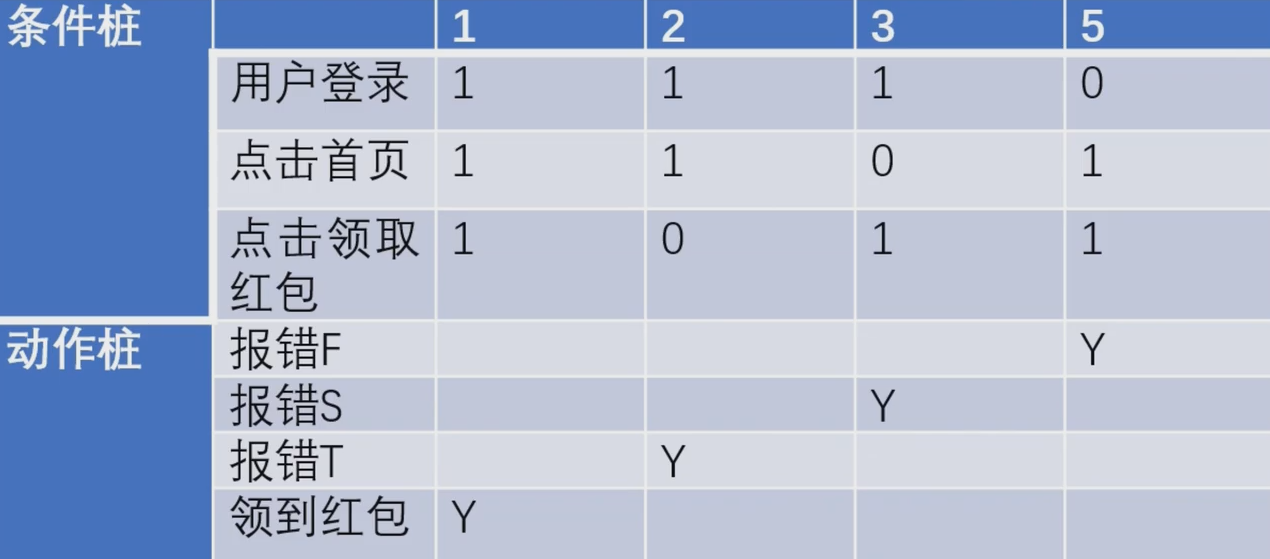
一.知识回顾
之前的文章我们一起学习了MySQL面试必问系列之事务专题、锁专题,没有学习的小伙伴可以直接通过该链接地址直接访问,MYSQL你真的了解吗专栏的文章,接下来我们就一起来学习一下MySQL中SQL语句的执行流程,看看你掌握的怎么样呢?
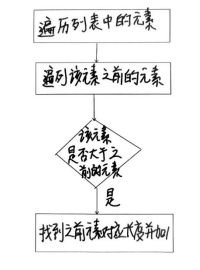
二.面试官:我问个简单的吧,你知道一条查询SQL语句执行的流程吗?
此时卑微的你,刚听到这个问题肯定就在想,这个简单吗?

其实这个问题就看你面试的岗位以及公司的层次了,如果是一些中大型公司互联网公司的话,那么还可以接受,但是如果是一些小一些的公司的话,我只能觉得现在的面试真的越来越畸形了,其实呢?这个问题考察的点就是看你是否认真学习过MySQL底层的一些知识,是否认真的积累过。就像有的人说,面试造火箭,工作拧螺丝,其实不假,但是现在拧螺丝都需要段位了,所以说大家还是静下心来一点一点的积累吧,肯定都能找到理想的公司的。
废话不多说,我们直接开整。
2.1 SQL语句执行流程图
首先我们先来看一下整个SQL语句执行的流程图,先对整体有一个大致的了解,具体细节我们后面再做展示。如下图所示:
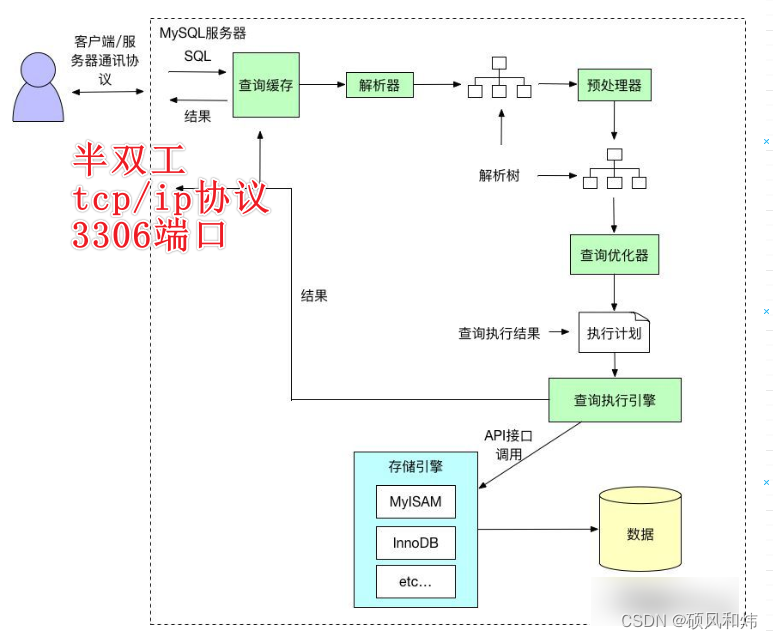
2.2 查询缓存(Query Cache)
- MySQL 内部自带了一个缓存模块。MySQL查询缓存保存查询返回的完整结构。当查询命中该缓存时,MySQL会立刻返回结果,跳过了解析、优化和执行阶段。
- 查询缓存系统会跟踪查询中涉及的每个表,如果这些表发生了变化,那么和这个表相关的所有缓存数据都将失效。
- 如果查询语句中包含任何的不确定的函数,那么其查询结果不会被缓存,因为查询缓存中也无法找到对应的缓存结果。
- MySQL将缓存存放在一个引用表中,通过一个哈希值引用,这个哈希值包括了以下因素,即查询本身、当前要查询的数据库、客户端协议的版本等一些其他可能影响返回结果的信息。
- MySQL 的缓存模块默认是关闭的。主要是因为 MySQL 自带的缓存的应用场景有限,第一个是它要求 SQL 语句必须一模一样。第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效。
- 在 MySQL 5.8 中,查询缓存已经被移除了。
2.3 解析器(Parser)
假如随便执行一个字符串 hjghkjhkj,服务器报了一个 1064 的错:
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘hjghkjhkj’ at line 1
服务器是怎么知道我输入的内容是错误的?这一步主要做的事情是对 SQL 语句进行词法和语法分析和语义的解析。
2.3.1 词法解析
首先第一个步骤就是词法分析,就是把一个完整的 SQL 语句打碎成一个个的单词。
比如一个简单的 SQL 语句:
select age from user where id = 1;
郑愕SQL语句会被解析为8 个符号,记录每个符号是什么类型,开始位置以及结束位置都会被记录。
2.3.2 语法解析
然后第二步就是语法分析,语法分析会对 SQL 做一些语法检查,比如单引号有没有闭合,然后根据 MySQL定义的语法规则,根据 SQL 语句生成一个数据结构。这个数据结构我们把它叫做解析树。
2.3 预处理器(Preprocessor)
如果表名错误,会在预处理器处理时报错。这个就是 MySQL Preprocessor 预处理模块。
它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是否存在,检查名字和别名,保证没有歧义。
2.4 查询优化(Query Optimizer)与查询执行计划
2.4.1 什么优化器?查询优化器的目的?
你是否想过这样的问题:
- 你编写的SQL语句MySQL底层一定执行呢?会不会进行一个优化呢?一条SQL语句只会有一种执行的方式吗?
- 因为一条 SQL 语句是可以有很多种执行方式的。但是如果有这么多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
解决上述问题我们就可以引出来解决这个问题的方案措施:MySQL 的查询优化器的模块(Optimizer)。
查询优化器的目的就是根据解析树生成不同的执行计划,然后选择一种最优的执行计划,MySQL 里面使用的是基于开销的优化器,那种执行计划开销最小,就用哪种。
2.4.2 查询开销的命令
使用如下命令查看查询的开销:
show status like 'Last_query_cost';
--代表需要随机读取几个 4K 的数据页才能完成查找。
2.4.3 优化器是怎么得到执行计划的?
如果我们想知道优化器是怎么工作的,它生成了几种执行计划,每种执行计划的 cost 是多少,应该怎么做?
首先我们要启用优化器的追踪(默认是关闭的):
注意开启这开关是会消耗性能的,因为它要把优化分析的结果写到表里面,所以不要轻易开启,或者查看完之后关闭它(改成 off)。
SHOW VARIABLES LIKE 'optimizer_trace';
set optimizer_trace="enabled=on";
接着我们执行一个 SQL 语句,优化器会生成执行计划:
select t.tcid from teacher t,teacher_contact tc where t.tcid = tc.tcid;
这个时候优化器分析的过程已经记录到系统表里面了,我们可以查询:
select * from information_schema.optimizer_trace\G
expanded_query 是优化后的 SQL 语句。
considered_execution_plans 里面列出了所有的执行计划。
记得关掉它:
set optimizer_trace="enabled=off";
SHOW VARIABLES LIKE 'optimizer_trace';
2.4.4 优化器得到的结果
-
优化器最终会把解析树变成一个查询执行计划,查询执行计划是一个数据结构。
-
执行计划是不是一定是最优的执行计划呢?不一定,因为 MySQL 也有可能覆盖不到所有的执行计划。
-
MySQL 提供了一个执行计划的工具。我们在 SQL 语句前面加上 EXPLAIN,就可以看到执行计划的信息。
EXPLAIN select name from user where id=1;
三.面试官:嗯,不错,不错,刚你说了查询语句,那你知道一条增删改SQL语句执行的流程吗?
想必此时的你一定已经奔溃了,这循环连问让我好难受呀。

但是看了硕风和炜的文章后, 必须给面试官答上来。

3.1 一条更新SQL语句执行流程
- 首先,你应该把上面SQL语句查找的流程先说一遍,基本流程是一样的,也就是说,同样需要经过缓存,解析器,优化器的处理,最后交给执行器,选择最合适的优化计划,因为更新语句也只是做了一部分调整,并不是一个完全新的知识体系。
- 那问题来了,区别在哪里呢?其实真正的区别就在拿到符合条件之后的操作。
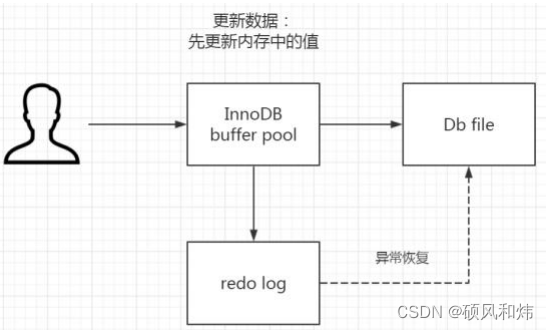
- 首先,在innoDB里面有个内存的缓冲池,我们也叫它Buffer pool,我们对数据的更新操作,不会每次都直接写到硬盘上,因为IO的代价太大了,所以先写入到buffer pool里面。内存的数据页和磁盘数据不一样的时候,我们把它就做脏页。
- InnoDB里面专门又把buffer pool中的数据写入到磁盘的线程,每隔一段时间就会一次性的把多个修改写入磁盘,这个过程就叫做脏刷。
3.2 存在的问题&持久化机制
3.2.1 存在的问题
这里也会存在一个问题就是,如果在脏页还没有写入到磁盘的时候,服务器此时出现了问题,那么内存中的数据就会存在丢失的问题。或者是刷脏刷到一半的时候,甚至破坏数据文件,所以我们必须做一个持久化的机制。
3.2.2 持久化机制
InnoDB引入了一个日志文件,我们叫做redo log重做日志,我们把所有对内容数据的修改操作写入日志文件,如果服务器出现了问题,我们就从这个额日志文件里面文件读取数据,恢复数据,用它来实现事务的持久化。
3.2.3 redo log有什么特点呢?
- 记录修改后的值,属于物理日志
- redo log 大小固定,前面内容会被覆盖,所以并不能用于数据的回滚,以及数据的恢复
- redo log是innodb引擎特有的,并不是所有的引擎都具备
3.2.4 Buffer Pool的内存淘汰策略
-
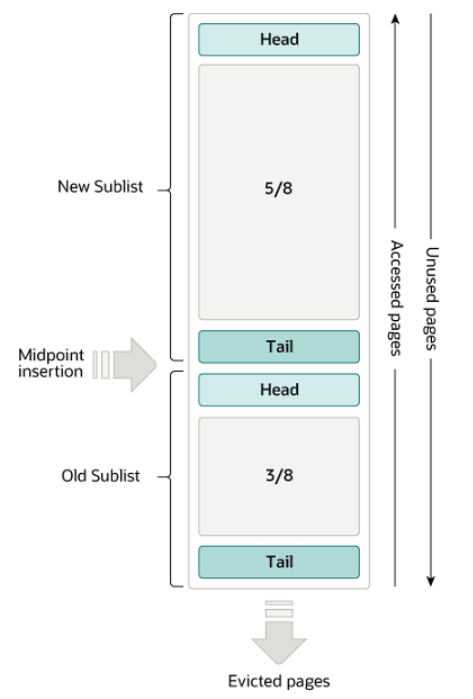
冷热分区的LRU策略
LRU链表会被拆分成为两部分,一部分为热数据,一部分为冷数据。冷数据占比 3/8,热数据5/8。
具体分配如下图所示:
-
数据页第一次加载进来,放在LRU链表的什么地方?
放在冷数据区域的头部
- 冷数据区域的缓存页什么时候放入热数据区域?
MySQL设定了一个规则,在 innodb_old_blocks_time 参数中,默认值为1000,也就是1000毫秒。
意味着,只有把数据页加载进缓存里,在经过1s之后再次对此缓存页进行访问才会将缓存页放到LRU链表热数据区域的头部。
4.为什么是1秒?
因为通过预读机制和全表扫描加载进来的数据页通常是1秒内就加载了很多,然后对他们访问一下,这些都是1秒内完成,他们会存放在冷数据区域等待刷盘清空,基本上不太会有机会放入到热数据区域,除非在1秒后还有人访问,说明后续可能还会有人访问,才会放入热数据区域的头部。
- 什么是预读机制呢?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K)但是Mysql的数据页是16K,如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
四.总结
饭要一口一口吃,知识也要一点一点积累,一起加油吧。
我是硕风和炜,我们下篇文章见哦。