温故而知新,通过手把手写一个多分类任务来复习之前所学过的知识。
- 前置知识
factorize的妙用:把文本数据枚举化
labels, uniques = pd.factorize(['b', 'b', 'a', 'c', 'b'])
labels,uniques
(array([0, 0, 1, 2, 0]), array([‘b’, ‘a’, ‘c’], dtype=object))
- 数据集读取以及处理
鸢尾花数据集相比大家都已经很熟悉了。
data = pd.read_csv("dataset/iris.csv")
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 150 non-null int64
1 Sepal.Length 150 non-null float64
2 Sepal.Width 150 non-null float64
3 Petal.Length 150 non-null float64
4 Petal.Width 150 non-null float64
5 Species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
unnamed列是序号列,没用
species时分类列,
一共150条数据,数据是初探
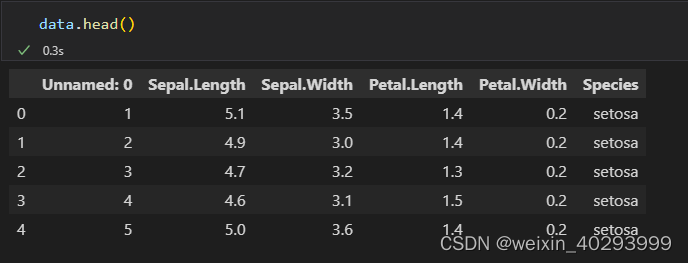
有三类鸢尾花,他们是类别,
但是因为torch只能处理数字,文本需要转换成数字类型 1前置就用到了
data.Species.unique()
array(['setosa', 'versicolor', 'virginica'], dtype=object)
labels,uniques = pd.factorize(data.Species.values)
data['Species'] = labels
data
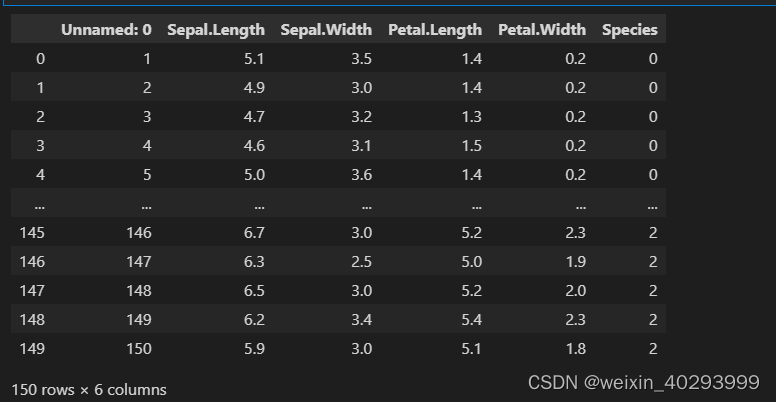
Unnamed 列是用不到的,是序号列去掉,这样以来前几列是训练集,最后一列是标签 .values 返回的是numpy数据
# Unnamed 列是用不到的,是序号列去掉,这样以来前几列是训练集,最后一列是标签
X = data.iloc[:,1:-1].values
Y = data.iloc[:,-1].values
- test,train 数据划分
借助sklearn 完成划分,并转成torch格式, y必须为torch.int64 或者 torch.Long 类型,否则训练过程报错。因为只能计算Long类型的
train_x, test_x, train_y,test_y = train_test_split(X,Y)
# 切分数据集后,转成torch格式
train_x = torch.from_numpy(train_x).type(torch.float32)
train_y = torch.from_numpy(train_y).type(torch.int64)
test_x = torch.from_numpy(test_x).type(torch.float32)
test_y = torch.from_numpy(test_y).type(torch.int64)
转成 dataset 和 dataloader,这样转的原因我已经在模板那篇文章写清楚了,核心:1. train 数据集需要 shuffle 2.自动实现切片功能
batch_size=8
train_ds = TensorDataset(train_x, train_y)
train_dl = DataLoader(train_ds,batch_size=batch_size,shuffle=True)
test_ds = TensorDataset(test_x, test_y)
test_dl = DataLoader(test_ds,batch_size=batch_size)
- 设计网络和损失函数
不需要多解释,但为啥不在这边就用了 self.softmax = nn.Softmax(3)呢
是因为在损失函数中已经包含了这一部分,torch是这样的,tensorflow应该不是。
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.lin1 = nn.Linear(4,32)
self.lin2 = nn.Linear(32,32)
self.lin3 = nn.Linear(32,3)
# self.softmax = nn.Softmax(3)
def forward(self,x):
x = self.lin1(x)
x = F.relu(x)
x = self.lin2(x)
x = F.relu(x)
x = self.lin3(x)
return x
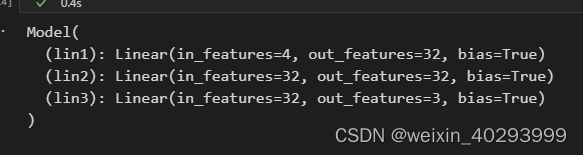
model = Model()
model
看一下它的结构:
损失函数:多分类当然是交叉熵损失了
# 定义损失函数,多分类当让是交叉熵损失了
loss_fn = nn.CrossEntropyLoss()
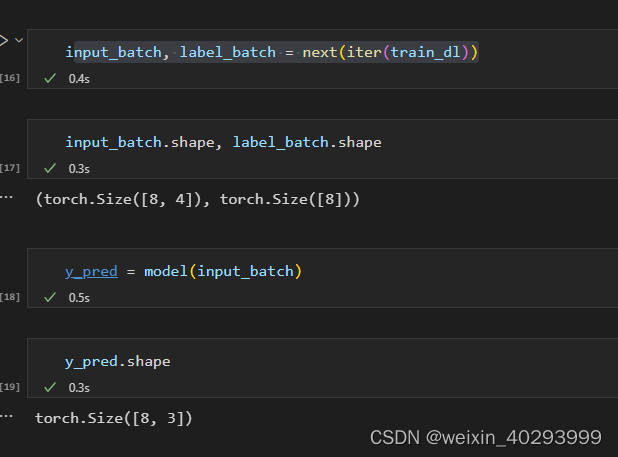
简单测试一下,这一步很重要!
input_batch, label_batch = next(iter(train_dl))
y_pred = model(input_batch)
torch.argmax(y_pred,dim=1)
5. 计算正确率&目标函数
# 定义目标函数
def accuracy(y_pred, y_true):
y_pred = torch.argmax(y_pred,dim=1)
acc = (y_pred ==y_true).float().mean()
return acc
optim = torch.optim.Adam(model.parameters(),lr=0.0001)

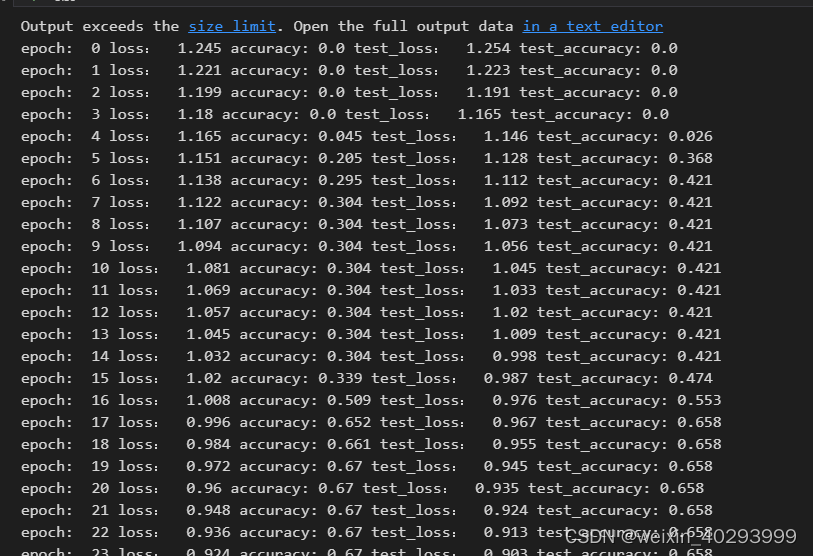
6. 训练
# 万事俱备,只差训练
train_loss =[]
train_acc = []
test_loss = []
test_acc= []
epochs = 200
for epoch in range(epochs):
for x,y in train_dl:
y_pred = model(x)
loss = loss_fn(y_pred,y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
epoch_acc_train = accuracy(model(train_x),train_y)
epoch_loss_train = loss_fn(model(train_x), train_y).data
epoch_acc_test = accuracy(model(test_x),test_y)
epoch_loss_test = loss_fn(model(test_x), test_y).data
print('epoch: ', epoch, 'loss: ', round(epoch_loss_train.item(), 3),
'accuracy:', round(epoch_acc_train.item(), 3),
'test_loss: ', round(epoch_loss_test.item(), 3),
'test_accuracy:', round(epoch_acc_test.item(), 3)
)
train_loss.append(epoch_loss_train)
train_acc.append(epoch_acc_train)
test_loss.append(epoch_loss_test)
test_acc.append(epoch_acc_test)
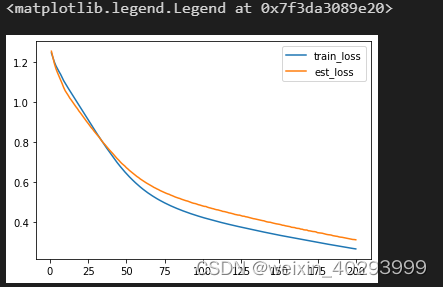
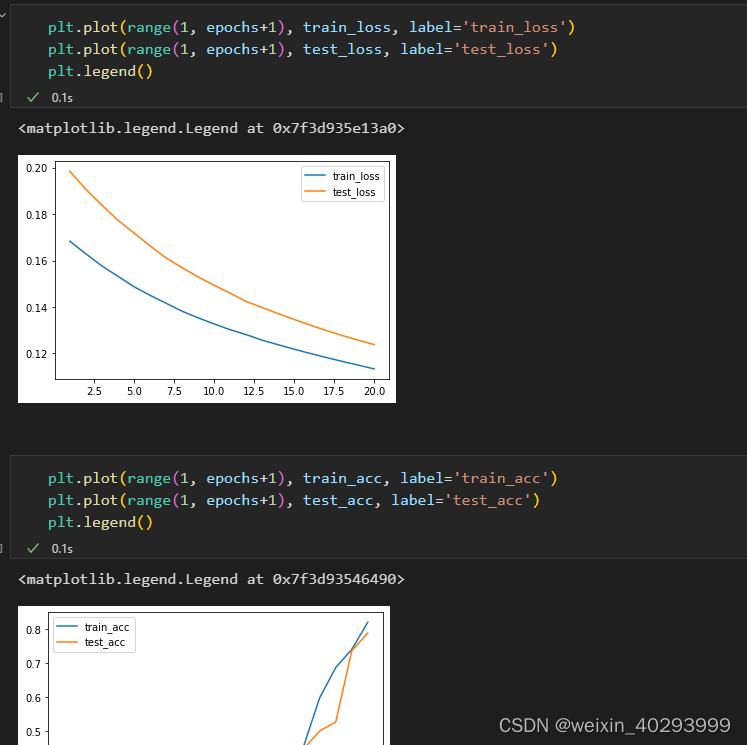
损失情况
7. 图的方式展示
···
import matplotlib.pyplot as plt
plt.plot(range(1, epochs+1), train_loss, label=‘train_loss’)
plt.plot(range(1, epochs+1), test_loss, label=‘est_loss’)
plt.legend()
···
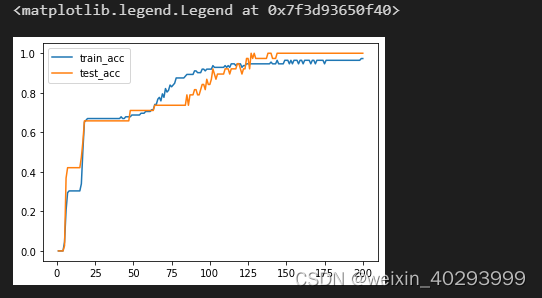
···
plt.plot(range(1, epochs+1), train_acc, label=‘train_acc’)
plt.plot(range(1, epochs+1), test_acc, label=‘test_acc’)
plt.legend()
···
8. 需要整一个训练的核心函数 fit函数
模板代码
- 创建输入(dataloader)
- 创建模型(model)
- 创建损失函数
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
for x, y in trainloader:
y_pred = model(x)
loss = loss_fn(y_pred, y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / total
test_correct = 0
test_total = 0
test_running_loss = 0
with torch.no_grad():
for x, y in testloader:
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'test_loss: ', round(epoch_test_loss, 3),
'test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
model = Model()
optim = torch.optim.Adam(model.parameters(), lr=0.0001)
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,
model,
train_dl,
test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
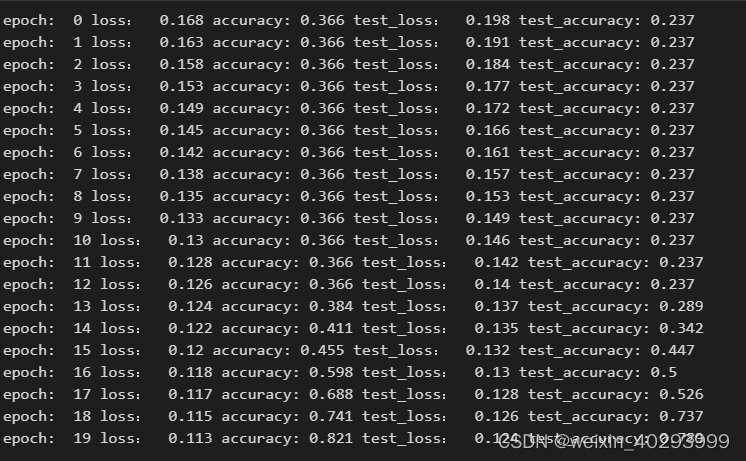
至此fit就可以对付所有的多分类问题了,您只需要修改model的网络结构即可