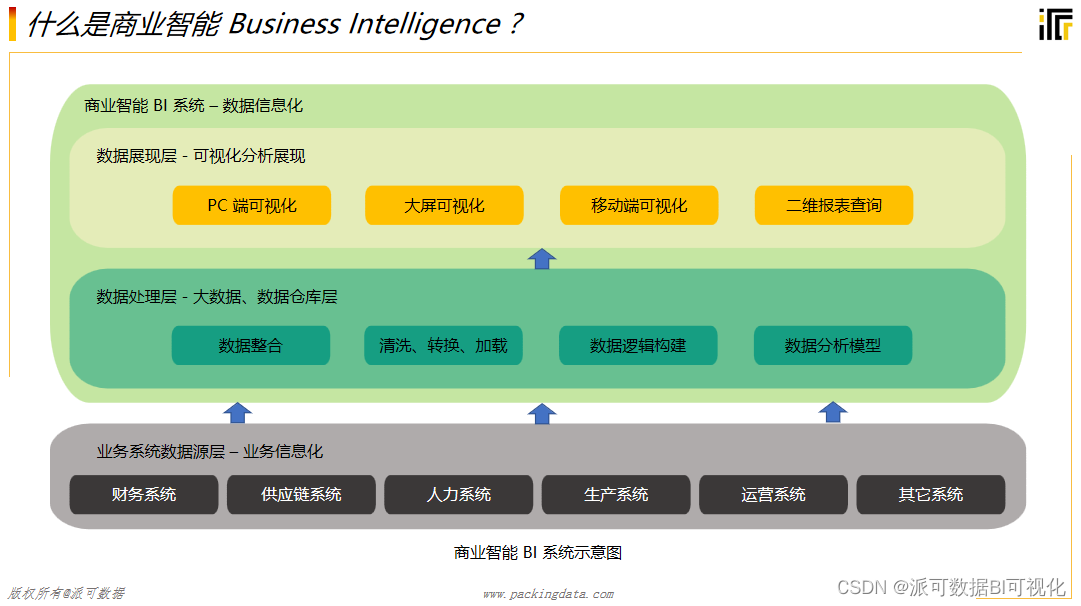
概述
有如下主要的类或方法:
- GLWidget
这个类在UI线程中使用,继承了QOpenGLWidget,负责将渲染线程渲染结果绘制到屏幕上。
- Renderer
这个类在渲染线程中使用,负责将三角形渲染到离屏framebuffer中。
- RenderThread
渲染线程管理类,负责初始化渲染线程OpenGL的context。
- TextureBuffer
纹理缓存类,负责将Renderer渲染好的图像缓存到纹理中,供UI线程绘制使用。
- RenderThread::run
渲染线程的例程,负责调用Renderer的方法渲染图像,在Renderer渲染好一帧图像后将图像保存在TextureBuffer中。
context
OpenGL须要context来保存状态,context虽然能够跨线程使用,但没法在多个线程中同时使用,在任意时刻,只能绑定在一个线程中。所以咱们须要为渲染线程建立一个独立的context。
数据共享
UI线程如何访问渲染线程的渲染结果。有两种思路:
- 将渲染结果读进内存,生成QImage,再传给UI线程。这种方式的优势是实现简单。缺点则是性能可能差一些,把显存读进内存是一个开销比较大的操做。
- 将渲染结果保存到纹理中,UI线程绑定纹理绘制到屏幕上。这种方式的优势是性能较方法1好。缺点是为了让两个线程可以共享纹理,须要作一些配置。
在此,咱们选择的是方法2。
初始化渲染线程
了解到上面的这些信息后,咱们来看一下如何初始化渲染线程。
因为须要UI线程可以和渲染线程共享数据,须要调用QOpenGLContext::setShareContext来设置,而这个方法又须要在QOpenGLContext::create方法前调用。UI线程context的QOpenGLContext::create方法调用咱们是没法掌握的,所以须要渲染线程context来调用QOpenGLContext::setShareContext。因为调用时须要确保UI线程context已经初始化,所以在GLWidget::initializeGL中初始化渲染线程比较好,相关代码以下:
void GLWidget::initializeGL()
{
initRenderThread();
...
}
...
void GLWidget::initRenderThread()
{
auto context = QOpenGLContext::currentContext();
auto mainSurface = context->surface();
auto renderSurface = new QOffscreenSurface(nullptr, this);
renderSurface->setFormat(context->format());
renderSurface->create();
context->doneCurrent();
m_thread = new RenderThread(renderSurface, context, this);
context->makeCurrent(mainSurface);
connect(m_thread, &RenderThread::imageReady, this, [this](){
update();
}, Qt::QueuedConnection);
m_thread->start();
}
...
RenderThread::RenderThread(QSurface *surface, QOpenGLContext *mainContext, QObject *parent)
: QThread(parent)
, m_running(true)
, m_width(100)
, m_height(100)
, m_mainContext(mainContext)
, m_surface(surface)
{
m_renderContext = new QOpenGLContext;
m_renderContext->setFormat(m_mainContext->format());
m_renderContext->setShareContext(m_mainContext);
m_renderContext->create();
m_renderContext->moveToThread(this);
}
...在GLWidget::initRenderThread中,咱们首先得到UI线程的context,以及其关联的mainSurface。而后为渲染线程建立了一个QOffscreenSurface,将其格式设置为与UI线程context相同。而后调用doneCurrent取消UI线程context与mainSurface的关联,这是为了可以使UI线程的context和渲染线程的context设置共享关系。待渲染线程初始化完成后,再将UI线程context与mainSurface进行关联。而后设置一个链接用于接收渲染线程的imageReady信号。最后启动渲染线程开始渲染。
在RenderThread::RenderThread中,首先初始化渲染线程的context,因为RenderThread::RenderThread是在UI线程中调用的,还要调用moveToThread将其移到渲染线程中。
渲染线程例程
// called in render thread
void RenderThread::run()
{
m_renderContext->makeCurrent(m_surface);
TextureBuffer::instance()->createTexture(m_renderContext);
Renderer renderer;
while (m_running)
{
int width = 0;
int height = 0;
{
QMutexLocker lock(&m_mutex);
width = m_width;
height = m_height;
}
renderer.render(width, height);
TextureBuffer::instance()->updateTexture(m_renderContext, width, height);
emit imageReady();
FpsCounter::instance()->frame(FpsCounter::Render);
}
TextureBuffer::instance()->deleteTexture(m_renderContext);
}渲染线程开始渲染时,首先绑定context和初始化TextureBuffer。而后在循环中重复执行渲染-保存纹理的循环
离屏渲染
其初始化在Renderer::init中进行,渲染在Renderer::render中进行,各种OpenGL基础教程中都有对离屏渲染的相关介绍和分析,此处再也不赘述。
保存纹理
// called in render thread
void TextureBuffer::updateTexture(QOpenGLContext *context, int width, int height)
{
Timer t("ImageBuffer::updateTexture");
QMutexLocker lock(&m_mutex);
auto f = context->functions();
f->glActiveTexture(GL_TEXTURE0);
f->glBindTexture(GL_TEXTURE_2D, m_texture);
f->glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, nullptr);
f->glCopyTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, 0, 0, width, height, 0);
f->glBindTexture(GL_TEXTURE_2D, 0);
f->glFinish();
}在RenderThread::run中调用TextureBuffer::updateTexture将使用glCopyTexImage2D将渲染线程渲染结果保存到纹理中,在Qt中OpenGL调用都须要经过QOpenGLFunction对象,所以将渲染线程的QOpenGLContext对象传进来,能够得到其默认的QOpenGLFunction对象。
因为咱们只使用了一个纹理来缓存图像,若是渲染线程渲染得比较快的话,有些帧就会来不及渲染被丢弃。固然你也能够改程序阻塞渲染线程避免被阻塞。
绘制纹理
void GLWidget::paintGL()
{
Timer t("GLWidget::paintGL");
glEnable(GL_TEXTURE_2D);
m_program->bind();
glBindVertexArray(m_vao);
if (TextureBuffer::instance()->ready())
{
TextureBuffer::instance()->drawTexture(QOpenGLContext::currentContext(), sizeof(vertices) / sizeof(float) / 4);
}
glBindVertexArray(0);
m_program->release();
glDisable(GL_TEXTURE_2D);
FpsCounter::instance()->frame(FpsCounter::Display);
}
...
// called in main thread
void TextureBuffer::drawTexture(QOpenGLContext *context, int vertextCount)
{
Timer t("ImageBuffer::drawTexture");
QMutexLocker lock(&m_mutex);
auto f = context->functions();
f->glBindTexture(GL_TEXTURE_2D, m_texture);
f->glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
f->glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
f->glActiveTexture(GL_TEXTURE0);
f->glDrawArrays(GL_TRIANGLES, 0, vertextCount);
f->glBindTexture(GL_TEXTURE_2D, 0);
//f->glFinish();
}在GLWidget::paintGL中调用TextureBuffer::drawTexture来绘制缓存的纹理。
性能
上面所作的这一切,可以提升性能吗?很遗憾,答案是“不必定”。就这个demo而言,渲染过程几乎彻底不须要等待数据和CPU处理(除了初始化时须要CPU计算),不断使用GPU进行渲染,这致使GPU占用率几乎达到了100%,成为了一个瓶颈。当主线程进行OpenGL调用时,极可能会由于正在处理渲染线程的OpenGL调用而被阻塞,致使帧率降低。使用NVIDIA Nsights Graphics实测结果以下:

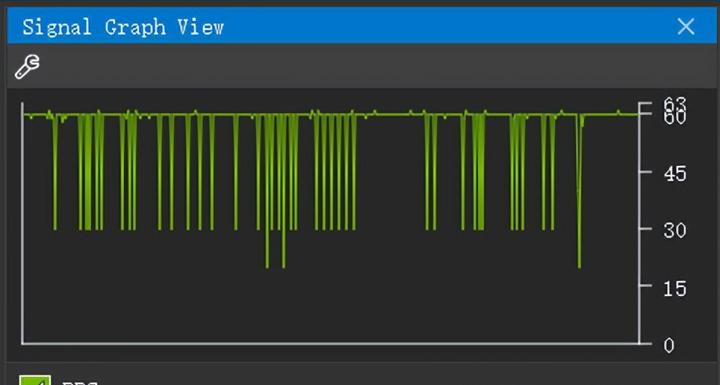
第一幅图是刚打开程序时的帧率,基本稳定在60帧,第二幅图是运行一段时间后的帧率,时常跌到30帧。就平均帧率而言,性能较单线程渲染仍是有提高的。至于为何运行一段时间后帧率会降低,猜测是GPU温度升高被降频致使的,使用GPU-Z观察GPU时钟频率能够验证这一猜测。
若是渲染过程当中等待数据和CPU处理时间占了必定的比重的话,多线程离屏渲染就有优点了。不过在这种状况下,单把等待数据和CPU处理的代码移到独立线程也许是个不错的选择。具体采用哪一种方案仍是要根据实际测试效果来决定。