最近在学习RT-Thread,在看其源码的时候发现了许多自己不太了解的C语言知识点,在此查漏补缺一下。
1. 关键字
volatile
volatile是C90新增关键字,volatile的的中文意思是adj.易变的;无定性的;无常性的;可能急剧波动。与const正好是相反的,说明变量是允许被外界改变的。
当定义了一个无volatile修饰的变量时,如果通过硬件等方式改变其值则这个变量的值会被编译器优化,即编译器发现程序并没有改变该变量的值,程序继续使用其原先的值。
如果加了volatile,程序每次需要读取该变量的值时会直接从该变量的地址读取,当变量的值通过硬件的方式改变后,程序从变量地址读取后的值是通过硬件改变的值。从而不被编译器优化。
使用方式:
volatile int v;
在STM32编程中常用__IO这个宏来表示volatile
参考:菜鸟教程
register
register 存储类用于定义存储在寄存器中而不是 内存 中的局部变量。这意味着变量的最大尺寸等于寄存器的大小(通常是一个字),且不能对它应用一元的 ‘&’ 运算符(因为它没有内存位置)。
{
register int miles;
}
寄存器只用于需要快速访问的变量,比如计数器。还应注意的是,定义 ‘register’ 并不意味着变量将被存储在寄存器中,它意味着变量可能存储在寄存器中,这取决于硬件和实现的限制。
注意事项:
1、register修饰符暗示编译程序相应的变量将被频繁地使用,如果可能的话,应将其保存在CPU的寄存器中,以加快其存储速度。例如下面的内存块拷贝代码
2、但是使用register修饰符有几点限制
(1)register变量必须是能被CPU所接受的类型。
这通常意味着register变量必须是一个单个的值,并且长度应该小于或者等于整型的长度。不过,有些机器的寄存器也能存放浮点数。
(2)因为register变量可能不存放在内存中,所以不能用“&”来获取register变量的地址。
(3)只有局部自动变量和形式参数可以作为寄存器变量,其它(如全局变量)不行。
在调用一个函数时占用一些寄存器以存放寄存器变量的值,函数调用结束后释放寄存器。此后,在调用另外一个函数时又可以利用这些寄存器来存放该函数的寄存器变量。
(4)局部静态变量不能定义为寄存器变量。不能写成:register static int a, b, c;
(5)由于寄存器的数量有限(不同的cpu寄存器数目不一),不能定义任意多个寄存器变量,而且某些寄存器只能接受特定类型的数据(如指针和浮点数),因此真正起作用的register修饰符的数目和类型都依赖于运行程序的机器,而任何多余的register修饰符都将被编译程序所忽略。
注意:
早期的C编译程序不会把变量保存在寄存器中,除非你命令它这样做,这时register修饰符是C语言的一种很有价值的补充。然而,随着编译程序设计技术的进步,在决定哪些变量应该被存到寄存器中时,现在的C编译环境能比程序员做出更好的决定。实际上,许多编译程序都会忽略register修饰符,因为尽管它完全合法,但它仅仅是暗示而不是命令
参考:
-
浅析C语言的一个关键字——register
-
C存储类
enum
enum是C90标准新增的关键字,enum本质是int型,语法上与结构体相同,用于提高程序的可读性。
注意:C++中不允许枚举类型进行++操作。而C语言允许,因此一个C程序移植为C++时可以将枚举类型改为int型
默认值:如果不赋值则默认从0开始递增,如果中间有元素被赋值,则后面的值依次递增。
enum color = {red,green,blue,pink};
/* red,green,blue,pink成为 */
void*
void很常见,常用于限定函数的返回值为无以及函数的参数为空,但是void *却是头一次见,void *可以接收任意指针,但是指针在接收void *之前必须进行强制类型转换。内存分配函数malloc的返回值就是void*指针,所以需要强制类型转换。
int *a;
void *p;
p = a;//void指针可以接收其他类型指针
a = (int*)p;//其他类型指针接收void指针,需要进行强制类型转换
在ANSI C中不允许void *进行自加操作,而GNU中可以。因为GNU将void *看做char *
如果函数的参数可以是任意类型的指针,则应声明为void *
GNU __attribute__机制
目前市面上多数的C/C++ IDE使用的编译工具链都是GCC或者LLVM,包括很多的商业IDE的工具链也是基于优化过的GCC或LLVM。而在用到一些高级编译器特性时,我们需要去了解一些编译器命令,比如GNU C的__attribute__,在uboot和Linux源码中会常用到此命令。
__attribute__实际上是GCC的一种编译器命令,用来指示编译器执行实现某些高级操作。attribute__可以设置函数属性(Function Attribute)、变量属性(Variable Attribute)和类型属性(Type Attribute)。LLVM也借用了GCC的__attribute,并进行了扩展。
函数属性可以帮助开发人员向函数声明中添加一些特性,这可以使编译器在错误检查方面增强。变量属性允许对变量或结构体成员使用特定的属性进行修饰,比如结构体的对齐控制。
__attribute__的语法格式
attribute ((attribute-list))
attribute的前面和后面都有两个下划线,后面紧跟两对元括弧, attribute-list是一个用逗号分隔开的属性列表。attribute ((attribute-list))放于声明的尾部“;”之前。
常用属性
1、packed
让编译器在编译时取消结构体的字节优化对齐,按照实际占用的字节数进行对齐。在某些场景用户不希望编译器对字节对齐进行调整,否则处理起来会比较麻烦,那么可以使用该属性。
例如在源码中定义了两个结构
struct unpacked_str
{
uint8_t x;
uint16_t y;
};
struct packed_str
{
uint8_t x;
uint16_t y;
}__attribute__ ((packed));
struct unpacked_str strupkd;
struct packed_str strpkd;
int main(void)
{
printf("%d", sizeof(strupkd));
printf("%d", sizeof(strpkd));
}
使用clang编译,运行时分别输出为4和3。
2、aligned
规定变量或结构体成员最小对齐格式,以字节为单位。让用户自行决定变量的对齐字节数,比如一些处理器架构要求向量表需要按照规定的对齐地址放置,这时用户就需要进行控制了。
在代码中定义了一个32位变量:
uint32_t var_in_8bytes attribute((aligned(8)));
查看链接后的map映射文件,可以验证对齐的字节数和地址。

同样,你也可以使用默认的对齐方式。如果aligned后面不紧跟一个指定的数字值,那么编译器将依据你的目标机器情况使用最大最有益的对齐方式。
struct mystr
{
int16_t a[3];
} attribute ((aligned));
3、section
section控制变量或函数在编译时的段名。在嵌入式软件开发时用的非常多,比如有外扩Flash或RAM时,需要将变量或函数放置到外扩存储空间,可以在链接脚本中指定段名来操作。在使用MPU(存储保护)的MCU编程时,需要对存储器划分区域,将变量或代码放置到对应的区域,通常也是通过段操作来实现。
const int identifier[3] attribute ((section (“ident”))) = { 1,2,3 };
void myfunction (void) attribute ((section (“ext_function”)))
上述代码分别在编译后,数组和函数所在的段分别为“indent”和“ext_function”。
4、unused
意味着函数或变量很可能未被使用,编译器不会针对这个函数产生警告,可以将其声明在在函数实现中没有使用过的参数上,例如:
int main(int argc attribute((unused)), char **argv)
{ …}
5、used
此属性附加到具有静态存储的变量,意味着即使该变量看起来没有被引用,也必须保留该变量。否则在链接的时候链接器发现某个变量未被引用,会将此变量优化掉。
6、weak
若两个或两个以上全局符号名字一样,而其中之一声明为weak symbol(弱符号),则这些全局符号不会引发重定义错误。当普通符号存在时,链接器会忽略掉弱符号,如果不存在普通符号,则使用弱符号。
更多的__attribute__属性可以参考GCC手册,在我们需要使用到编译器一些高级特性的时候,可以在手册中查找。
参考:
-
https://zhuanlan.zhihu.com/p/474790212#:~:text=attribute%E5%AE%9E%E9%99%85%E4%B8%8A%E6%98%AFGCC%E7%9A%84%E4%B8%80%E7%A7%8D%E7%BC%96%E8%AF%91%E5%99%A8%E5%91%BD%E4%BB%A4%EF%BC%8C%E7%94%A8%E6%9D%A5%E6%8C%87%E7%A4%BA%E7%BC%96%E8%AF%91%E5%99%A8%E6%89%A7%E8%A1%8C%E5%AE%9E%E7%8E%B0%E6%9F%90%E4%BA%9B%E9%AB%98%E7%BA%A7%E6%93%8D%E4%BD%9C%E3%80%82%20__attribute__%E5%8F%AF%E4%BB%A5%E8%AE%BE%E7%BD%AE%E5%87%BD%E6%95%B0%E5%B1%9E%E6%80%A7%EF%BC%88Function,Attribute%EF%BC%89%E3%80%81%E5%8F%98%E9%87%8F%E5%B1%9E%E6%80%A7%EF%BC%88Variable%20Attribute%EF%BC%89%E5%92%8C%E7%B1%BB%E5%9E%8B%E5%B1%9E%E6%80%A7%EF%BC%88Type%20Attribute%EF%BC%89%E3%80%82
-
https://blog.csdn.net/weaiken/article/details/88085360
地址对齐的概念
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。 对齐的作用和原因:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐.其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那 么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。显然在读取效率上下降很多。
参考:
- https://www.cnblogs.com/wuyudong/p/memory-alignment.html
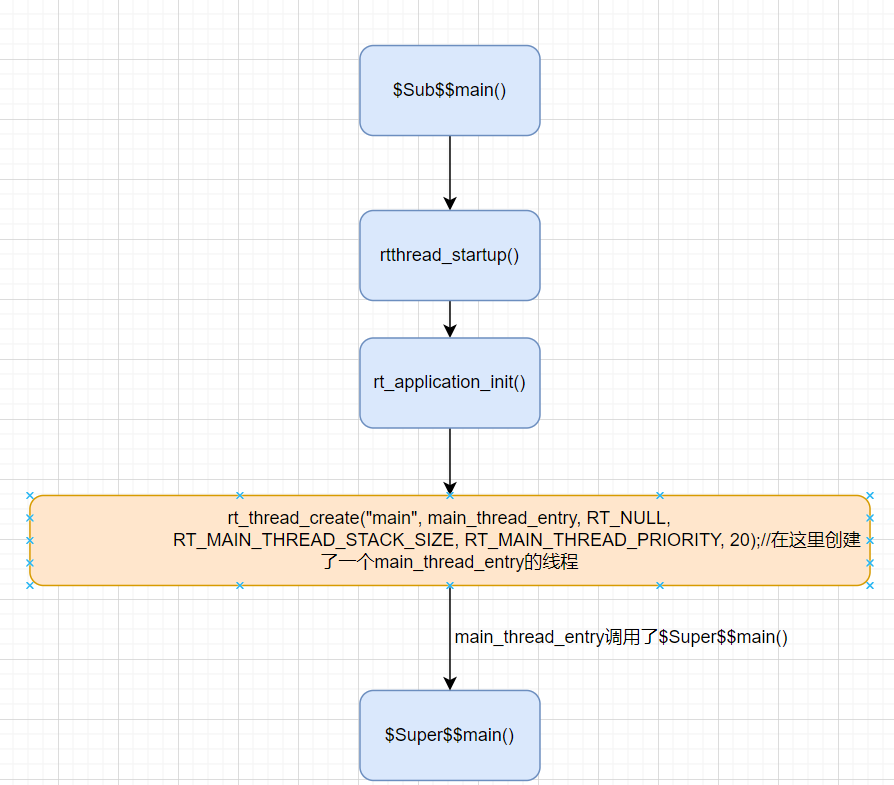
Keil中的 S u p e r Super Super m a i n ( ) 和 main()和 main()和Sub$$main()
因为 RT-Thread 使用编译器(这里仅讲解 KEIL,IAR 或者 GCC 稍微有点区别,但是原理是一样的)自带的 S u b Sub Sub$ 和 S u p e r Super Super$这两个符号来扩展了 main 函数,使用 S u b Sub Sub$main 可以在执行 main 之前先执行 S u b Sub Sub m a i n ,在 main,在 main,在SubKaTeX parse error: Can't use function '$' in math mode at position 56: …ain 函数,这个就通过调用 $̲Supermain 来实现。当需要扩展的函数不是 main 的时候,只需要将 main换成你要扩展的函数名即可,即 S u b Sub Sub$function 和 S u p e r Super Super$function,
在RT-Thread源码中该函数在conponents.c中实现,在conponents.c中关于$Sub$$main与$Super$$main的操作如下
#if defined(__CC_ARM) || defined(__CLANG_ARM)
extern int $Super$$main(void);
/* re-define main function */
int $Sub$$main(void)
{
rtthread_startup();
return 0;
}
int rtthread_startup(void)
{
rt_hw_interrupt_disable();
/* board level initialization
* NOTE: please initialize heap inside board initialization.
*/
rt_hw_board_init();
/* show RT-Thread version */
rt_show_version();
/* timer system initialization */
rt_system_timer_init();
/* scheduler system initialization */
rt_system_scheduler_init();
/* create init_thread */
rt_application_init();//$Super$$main在这个函数中调用
/* timer thread initialization */
rt_system_timer_thread_init();
/* idle thread initialization */
rt_thread_idle_init();
/* start scheduler */
rt_system_scheduler_start();
/* never reach here */
return 0;
}
void rt_application_init(void)
{
rt_thread_t tid;
#ifdef RT_USING_HEAP
tid = rt_thread_create("main", main_thread_entry, RT_NULL,
RT_MAIN_THREAD_STACK_SIZE, RT_MAIN_THREAD_PRIORITY, 20);//在这里创建了一个main_thread_entry的线程
RT_ASSERT(tid != RT_NULL);
#else
rt_err_t result;
tid = &main_thread;
result = rt_thread_init(tid, "main", main_thread_entry, RT_NULL,
main_stack, sizeof(main_stack), RT_MAIN_THREAD_PRIORITY, 20);
RT_ASSERT(result == RT_EOK);
/* if not define RT_USING_HEAP, using to eliminate the warning */
(void)result;
#endif
rt_thread_startup(tid);
}
void main_thread_entry(void *parameter)
{
extern int main(void);
extern int $Super$$main(void);
#ifdef RT_USING_COMPONENTS_INIT
/* RT-Thread components initialization */
rt_components_init();
#endif
/* invoke system main function */
#if defined(__CC_ARM) || defined(__CLANG_ARM)//这里调用了$Super$$main();
$Super$$main(); /* for ARMCC. */
#elif defined(__ICCARM__) || defined(__GNUC__)
main();
#endif
}
main函数调用的流程如下: