kafka使用场景
- canal同步mysql
- elk日志系统
- 业务系统Topic
kafka基础概念
- Producer: 消息生产者,向kafka发送消息
- Consumer: 从kafka中拉取消息消费的客户端
- Consumer Group: 消费者组,消费者组是多个消费者的集合。消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费。
减少Group订阅Topic的数量,一个Group订阅的Topic最好不要超过5个,建议一个Group只订阅一个Topic
- Broker: 一台kafka服务器就是一个
Broker,一个集群由多个Broker组成 - Topic:主题,可以理解为队列,生产者和消费者都是面向
Topic - Partition:分区,为了实现扩展性。一个非常大的
Topic可以分布在多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)- 便于在集群中扩展
- 可以提高并发,以
Partition为单位进行读写,类似于多路
# 默认分区数 server.properties配置 num.partitions=1 - Replica:副本,为保证集群中某个节点发生故障,节点上的
Partition数据不丢失,kafka可以正常的工作,kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower# 默认副本数 server.properties配置 # 默认分区副本数不得超过kafka节点数(副本数如果一个节点放2份,就没意义了) default.replication.factor=3 - Leader:每个分区多个副本的主角色,生产者发送数据对象,以及消费者消费数据都是
Leader - Follower: 每个分区多个副本的从角色,实时的从
Leader同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。 - ISR:
in sync replica,基本保存同步的Replica列表,是副本与主副本保持同步的列表,默认是30s数据,如果从副本保持同步,那么重新选举leader的时候,会被选择。如果与主副本同步差距较大,会被移除,选举leader将不会被考虑。 - OSR:
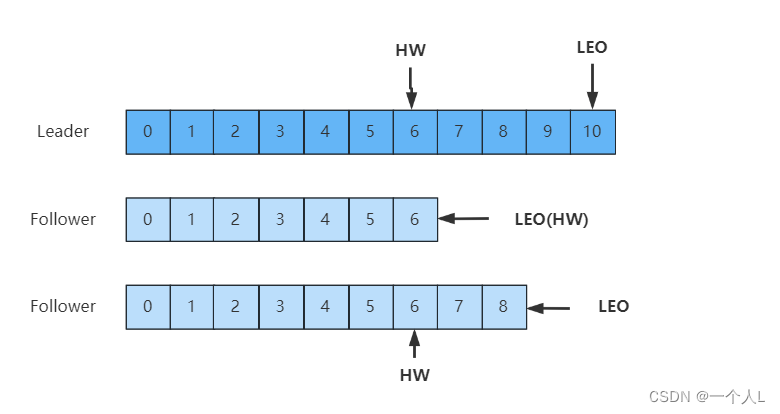
out of sync replica, 同步有延迟的follower列表 - LEO:
Log End Offset,每个副本最后一个offset - HW:
High Watermark,高水位,指消费者能见到的最大的offset,ISR队列中最小的LEO。
文件存储
主要是通过log和index等文件保存具体的消息文件
一个
topic对应多个partition
一个partition对应多个segment
一个segment对应log和index文件
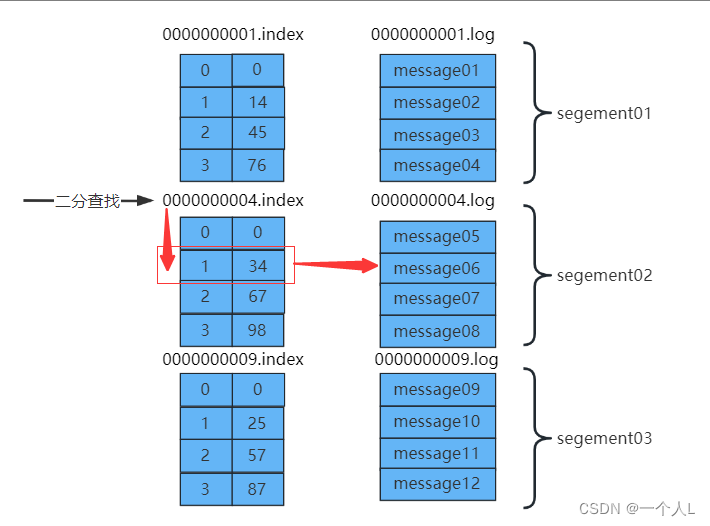
为了防止log文件过大导致定位效率低下,kafka的log文件以1G为一个分界点,当.log文件大小超过1G的时候,此时会创建一个新的.log文件,同时为了快速定位大文件中消息位置,kafka采取了分片和索引的机制来加速定位。
.index文件存储的消息的offset+真实的起始偏移量。.log中存放的是真实的数据。
数据定位步骤,查找offset=6的数据。
- 通过二分查找,定位
.index文件。offset=6(大于4,小于9),定位到第二个文件segement02 - 然后offset减去
segment02的起始偏移量(6-4=2),定位到之后总的偏移量 - 获取到总的偏移量之后,直接定位到
.log文件即可快速获得当前消息大小
生产者
发送消息分区策略
- 指明
partition(指明是指第几个分区)的情况下,直接将指明的值作为partition的值 - 没有指明
partition的情况下,但是存在值key,此时将key的hash值与topic的partition总数进行取余得到partition值 - 值与
partition均无的情况下,第一次调用时随机生成一个整数,后面每次调用在这个整数上自增,将这个值与topic可用的partition总数取余得到partition值,即round-robin算法。
生产者消息发送
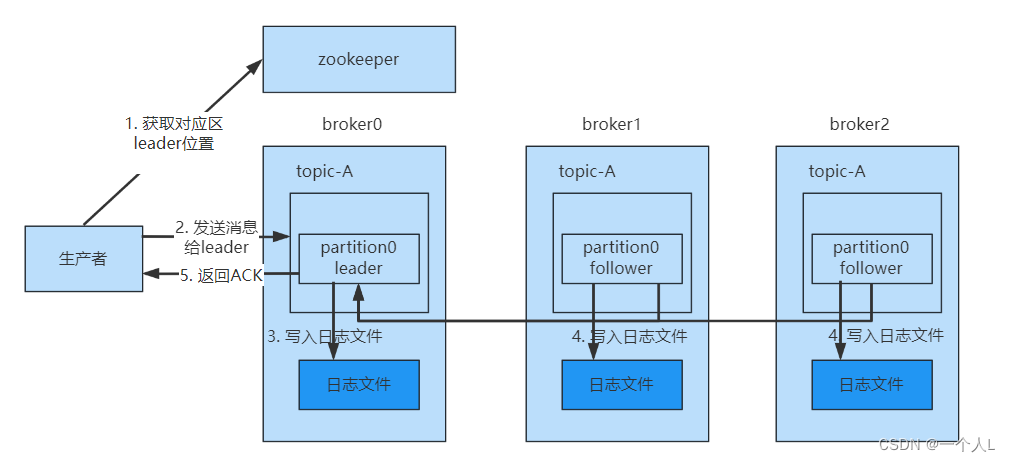
为保证producer发送的数据能够可靠的发送到指定的topic中,topic的每个partition收到producer发送的数据后,都需要向producer发送ackacknowledgement,如果producer收到ack就会进行下一轮的发送,否则重新发送数据。
发送ack时机
- 半数follower同步完成即发送ack,容错率低,延时低
- 全部follower同步完成完成发送ack,容错率高,延时高
kafka采用的是第二种,延迟对kafka影响比较小。
采用了第二种方案进行同步ack之后,如果leader收到数据,所有的follower开始同步数据,但有一个follower因为某种故障,迟迟不能够与leader进行同步,那么leader就要一直等待下去,直到它同步完成,才可以发送ack,此时需要如何解决这个问题呢?
leader中维护了一个ISR(in-sync replica set)同步副本集,即与leader保持同步的follower集合,当ISR中的follower完成数据的同步之后,给leader发送ack,如果follower长时间没有向leader同步数据,则该follower将从ISR中被踢出,该之间阈值由replica.lag.time.max.ms参数设定。当leader发生故障之后,会从ISR中选举出新的leader。
ack参数
0: producer不等待broker的ack,这一操作提供了最低的延迟,broker接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据1: producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将丢失数据。(只是leader落盘)-1(all): producer等待broker的ack,partition的leader和ISR的follower全部落盘成功才返回ack,但是如果在follower同步完成后,broker发送ack之前,如果leader发生故障,会造成数据重复。(这里的数据重复是因为没有收到,所以继续重发导致的数据重复)
高吞吐量,低延迟
- kafka会先写入
操作系统页缓存中,操作系统再决定将数据写回到磁盘上 - 磁盘顺序写,采用追加的方式写入消息
- 零拷贝
kafka消息发送,消息暂时暂存的,批量发送,RecordAccumulator.class是专门缓存kafka消息的。
spring:
kafka:
bootstrap-servers: 127.0.0.1:9200,127.0.0.1:9201,127.0.0.1:9202
producer: # producer 生产者
retries: 0 # 重试次数
acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 # 默认 批量大小 16KB
buffer-memory: 33554432 # 默认 生产端缓冲区大小 32MB
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
消费者
消费方式
消费者采用pull的方式来从broker中读取数据
push推的模式很难适应消费速率不同的消费者,因为消息发送率是由broker决定的,它的目标是尽可能以最快的速度传递消息,但是这样容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull方式则可以让consumer根据自己的消费处理能力以适当的速度消费消息。
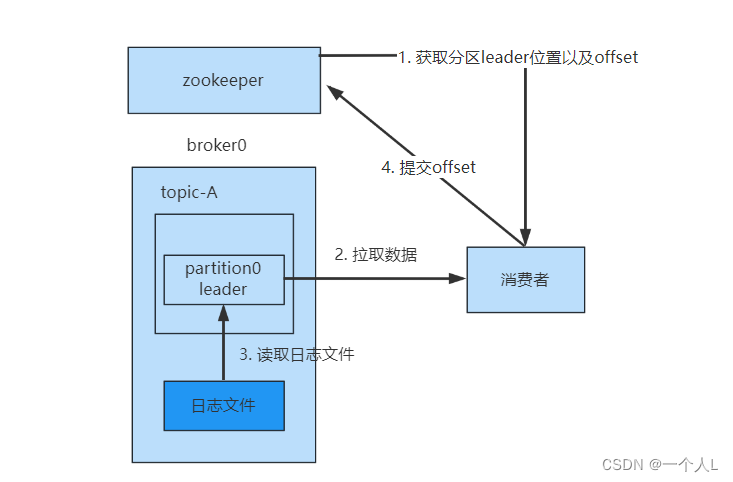
消费流程
- 从zookeeper中获取leader的位置和offset的位置,kafka0.9版本之前,consumer默认将offset保存在zookeeper中,从0.9版本之后,consumer默认将offset保存在kafka一个内置的topic中,该topic为
__consumer_offsets - 拉取数据,直接从broker的
page cache拉取 - 如果
page cache数据不全,就会从磁盘中拉取,并发送 - 消费完成后,可以手动提交offset,也可以自动提交offset
零拷贝
…
分区分配策略
线上的服务都是多个消费者服务一起消费的,一个topic包含多个partition,分区和消费者存在一个分配的策略,默认采用的是Range范围分配策略。
计算公式
n = 分区数/消费者数
m = 分区数%消费者数
前m个消费者,消费n+1个,剩下的消费n个
8个分区(p1 - p8),3个消费者(c1 - c3)
c1 分配 p1 p2 p3
c2 分配 p4 p5 p6
c3 分配 p7 p8
配置参数
spring:
kafka:
consumer: # consumer消费者
group-id: test-group # 默认的消费组ID
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 1000 # 提交offset延时(接收到消息后多久提交offset)
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 500 #一次拉取最大数据 500条
offset提交
默认是自动提交,enable.auto.commit=true
手动提交offset的方法有两种:
- commitSync:同步提交,失败后会自动重试
- commitAsync: 异步提交,失败后不会自动重试
重复消费
产生的原因
- 生产者重复提交
- rebalance引起的重复消费
超过一定时间(max.poll.interval.ms设置的值,默认5分钟)未进行poll拉取消息,则会导致客户端主动离开队列,而引发rebalance,提交offset失败。其他消费者会从没有提交的位置消费,从而导致重复消费。
解决方案
- 提高消费速度
- 增加消费者
- 多线程处理
- 异步消费
- 调整消费处理时间
- 幂等处理
- 消费者设置幂等校验
- 开启kafka幂等配置,生产者开启幂等配置,将消息生成md5,然后保存到redis中,处理新消息的时候先校验。这个尽量不要开启,消耗性能
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
批量消费配置
@Configuration
@Slf4j
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.group-id}")
private String consumerGroupId;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
public Map<String, Object> consumerFactory() {
Map<String, Object> props = new HashMap<>(16);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 120000);
props.put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, 180000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> containerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String>
factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerFactory()));
// 消费者组中线程数量
factory.setConcurrency(3);
// 当使用批量监听器时需要设置为true
factory.setBatchListener(true);
// 拉取超时时间
factory.getContainerProperties().setPollTimeout(3000);
// 重试次数
RetryingBatchErrorHandler errorHandler = new RetryingBatchErrorHandler(
new FixedBackOff(500L, 3L), null);
factory.setBatchErrorHandler(errorHandler);
return factory;
}
}
@KafkaListener(topics = "aloneness-topic02",
properties = {"max.poll.records=20"},
containerFactory = "containerFactory")
public void listen02(List<String> list) {
log.info("处理批量消息:{}", JSON.toJSONString(list));
List<Message> messages = JSON.parseArray(JSON.toJSONString(list), Message.class);
System.out.println(messages);
}
如果未配置重试次数,也消费代码中出现异常,会一直重试,一直消费异常
手动创建Topic
kafka版本大于2.2
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic als-test-topic02
--zookeeper localhost:2181指定zookeeper集群--partitions指定分区数--replication-factor指定分区副本数
重新分配分区副本
声明需要分配的Topic
topic-generate.json
{
"topics": [
{
"topic": "aloneness-topic"
}
],
"version": 1
}
通过 --topics-to-move-json-file 参数,生成分区分配策略 --generate
kafka-reassign-partitions.bat --zookeeper localhost:2181 --topics-to-move-json-file topic-generate.json --broker-list "0,1,2" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"aloneness-topic","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"aloneness-topic","partition":0,"replicas":[1],"log_dirs":["any"]}]}
通过 --reassignment-json-file 参数,执行分区分配策略 --execute
kafka-reassign-partitions.bat --zookeeper localhost:2181 --reassignment-json-file partition-replica-reassignment.json --execute