目录
- CPU与GPU的基本知识
- CPU特点
- GPU特点
- GPU vs. CPU
- 什么样的问题适合GPU?
- GPU编程
- CUDA编程并行计算的整体流程
- CUDA编程术语:硬件
- CUDA编程术语:内存模型
- CUDA编程术语:软件
- 线程块(Thread Block)
- 网格(grid)
- 线程块id & 线程id
- 线程束(warp)
CPU与GPU的基本知识
GPU:吞吐导向内核
CPU:延迟导向内核
- 延迟:一条指令从发出到发出结果的时间间隔
- 吞吐量:单位时间内处理指令的数量
CPU特点
- 内存大:多级缓存结构提高访存速度
- 处理运算速度远高于访问存储速度 -> 空间换时间
- 经常访问的内容放到低级缓存(L1),不常访问的内容放到高级缓存
- 控制复杂
- 分支预测机制 (if-else/break/continue等 在硬件端的机制)
- 流水线数据前送
- 运算单元强大
- 整型浮点型复杂运算速度快

GPU特点
- 缓存小
- 提高内存吞吐
- 控制简单
- 没有分支预测
- 没有数据转发
- (-> 复杂指令效率不高,简单指令吞吐显著提高)
- 精简运算单元
- 多长延时流水线以实现高吞吐量 (下图每一行绿色块)
- 需要大量的线程来容忍延迟

如图中所示,每一行的运算单元只有一个控制器,所以每一行的运算单元执行的是同一个指令,只不过是使用不同的数据。
GPU vs. CPU
- CPU:连续计算部分,延迟优先;相比GPU,单条指令延迟快十倍以上
- GPU:并行计算部分,吞吐优先;相比CPU,单位时间内执行指令数量10倍以上
什么样的问题适合GPU?
- 计算密集:数值计算比例远大于内存操作,因此内存访问的延时可以被计算覆盖
- 数据并行:大任务可以拆解为相同指令的小人物,因此对复杂流程的控制需求较低
GPU编程
CUDA编程并行计算的整体流程
void GPUkernel(float* A, float* B, float* C, int n)
{
1. // Allocate device memory for A, B, and C
// copy A and B to device memory
2. // Kernel launch code – to have the device
// to perform the actual vector addition
3. // copy C from the device memory
// Free device vectors
}

CUDA编程术语:硬件
- Device = GPU
- Host = CPU
- Kernel = GPU上运行的函数
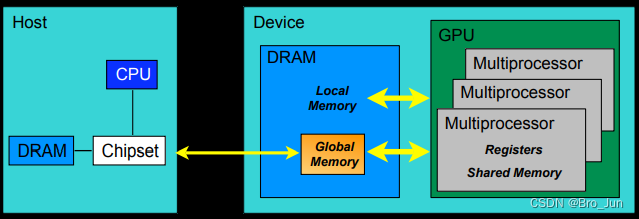
CUDA编程术语:内存模型
CUDA中的内存模型分为一下几个层次:
- 每个线程处理器 (Thread Processor, PS)都有自己的寄存器(register)
- 每个SP都有自己的局部内存(local memory),register和local memory只能被线程自己访问
- 每个多核处理器(SM)内都有自己的共享内存(shared memory),其可被线程块(Thread Block)内所有线程访问
- 一个GPU的所有SM共有一块全局内存(global memory),不同线程块的线程都可以使用
CUDA编程术语:软件
- 分为以下几个层次
- 线程处理器(SP)对应线程(thread)
- 多核处理器(SM)对应线程块(thred block)
- 设备端(device)对应线程块组合体(grid)
- 一个kernel其实由一个grid来执行
- 一个kernel一次只能在一个GPU上执行

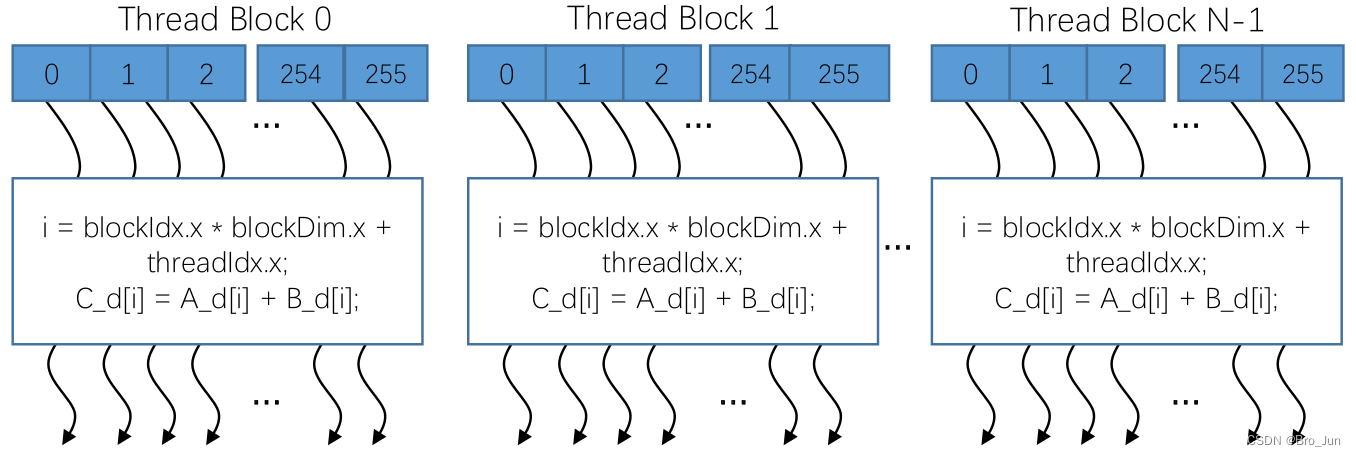
线程块(Thread Block)
线程块:可扩展的集合体;将线程数组分成多个块
- 块内的线程通过共享内存、原子操作和屏障同步进行协作(shared memory, atomic operations and barrier synchronization)
- 不同块中的线程不能协作,即线程的操作是互相独立的互不影响的

如图,该线程块包含256个线程,所执行的任务为向量相加的操作。其中,i = … 为确定线程在显存中位置的计算公式。
网格(grid)
网格:并行线程块组合
- CUDA核函数由线程网格(数组)执行
- 每个线程都有一个索引,用于计算内存地址和做出决策控制
- 每个线程块互不影响
- 最后将N个线程块的结果进行融合
线程块id & 线程id
- 每个线程要使用索引来决定要处理的数据
- 无论是线程块id或是线程id,都可以是1维、2维或者3维的,如下图所示:

• dim3 dimGrid(M, N);
• dim3 dimBlock(P, Q, S);
• threadId.x = blockIdx.x * blockDim.x + threadIdx.x;
• threadId.y = blockIdx.y * blockDim.y + threadIdx.y;
线程束(warp)
- 多核处理器(SM)采用单指令多线程架构 SIMT(Single-Instruction, Multiple-Thread),其中warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。warp本质上是线程在GPU上运行的最小单元。
- 当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个线程拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
- 由于warp的大小为32,所以block所含的thread的大小一般要设置为32的倍数。(或者可以说,每个线程块要包含N个整行的计算单元,而不能是一半)