目录
- 一、RNN简介
- 二、RNN Cell用法
- 三、RNN用法
- 三、实例:hello换序
- 1.RNN Cell
- 2.RNN
- 四、Embedding
一、RNN简介
RNN网络最大的特点就是可以处理序列特征,就是我们的一组动态特征。比如,我们可以通过将前三天每天的特征(是否下雨,是否有太阳等)输入到网络,从而来预测第四天的天气。
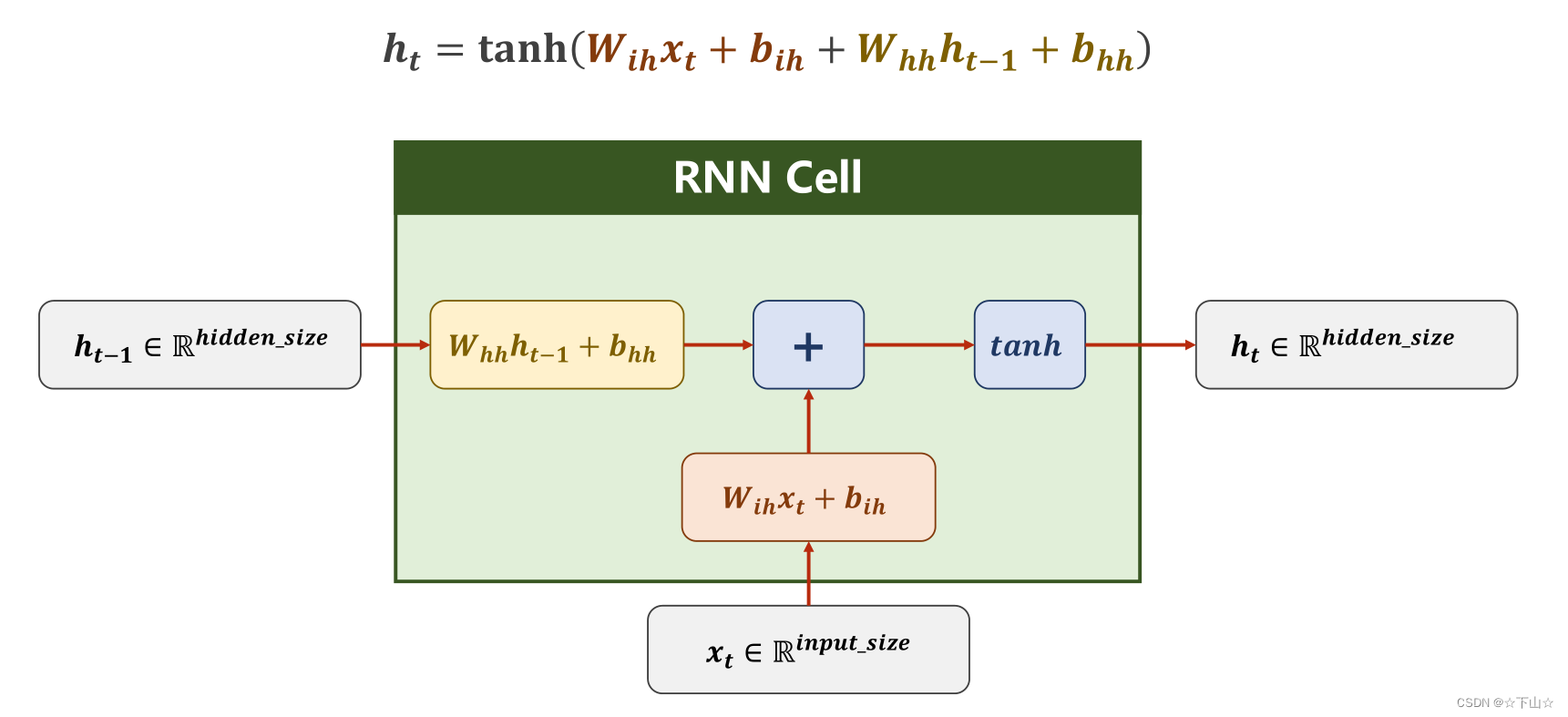
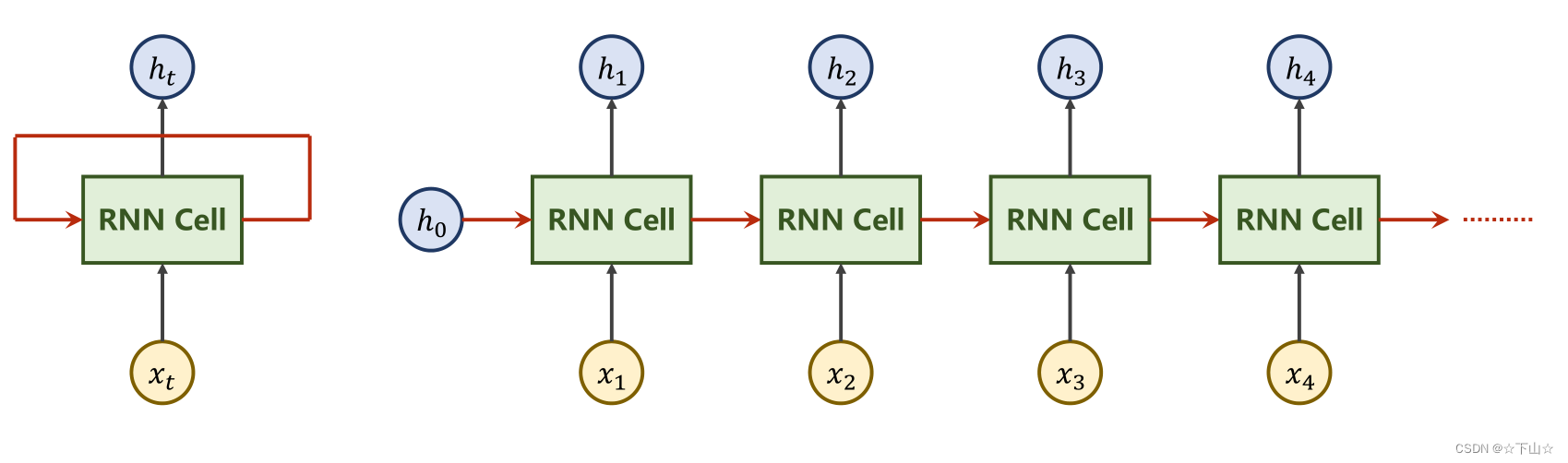
我们可以看RNN的网络结构如下:
二、RNN Cell用法
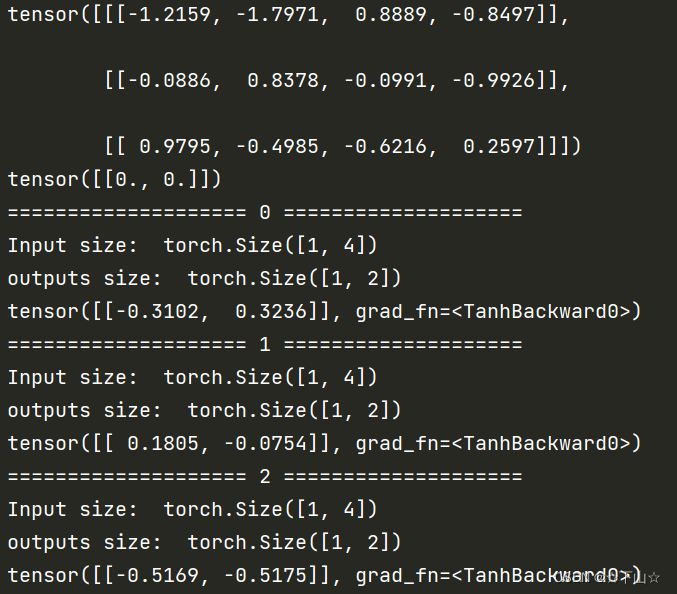
import torch
batch_size = 1 # 批处理大小
seq_len = 3 # 序列长度
input_size = 4 # 输入维度
hidden_size = 2 # 隐藏层维度
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
# (seq, batch, features)
dataset = torch.randn(seq_len, batch_size, input_size)
print(dataset)
hidden = torch.zeros(batch_size, hidden_size)
print(hidden)
for idx, input in enumerate(dataset):
print( '=' * 20, idx, '=' * 20)
print( 'Input size: ', input.shape)
hidden = cell(input, hidden)
print( 'outputs size: ', hidden.shape)
print(hidden)
三、RNN用法
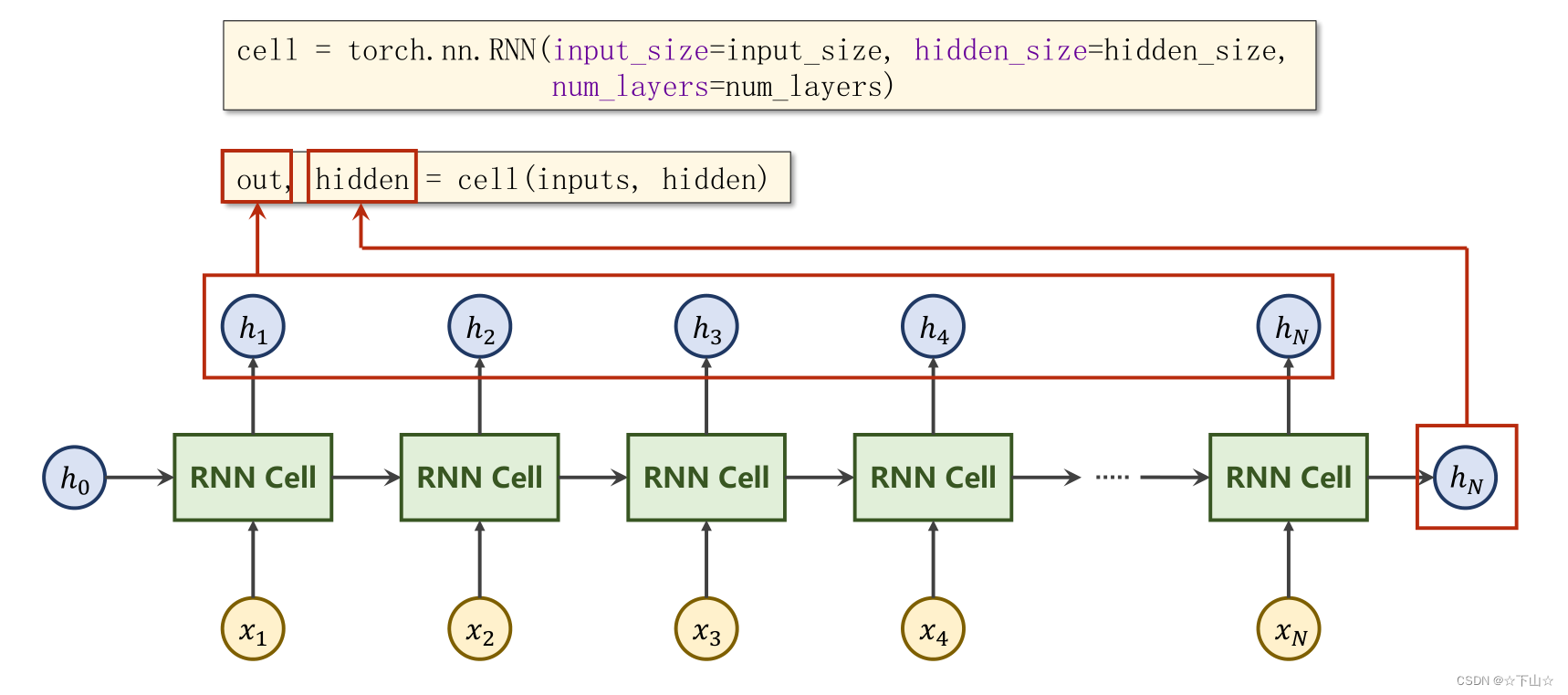
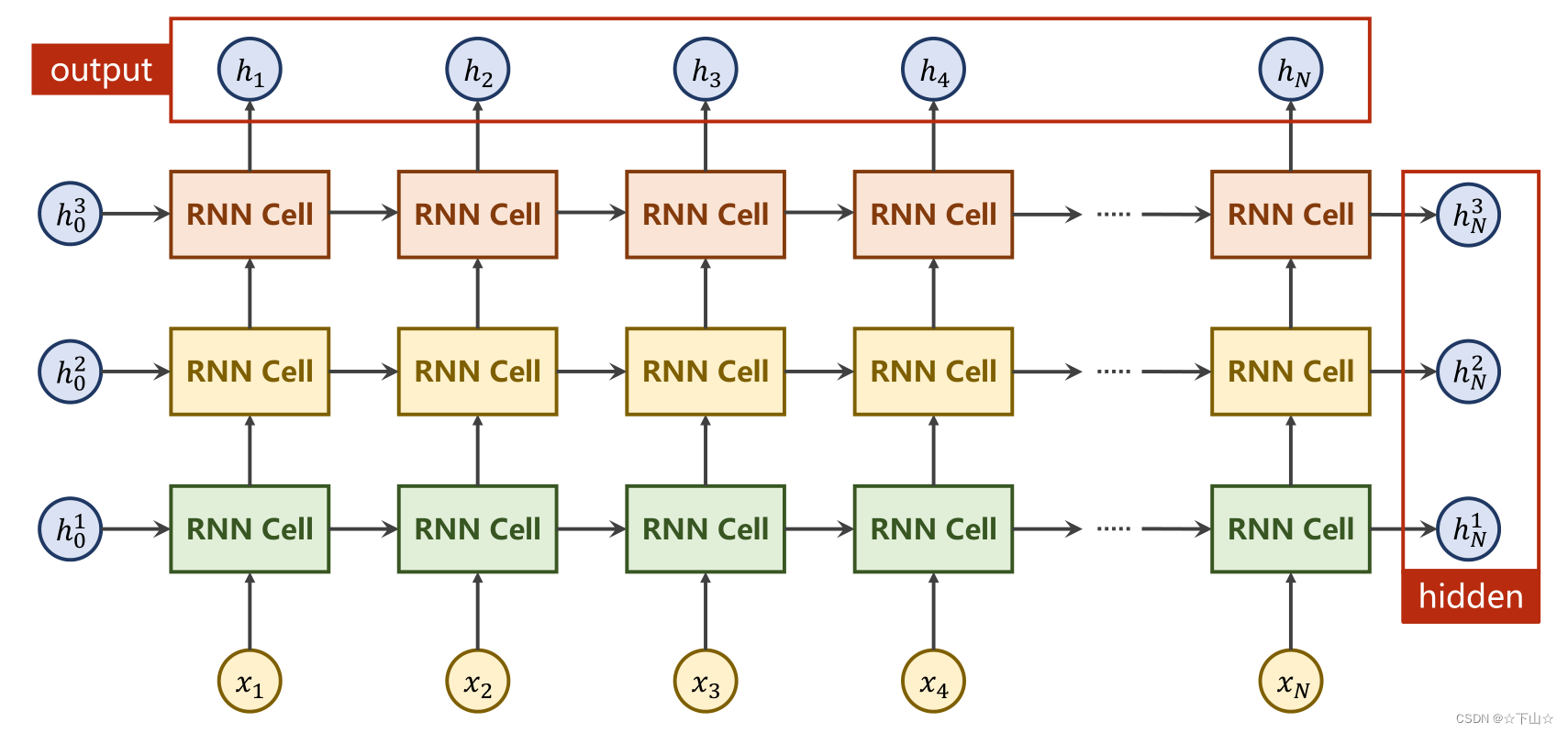
import torch
batch_size = 1 # 批处理大小
seq_len = 3 # 序列长度
input_size = 4 # 输入维度
hidden_size = 2 # 隐藏层维度
num_layers = 4 # 隐藏层数量
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
# (seqLen, batchSize, inputSize)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
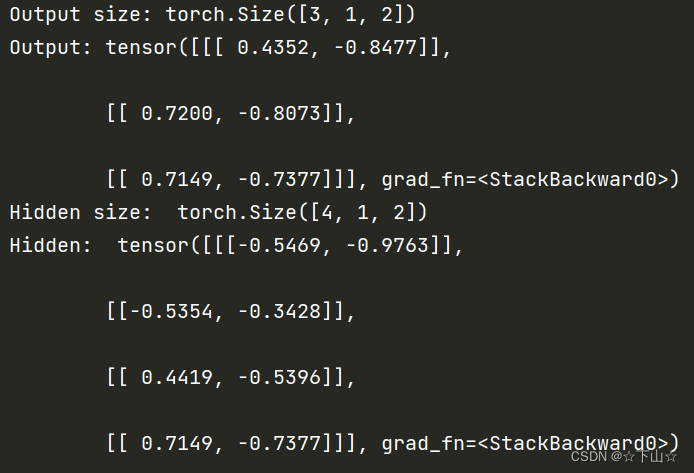
out, hidden = cell(inputs, hidden)
print( 'Output size:', out.shape)
print( 'Output:', out)
print( 'Hidden size: ', hidden.shape)
print( 'Hidden: ', hidden)
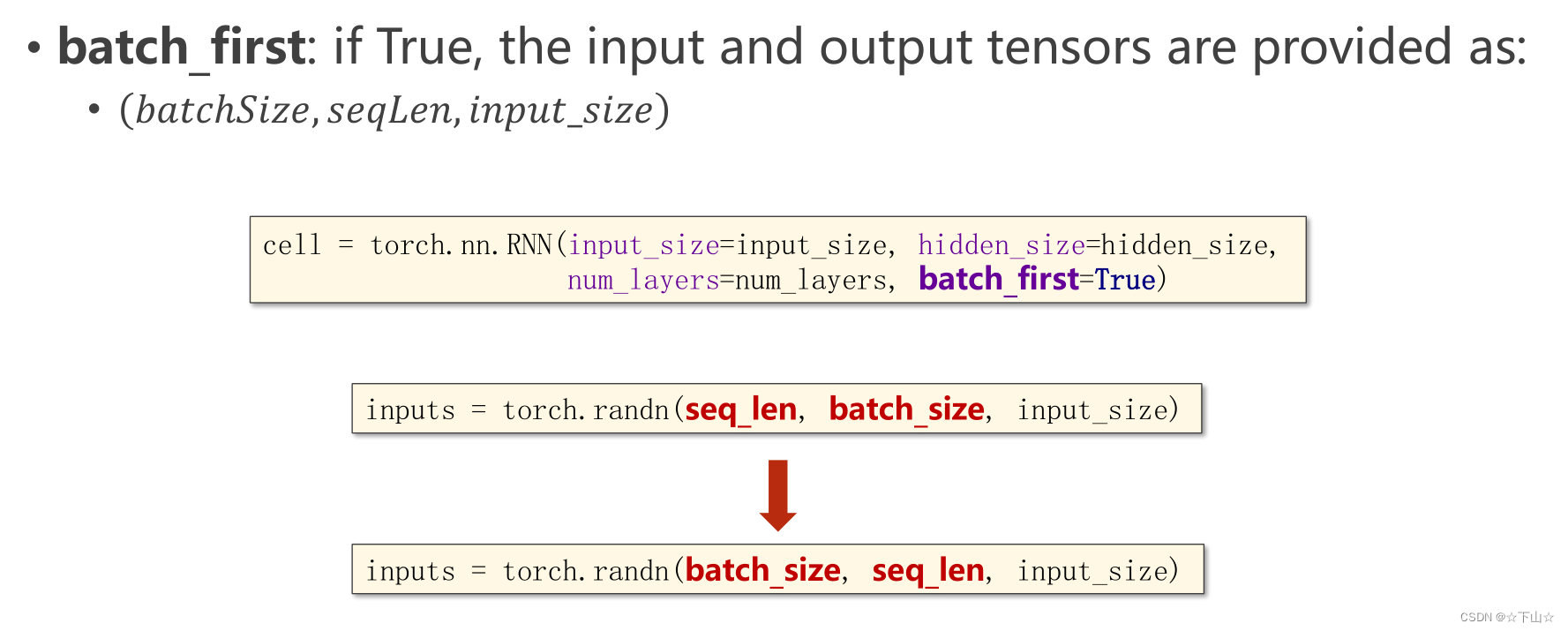
batch_first参数:
三、实例:hello换序
任务描述:我们需要训练一个模型,输入是“hello”,使输出是“ohlol”。如下图所示:

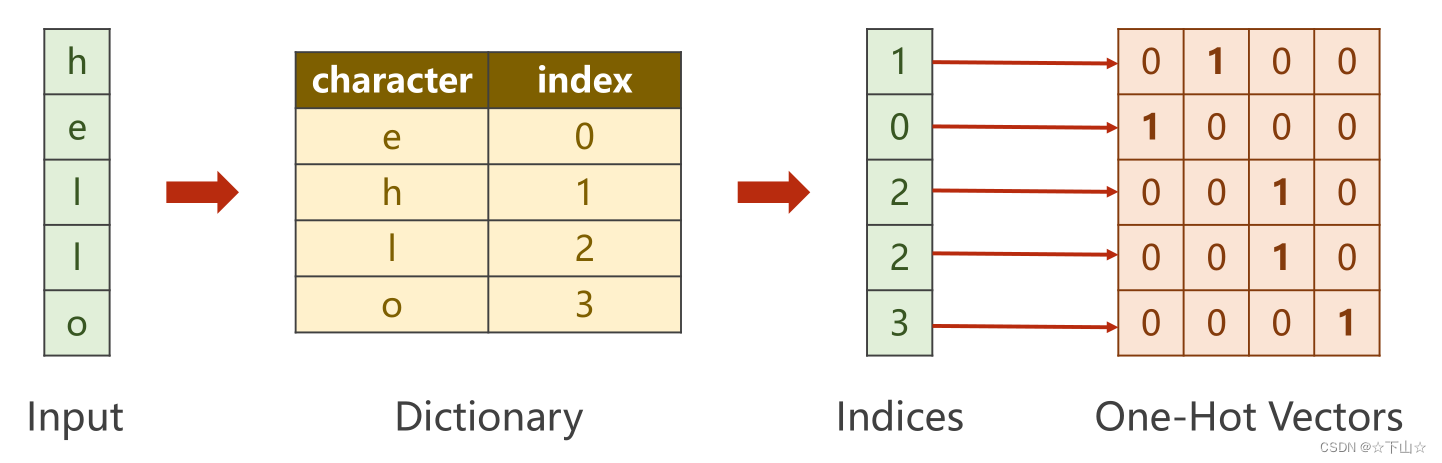
方法描述:首先我们可以将“hello”中每个字母对应一个索引,之后得到输入“hello”和输出“ohlol”的编码分别为10223和31232。对编码中的每一个数字,都可以转换成一个四维张量(通过在对应张量对应索引填充为1,其余填充为0),如下图所示。这样我们的输入序列有5个元素,每个元素的维度为4。
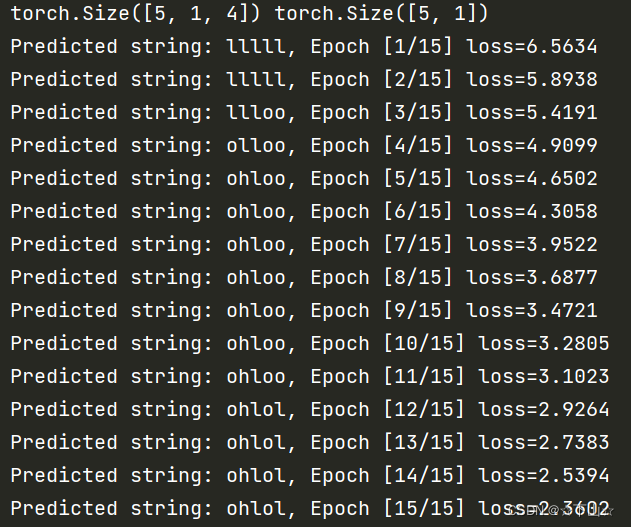
1.RNN Cell
import torch
input_size = 4 # 输入维度,每个字母对应张量维度
hidden_size = 4
batch_size = 1
# 准备数据集
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 3, 3] # hello对应编码
y_data = [3, 1, 2, 3, 2] # ohlol对应编码
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
print(inputs.shape, labels.shape)
# 构建模型
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, inputs, hidden):
hidden = self.rnncell(inputs, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
# 损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
# 训练
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print( 'Predicted string: ', end= '')
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end= '')
loss.backward()
optimizer.step()
print( ', Epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))
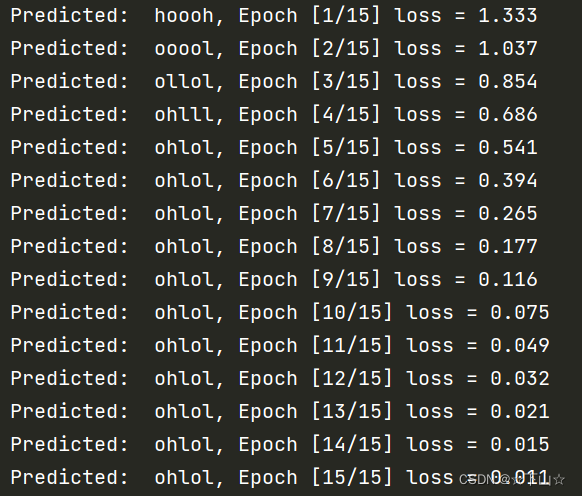
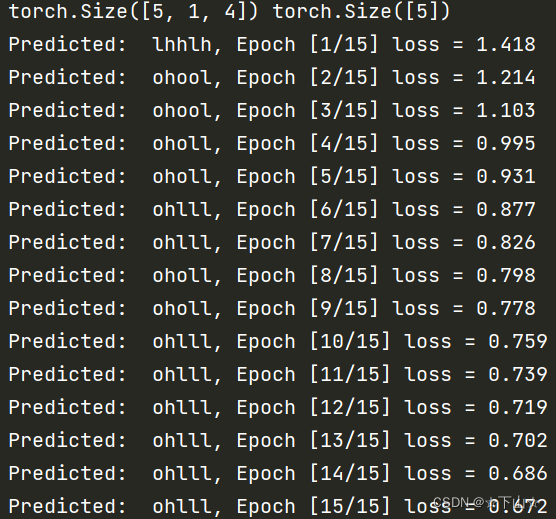
2.RNN
import torch
input_size = 4
hidden_size = 4
batch_size = 1
seq_len = 5
num_layers = 1
# 准备数据集
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 3, 3] # hello对应编码
y_data = [3, 1, 2, 3, 2] # ohlol对应编码
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
print(inputs.shape, labels.shape)
# 构建模型
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, )
def forward(self, inputs):
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
out, _ = self.rnn(inputs, hidden) # 注意维度是(seqLen, batch_size, hidden_size)
return out.view(-1, self.hidden_size) # 为了容易计算交叉熵这里调整维度为(seqLen * batch_size, hidden_size)
net = Model(input_size, hidden_size, batch_size)
# 损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
# 训练
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
# print(outputs.shape, labels.shape)
# 这里的outputs维度是([seqLen * batch_size, hidden]), labels维度是([seqLen])
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
四、Embedding
-
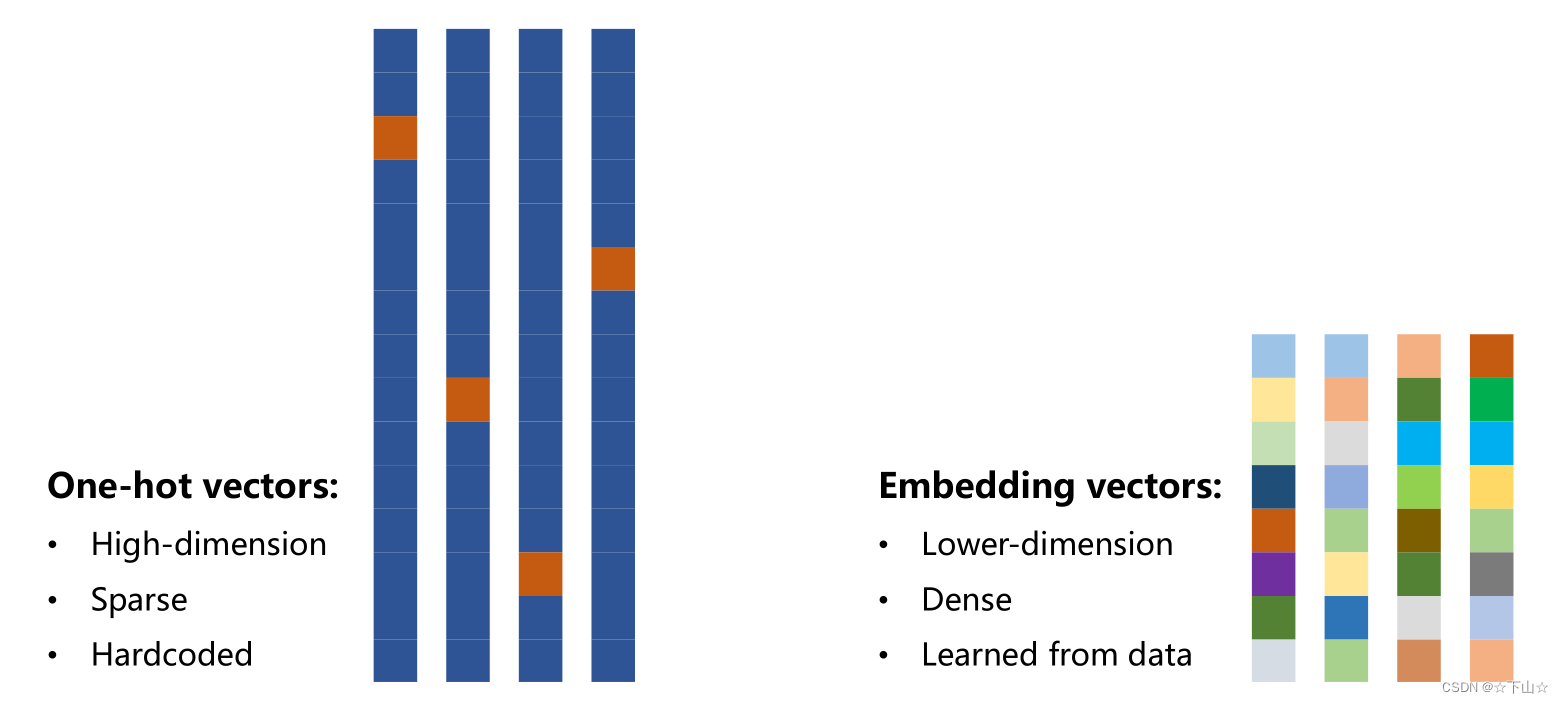
One-hot encoding of words and characters:
(1) The one-hot vectors are high-dimension.
(2) The one-hot vectors are sparse.
(3) The one-hot vectors are hardcoded. -
Do we have a way to associate a vector with a word/character with following specification:
(1) Lower-dimension
(2) Dense
(3) Learned from data -
A popular and powerful way is called EMBEDDING.
我们使用embedding将模型变成如下所示:
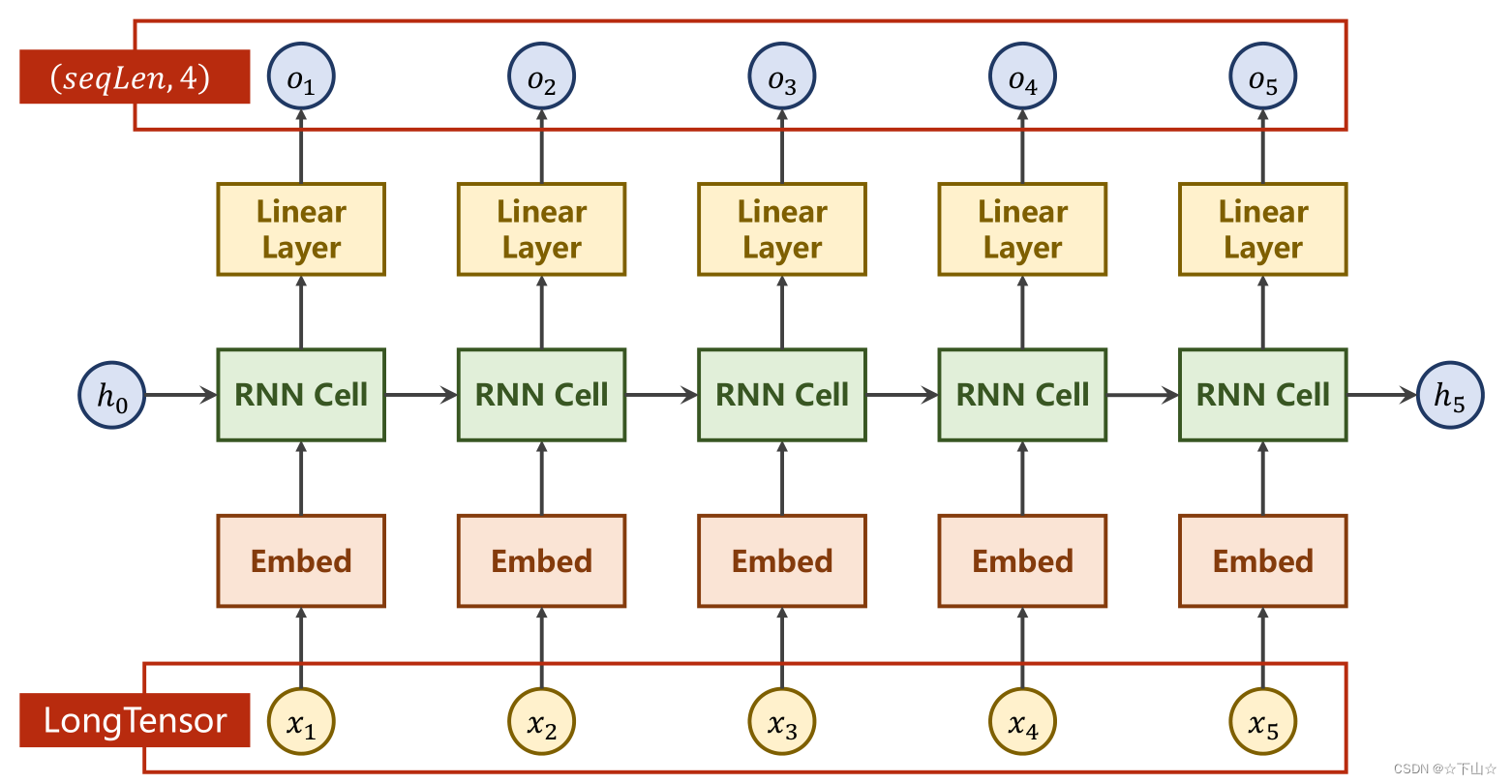
import torch
# parameters
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
# 准备数据集
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # (batch, seq_len)
y_data = [3, 1, 2, 3, 2] # (batch * seq_len)
inputs = torch.LongTensor(x_data) # Input should be LongTensor: (batchSize, seqLen)
labels = torch.LongTensor(y_data) # Target should be LongTensor: (batchSize * seqLen)
# 构建模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x) # (batch, seqLen, embeddingSize)
x, _ = self.rnn(x, hidden) # 输出(𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆, 𝒔𝒆𝒒𝑳𝒆𝒏, hidden_size)
x = self.fc(x) # 输出(𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆, 𝒔𝒆𝒒𝑳𝒆𝒏, 𝒏𝒖𝒎𝑪𝒍𝒂𝒔𝒔)
return x.view(-1, num_class) # reshape to use Cross Entropy: (𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆×𝒔𝒆𝒒𝑳𝒆𝒏, 𝒏𝒖𝒎𝑪𝒍𝒂𝒔𝒔)
net = Model()
# 损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
# 训练模型
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))