Auto-Encoder (AE)
Auto-encoder概念
自编码器要做的事:将高维的信息通过encoder压缩到一个低维的code内,然后再使用decoder对其进行重建。“自”不是自动,而是自己训练[1]。
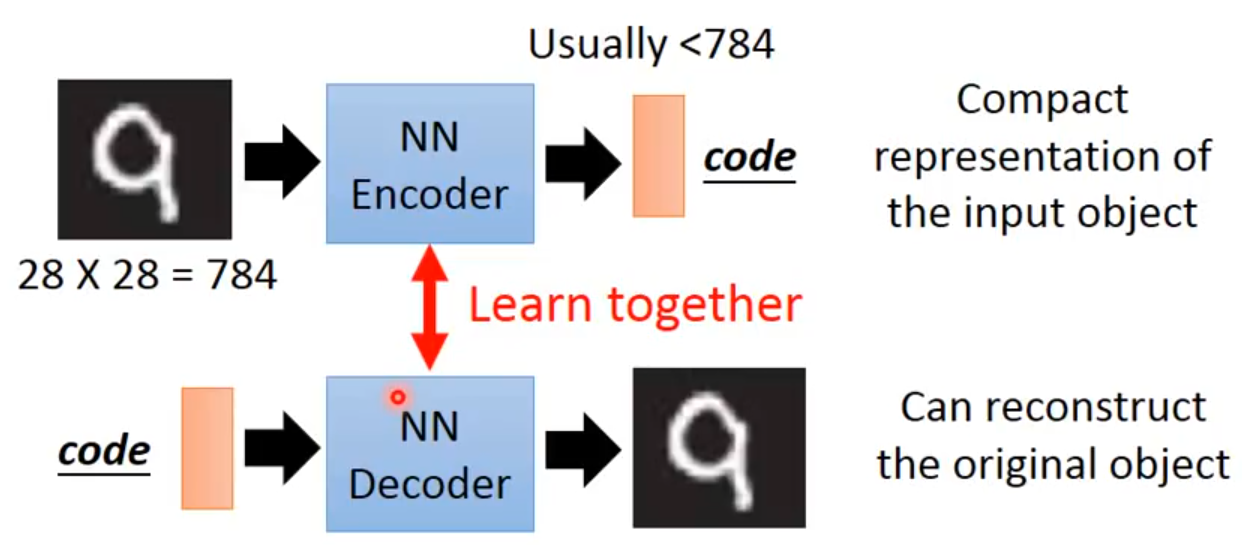
PCA要做的事其实与AE一样,只是没有神经网络。对于一个输入x,PCA通过一个转换矩阵W将x转换为c,因为是线性的过程,就可以再通过WT将其转换为x^,目的是使x和x^尽可能一致。而AE要做的就是,在这样一个过程中,将PCA的转换矩阵W,WT换成encoder和decoder。

在这样一个过程中,将input layer, bottleneck, output layer 换做深度神经网络,就变成了deep auto-encoder,最开始由hinton 在2006年提出,这一替换的明显好处是,引入了神经网络强大的拟合能力,使得编码(Code)的维度能够比原始图像(X)的维度低非常多。

在一个手写数字图像的生成模型中,这样的一个简单的Deep Auto-Encoder模型能够把一个784维的向量(28*28图像)压缩到只有30维,并且解码回的图像具备清楚的辨认度(如下图)[2]。
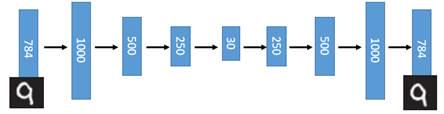
Auto-encoder的应用
Auto-encoder也可以用于预训练 DNN:当labeled data比较少的时候,对前几层网络进行合适的initialization是有必要的,这是可以先用 unlabelled data 使用AE技术分别train并fix W1,W2,W3,最后只需要使用label data训练W4即可。

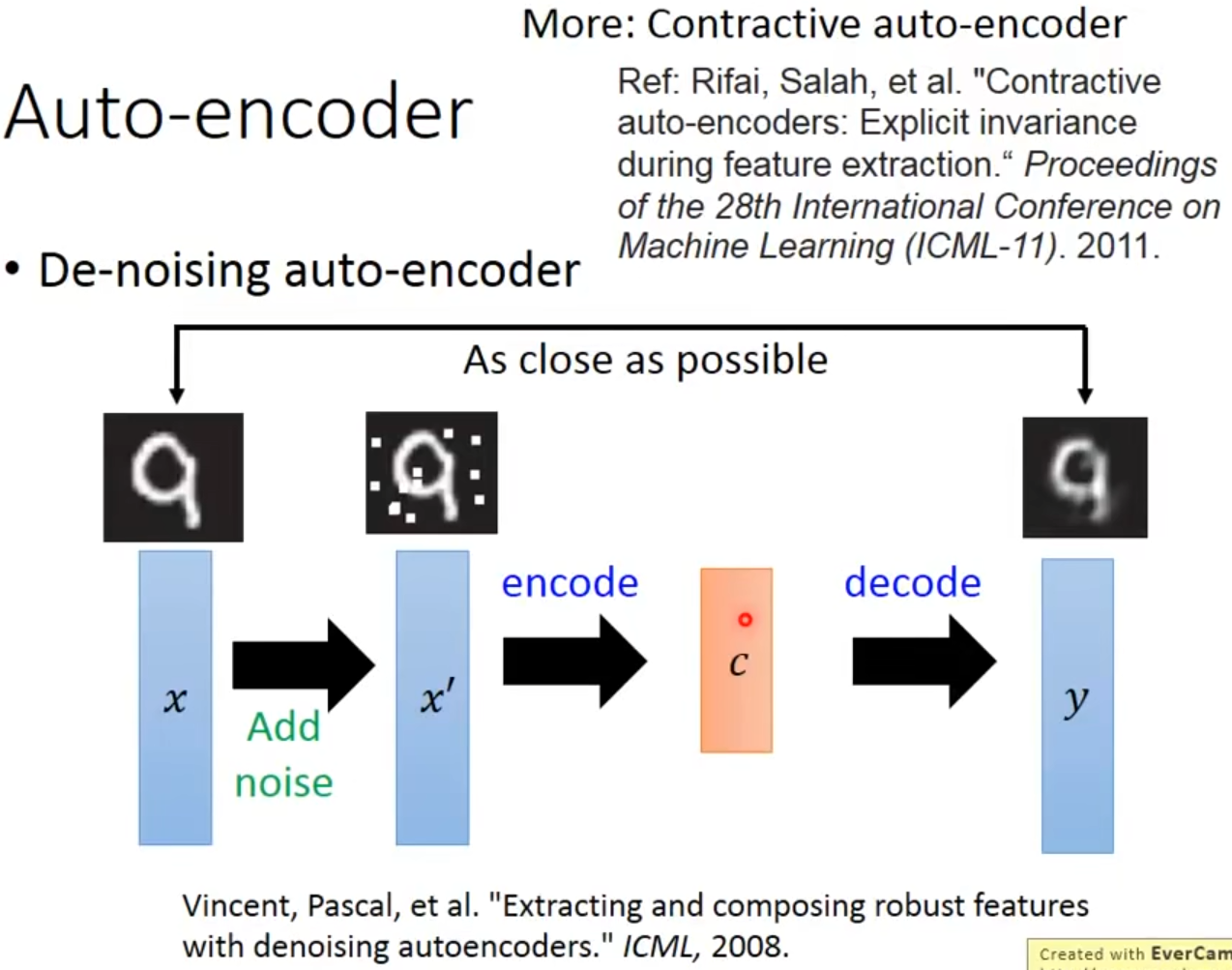
Auto-encoder还可以用来降噪:首先加噪,然后进行AE,目的是使网络不仅可以重构,还可以过滤其中的noise。过程如下。
Auto-encoder for CNN
在CNN中应用auto-encoder,主要是先使用convolution和pooling降维,然后再使用deconvolution和unpooling升维。deconvolution叫做逆卷积,也是一个卷积操作,其对feature map恢复的原理核心就是(k-1-p)扩展(padding),详细可以阅读:Deconvolution(逆卷积)。unpooling与upsampling还是有点区别,unpooling是在CNN中常用的来表示max pooling的逆操作,简单来说,记住做max pooling的时候的最大item的位置,比如一个3x3的矩阵,max pooling的size为2x2,stride为1,反卷积记住其位置,unpooling的操作就是让其余位置至为0就行。

Variational Auto-Encoder (VAE)
#TODO: 阅读:http://www.gwylab.com/note-vae.html
#TODO: 阅读:https://blog.rexking6.top/2019/06/09/%E5%8F%98%E5%88%86%E8%87%AA%E7%BC%96%E7%A0%81%E5%99%A8VAE/,并阅读其中转载的几篇文章
#TODO: KL散度
#TODO: 贝叶斯估计
参考:
[1] https://www.bilibili.com/video/av15889450/?p=33
[2] http://www.gwylab.com/note-vae.html