文章目录
- 1. 事务的定义
- 2. Spring 中事务的实现
- 2.1 MySQL 中使用事务
- 2.2 Spring 中编程式事务的实现
- 2.3 Spring 中声明式事务
- 2.3.1 声明式事务的实现 @Transactional
- 2.3.2 @Transactional 作用域
- 2.3.3@Transactional 参数设置
- 2.3.4 @Transactional 异常情况
- 2.3.5 @Transactional 工作原理
- 3. 事务隔离级别
- 3.1 事务特性
- 3.2 Spring 中设置事务隔离级别
- 4. Spring 事务传播机制
- 4.1 事务传播机制是什么
- 4.2 为什么需要事务传播机制
- 4.3 事务传播机制有哪些
- 4.4 Spring 事务传播机制使用
- 4.4.1 支持当前事务(REQUIRED 默认)
- 4.4.2 不支持当前事务(REQUIRES_NEW)
- 4.4.3 不支持当前事务(NOT_SUPPORTED)
- 4.4.4 NESTED 嵌套事务
- 4.4.5 嵌套事务和加入事务的区别
本篇重点总结:
- 在 Spring 项目中使用事务,有两种方式:编程式手动操作和声明式自动提交,声明式自动提交使用最多,只需要在方法上添加注解 @Transactional
- 设置事务的隔离级别 @Transactional(isolation = Isolation.SERIALIZABLE),Spring 中的事务隔离级别有5种
- 设置事务的传播机制 @Transactional(propagation = Propagation.REQUIRED),Spring 中的事务传播级别有 7 种
1. 事务的定义
事务定义:将一组操作封装成一个执行单元(封装到一起),要么全部成功,要么全部失败
那么为什么要用事务呢
比如两个银行账户之间的转账操作:
- 第一步操作:A 账户 -100 元
- 第二步操作:B 账户 +100 元
如果没有事务。第一步执行成功了,第二步执行失败了,那么 A 账号就丢失了 100 元,而如果使用事务就可以解决这个问题,让这一组操作要么一起成功,要么一起失败
2. Spring 中事务的实现
Sping 中事务的操作用两种:
- 编程式事务(手写代码操作事务)
- 声明式事务(利用注解自动开启和提交事务)
2.1 MySQL 中使用事务
MySQL 中事务有 3 个重要的操作:开启事务、提交事务、回滚事务,它们对应的操作命令如下
-- 开启事务
start transaction;
-- 业务执⾏
-- 提交事务
commit;
-- 回滚事务
rollback;
2.2 Spring 中编程式事务的实现
Spring 中手动操作事务和 MySQL操作事务类似,也是有 3 个重要操作
- 开启事务(获取事务)
- 提交事务
- 回滚事务
Spring Boot 内置了两个对象,DataSourceTransactionManager (事务管理器)用来获取事务(开启事务)、提交或回滚事务的,而 TransactionDefinition 是事务的属性,在获取事务的时候需要将 TransactionDefinition 传递进去从而获得一个事务 TransactionStatus 对象
@RestController
public class UserController {
@Autowired
private UserService userService;
@Autowired
private DataSourceTransactionManager transactionManager;
@Autowired
private TransactionDefinition transactionDefinition;
// 在此方法中使用编程式的事物
@RequestMapping("/add")
public int add(UserInfo userInfo) {
// 非空效验【验证用户名和密码不为空】
if(userInfo==null || !StringUtils.hasLength(userInfo.getUsername())
|| !StringUtils.hasLength(userInfo.getPassword())) {
return 0;
}
// 开启事务(获取事务)
TransactionStatus transactionStatus = transactionManager.getTransaction(transactionDefinition);
int result = userService.add(userInfo);
System.out.println("add 受影响的行数:" + result);
// 提交事务
transactionManager.commit(transactionStatus);
// // 回滚事务
// transactionManager.rollback(transactionStatus);
return result;
}
}
运行程序分别查看提交事务和回滚事务的效果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CDdDwGaw-1676374722301)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676287772298.png)]](https://img-blog.csdnimg.cn/7b15deb5bae6435e84ce0ddd7b3d8ece.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y3cm5944-1676374722302)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676287783586.png)]](https://img-blog.csdnimg.cn/f29367abeea441659e1dd211316df6c1.png)
2.3 Spring 中声明式事务
2.3.1 声明式事务的实现 @Transactional
声明式事务的实现,只需要在方法上添加 @Transactional 注解就可以实现,无序手动开启事务和提交事务,进入方法时自动开启事务,方法执行完全会自动提交事务,如果中途发生了没有处理的异常会自动回滚事务
// 在此方法中使用声明式的事物
// 在进入方法之前,自动开启事务,在方法之前完后,自动提交事务,如果出现异常,则自动回滚事务
@Transactional
@RequestMapping("/add2")
public int add2(UserInfo userInfo) {
if(userInfo==null || !StringUtils.hasLength(userInfo.getUsername())
|| !StringUtils.hasLength(userInfo.getPassword())) {
return 0;
}
int result = userService.add(userInfo);
System.out.println("add2 受影响的行数:" + result);
int num = 10/0;
return result;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S21gpiHu-1676374722303)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676288819713.png)]](https://img-blog.csdnimg.cn/edfafdcdc46c44489736d1eaec8ec12c.png)
去除异常的那行代码重新运行程序
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Vx76KGj-1676374722303)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676289003919.png)]](https://img-blog.csdnimg.cn/c518198bb0094216b9da591ce7a8984f.png)
2.3.2 @Transactional 作用域
@Transactional 可以用来修饰方法或类:
- 修饰方法时,只能应用到 public 方法上,否则不生效
- 修饰类时,说明该注解对该类中所有的 public 方法都生效
2.3.3@Transactional 参数设置
| 参数 | 作用 |
|---|---|
| value | 当你配置多个事务管理器时,可以使用该属性指定选择用哪个事务管理器 |
| transactionManager | 同上 |
| propagation | 事务的传播行为,默认值为 Propagation.REQUIRED |
| isolation | 事务的隔离级别,默认值为 Isolation.DEFAULT |
| timeout | 事务的超时时间,默认值为-1,如果超过该时间限制但事务还没完成,则自动回滚事务 |
| readOnly | 指定事务是否为只读事务,默认值为 false,为了忽略那些不需要事务的方法,比如读取数据可以设置 read-only 为 true |
| rolibackFor | 用于指定能够触发事务回滚的异常类型,可以指定多个异常类型 |
| rolibackForClassName | 同上 |
| noRolibackFor | 抛出指定的异常类型,不回滚事务,也可以指定多个异常类型 |
| noRollbackForClassName | 同上 |
设置事务的隔离级别
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ibpM3tny-1676374722304)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676292506013.png)]](https://img-blog.csdnimg.cn/690cdff0ba8143a3a6d5d9d9006d1d55.png)
设置事务的超时时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NIxWwKWm-1676374722304)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676293014348.png)]](https://img-blog.csdnimg.cn/7aa5e93a539a4e2da0c7e2e95f5c1717.png)
2.3.4 @Transactional 异常情况
@Transactional 在异常被捕获的情况下,不会进⾏事务⾃动回滚
@Transactional
@RequestMapping("/add3")
public int add3(UserInfo userInfo) {
if(userInfo==null || !StringUtils.hasLength(userInfo.getUsername())
|| !StringUtils.hasLength(userInfo.getPassword())) {
return 0;
}
int result = userService.add(userInfo);
System.out.println("add2 受影响的行数:" + result);
try {
int num = 10/0;
} catch (Exception e) {
}
return result;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ueCyvrWj-1676374722305)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676356422586.png)]](https://img-blog.csdnimg.cn/75678e7732094e52bf196c3e42fe1623.png)
解决方法1:将异常重新抛出去
对于捕获的异常,事务是会⾃动回滚的,因此解决⽅案1就是将异常重新抛出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y0emxEE9-1676374722306)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676356654556.png)]](https://img-blog.csdnimg.cn/45912c55eb5c4901a9a185986f014af0.png)
解决方法2:使用代码的方式手动回滚当前事务
手动回滚事务,在⽅法中使⽤ TransactionAspectSupport.currentTransactionStatus() 可以得到当前的事务,然后设置回滚方法 setRollbackOnly 就可以实现回滚了,具体实现代码
@Transactional
@RequestMapping("/add3")
public int add3(UserInfo userInfo) {
if(userInfo==null || !StringUtils.hasLength(userInfo.getUsername())
|| !StringUtils.hasLength(userInfo.getPassword())) {
return 0;
}
int result = userService.add(userInfo);
System.out.println("add2 受影响的行数:" + result);
try {
int num = 10/0;
} catch (Exception e) {
//手动回滚事务
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
}
return result;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X3KVRTil-1676374722306)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676356967349.png)]](https://img-blog.csdnimg.cn/417e21b1a4804d4586917c0515030f88.png)
2.3.5 @Transactional 工作原理
@Transactional 是基于 AOP 实现的,AOP 又是使用动态代理来实现的。如果目标对象实现了接口,默认情况下采用 JDK 的动态代理,如果目标对象没有实现接口,会使用 CGLIB 动态代理。@Transactional 在开始执行业务之前,通过代理先开启事务,在执行成功之后再提交事务,如果中途遇到异常,则回滚事务
@Transactional 实现思路
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U53Wzj7E-1676374722307)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676358204440.png)]](https://img-blog.csdnimg.cn/21db7f254e46456dbaf1e165cde2480a.png)
@Transactional 具体执行细节
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2L3MlAy7-1676374722308)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676358241159.png)]](https://img-blog.csdnimg.cn/704662ba606e43598028475a379cd3e0.png)
3. 事务隔离级别
3.1 事务特性
事务有四大特性(ACID),原子性、持久性、一致性和隔离性
- 原子性(Atomicity):一个事务中的所有操作,要么全部完成,要么全部不完成。不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态
- 一致性(Consistency):在事务开始之前和事务事务结束之后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精准度、串联性以及后续数据库可以自发性地完成预定的工作
- 持久性(Isolation):事务处理结束后,对数据的修改就是永久的。即使系统故障也不会丢失
- 隔离性(Durability):数据库允许多个并发事务同时对其数据进行读写和修改的能力。隔离性可以防止多个事务并发执行时由交叉执行而导致数据的不一致。
这四个特性中,只有隔离性(隔离级别)是可以设置的
3.2 Spring 中设置事务隔离级别
为什么要设置事务的隔离级别
设置事务的隔离级别是用来保障多个并发事务执行更可控,更符合操作者预期的
这个可控表示的是,比如疫情的时候,有确诊、密接、次密接等针对不同的人群,采取不同的隔离级别,这种方式与事务的隔离级别类似,都是让某种行为操作变的 更可控,事务的隔离级别就是为了防止,其他事务影响当前事务执行的一种策略
MySQL 事务隔离级别有 4 种
- 读未提交(READ UNCOMMITTED ):事务A读到了事务B没有提交的数据,然后过了一会事务B进行了回滚,此时**事务A的这个情况就叫脏读,读到的数据也叫脏数据,读未提交侧重于查询,**既然有了脏读,那么也肯定有不可重复读和幻读的问题
- 读已提交(READ COMMITTED):针对上面脏读的问题来解决的,事务A读到了事务B已经提交的数据,然后过了一会事务B将提交的数据进行修改了,此时事务A又读了一次B的数据,发现两次读到读到数据不一样,这个就叫不可重复读的问题,读已提交侧重的是修改,还是存在不可重复读和幻读的问题
- 可重复读(REPEATABLE READ) :针对的是上面不可重复读的问题,事务A此时查询数据发现表中只有一条数据,然后事务B又过来拆台了,事务B又插入了一条数据,事务A再次查询发现,哎!我出现幻觉了吗,刚刚不是只有一条数据么,现在咋又变成了两条数据了,是出现幻觉了吗,这个问题就叫 幻读,可重复读侧重的是添加和删除,只存在幻读的问题了
- 串行化(SERIALIZABLE):事务最高的隔离级别,解决了脏读、不可重复读、幻读的问题,但这个级别执行效率低
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(READ UNCOMMITTED) | √ | √ | √ |
| 读已提交(READ COMMITTED) | √ | √ | |
| 可重复读(REPEATABLE READ) | √ | ||
| 串行化(SERIALIZABLE) |
Spring 中事务隔离级别有 5 种
多了一个默认事务隔离级别 DEFAULT 以连接的数据库事务隔离级别为准,如果连接的是 MySQL 那么默认就是 可重复读
注意事项:
- 当 Spring 中设置了事务隔离级别和连接的数据库(MySQL)事务隔离级别发送冲突的时候,以Spring为准
- Spring 中的事务隔离级别机制的实现是依靠连接数据库支持事务隔离级别为基础
Spring 中事务隔离级别可以通过 @Transactional 中的 isolation 属性进行设置
4. Spring 事务传播机制
4.1 事务传播机制是什么
Spring 事务传播机制:多个事务在相互调用时,事务是如何传递的
4.2 为什么需要事务传播机制
事务隔离级别是保证多个并发事务执⾏的可控性的(稳定性的),⽽事务传播机制是保证⼀个事务在多个调⽤⽅法间的可控性的(稳定性的)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nl69KKT9-1676374722309)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676361930104.png)]](https://img-blog.csdnimg.cn/8bd9584e0af346958f6e06f5ee0c1133.png)
4.3 事务传播机制有哪些
事务的传播机制有 7 种:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pvcupysn-1676374722309)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676362237124.png)]](https://img-blog.csdnimg.cn/a1b28021c25643c88539506abfe3dc1a.png)
- Propagation.REQUIRED:默认的事务传播级别,它表示如果当前存在事务,则加入事务;如果当前没有事务,则创建一个新的事务
- Propagation.SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行
- Propagation.MANDATORY;(mandatory 强制性)如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常
- Propagation.REQUIRES_ENW:表示创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW 修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰
- Propagation.NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起
- Propagation.NEVER:以非事务方式运行,如果当前存在事务,则抛出异常
- Propagation.NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 PROPAGATION_REQUIRED
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LNBCGXn4-1676374722310)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676364699386.png)]](https://img-blog.csdnimg.cn/0ddf624fe3e243faa4d92d5780260335.png)
4.4 Spring 事务传播机制使用
4.4.1 支持当前事务(REQUIRED 默认)
在mycnblog数据库中,先创建一个表
mysql> create table loginfo(
-> id int primary key auto_increment,
-> name varchar(250),
-> `desc` text,
-> createtime datetime default CURRENT_TIMESTAMP);
Query OK, 0 rows affected (0.04 sec)
mysql> desc loginfo;
+------------+--------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+-----+-------------------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(250) | YES | | NULL | |
| desc | text | YES | | NULL | |
| createtime | datetime | YES | | CURRENT_TIMESTAMP | |
+------------+--------------+------+-----+-------------------+----------------+
4 rows in set (0.00 sec)
以下代码实现中,先开启事务先成功插入一条用户数据,然后再执行日志报错,而在日志报错是发生了异常,观察 propagation = Propagation.REQUIRED 的执行结果
@RestController
public class UserController {
@Autowired
private UserService userService;
@Autowired
private LogService logService;
@Transactional(propagation = Propagation.REQUIRED)
@RequestMapping("/add4")
public int add4(UserInfo userInfo) {
if(userInfo == null || !StringUtils.hasLength(userInfo.getUsername())
|| !StringUtils.hasLength(userInfo.getPassword())) {
return 0;
}
int userResult = userService.add(userInfo);
System.out.println("添加用户:" + userResult);
LogInfo logInfo = new LogInfo();
logInfo.setName("添加用户");
logInfo.setDesc("添加用户结果:" + userResult);
int logResult = logService.add(logInfo);
return userResult;
}
}
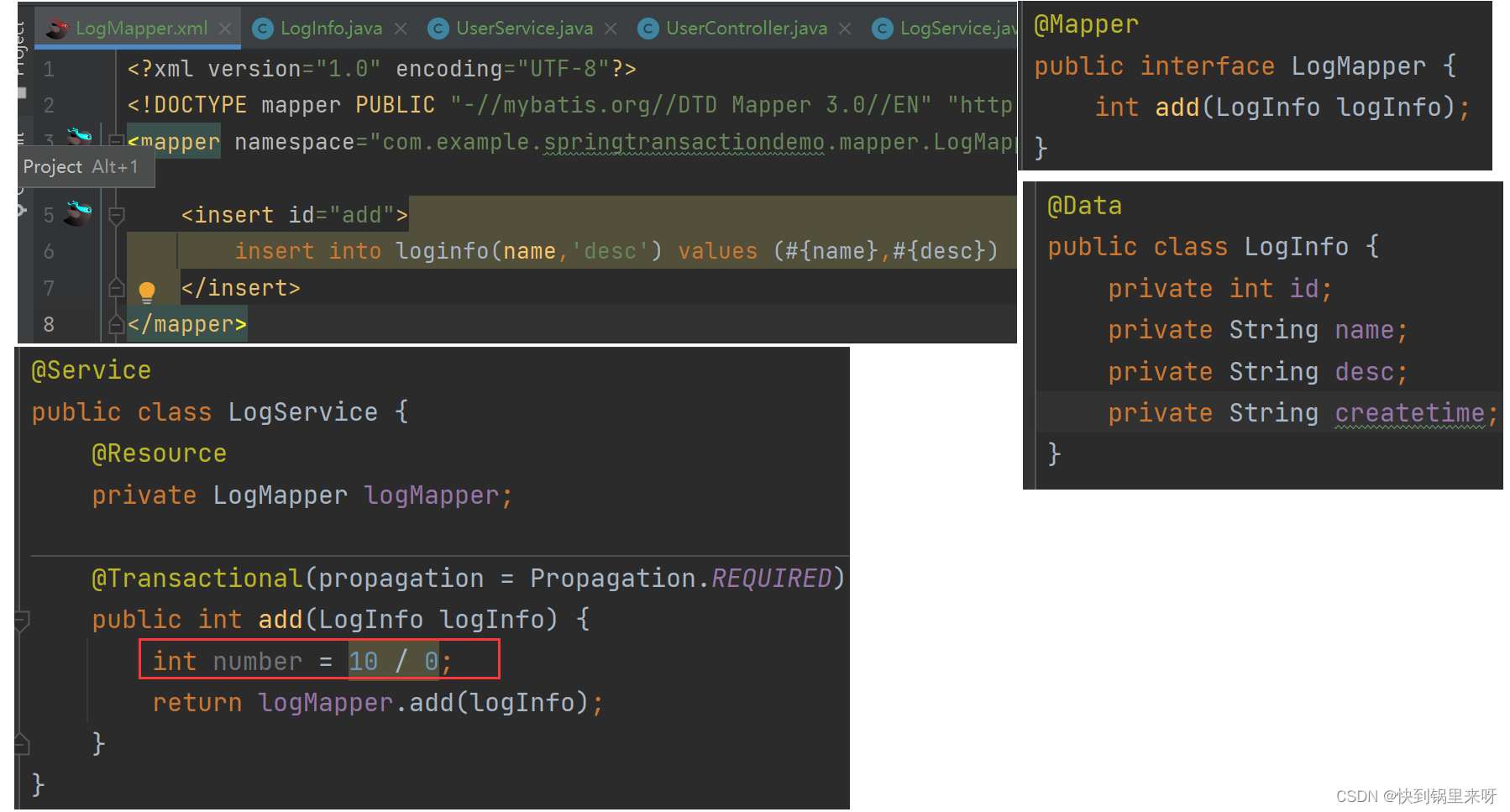
执行结果:程序报错,数据库没有插⼊任何数据
执行流程
-
UserService 中的保存⽅法正常执⾏完成。
-
LogService 保存⽇志程序报错,因为使⽤的是 Controller 中的事务,所以整个事务回滚。
-
数据库中没有插⼊任何数据,也就是步骤 1 中的⽤户插⼊⽅法也回滚了。
4.4.2 不支持当前事务(REQUIRES_NEW)
UserController 类中的代码不变,将添加用户和添加日志的方法修改为 REQUIRES_NEW 不支持当前事务,重新创建事务
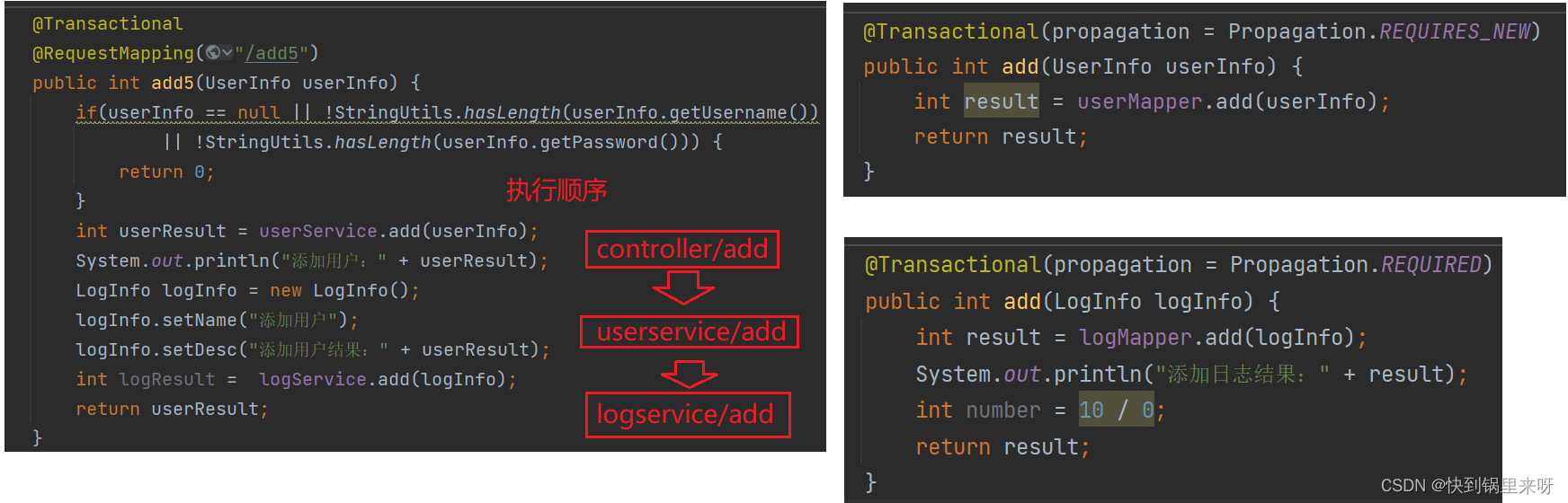
运行程序
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xRek64FZ-1676374722312)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676369232749.png)]](https://img-blog.csdnimg.cn/606b83fc65cc410a969f06c91290b2f3.png)
4.4.3 不支持当前事务(NOT_SUPPORTED)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QNO5pVdC-1676374722312)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676372475953.png)]](https://img-blog.csdnimg.cn/e29f5e1d339a4ea1879b319c685009b9.png)
4.4.4 NESTED 嵌套事务
方法调用流程:Controller/add ——》 用户添加方法(userservice) ——》 日志添加方法(logservice)
当日志添加方法出现异常之后,嵌套事务的执行结果是:
- 用户添加不受影响,添加用户成功
- 日志添加失败,因为发生异常回滚了事务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fGPQVmTM-1676374722312)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676371659498.png)]](https://img-blog.csdnimg.cn/150d177bc6ec4c0680f7442fb9f3b88a.png)
4.4.5 嵌套事务和加入事务的区别
先看嵌套事务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JqyEXrxd-1676374722313)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676373164427.png)]](https://img-blog.csdnimg.cn/478644d6d6504b4abf11bc83b251d2fc.png)
在 LogService 中进行事务的回滚操作
最终执行的效果就是,User 表成功添加数据,而 Log 表中没有添加数据。Log 中的事务已经回滚,但是嵌套事务不会回滚嵌套之前的事务,也就是说 嵌套事务可以实现部分事务回滚
加入事务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GnP7AlMP-1676374722313)(C:\Users\28463\AppData\Roaming\Typora\typora-user-images\1676373526005.png)]](https://img-blog.csdnimg.cn/f53b5073fd604449a53fbb537cb0cf42.png)
最终程序的执行结果:用户表和日志表都没有添加任何数据,说明整个事务都回滚了。也就是说 REQUIRED 如果回滚就是回滚所有事务,不能实现部分事务的回滚
嵌套事务之所以能够实现部分事务的回滚,是因为事务中有一个保存点(相当于游戏存档),嵌套事务进入之后相当于新建一个保存点,而回滚时只回滚到当前保存点,因此之前的事务是不受影响的。
而 REQUIRED 是加入到当前事务中,并没有创建事务的保存点,因此出现了回滚就是整个事务的回滚
总结二者区别:
- 整个事务如果全部执行成功,二者的结果是一样的
- 如果事务执行到一半失败了,那么加入事务整个事务都会回滚;而嵌套事务会局部回滚,不会影响上一个方法中执行的结果