ShardingSphere官方文档感悟
- 什么是ShardingSphere
- ShardingSphere-JDBC
- ShardingSphere-Proxy
- 功能
- 产品优势
- 设计哲学
- 连接
- 增强
- 可插拔
- L1内核层
- L2功能层
- L3生态层
- 部署形态
- ShardingSphere-JDBC独立部署
- ShardingSphere-Proxy独立部署
- 混合部署架构
官网地址: https://shardingsphere.apache.org/document/5.2.1/cn/overview/
什么是ShardingSphere
Apache ShardingSphere 是一款分布式的数据生态系统,可以将任意数据库转换为分布式数据库。并通过数据分片、弹性伸缩、加密等能力对原有数据库增强。
Apache ShardingSphere设计哲学为Database Plus,构建异构数据库上层的标准和生态。关注充分合理的利用数据库的计算和存储能力,而并非实现一个全新的数据库。它站在数据库的上层视角。关注他们之间的协作多于数据库本身。
ShardingSphere-JDBC
定位轻量级java框架,在java的JDBC层提供额外的服务。
ShardingSphere-Proxy
透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
功能
| 特性 | 定义 |
|---|---|
| 数据分片 | 数据分片,是应对海量数据存储与计算的有效手段。shardingSphere基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储 |
| 分布式事务 | 基于XA和BASE的混合事物引擎,保障数据库完整、安全的关键技术 |
| 读写分离 | 应对高压力业务访问的手段。基于对SQL语义理解及对底层数据库拓扑感知能力。提供灵活的读写流量拆分和读流量负载均衡 |
| 高可用 | 对数据存储计算平台的基本要求,提供基于原生或kubernetes环境下数据库集群的分布式高可用能力 |
| 数据迁移 | 提供跨数据源的数据迁移能力,实现跨源的数据关联与聚合 |
| 联邦查询 | 联邦查询,是面对复杂数据环境下利用数据的有效手段。提供数据源复杂查询分析能力,实现跨源的数据关联和聚合 |
| 数据加密 | 数据加密,是保证数据安全的基本手段。ShardingSphere提供完整、透明、安全、低成本的数据加密解决方案 |
| 影子库 | 在全链路压测场景下,ShardingSphere支持不同工作负载下的数据隔离,避免测试数据污染生产环境 |
产品优势
- 极致性能
驱动程序端历经常年打磨,效率接近原生JDBC,性能极致。 - 生态兼容
代理端支持任何通过MySQL/PostgreSQL协议的应用访问,驱动程序端可对接任意实现JDBC规范的数据库。 - 业务零侵入
面对数据库替换场景,ShardingSphere可满足业务无需改造,实现平滑业务迁移 - 运维低成本
在保留技术栈不变的前提下,对DBA学习、管理成本低 - 安全稳定
基于成熟数据库底座之上提供增量能力,兼顾安全性和稳定性。 - 弹性扩展
具备计算、存储平滑在线扩展能力,可满足业务多变的需求 - 开放生态
通过多层次(内核、功能、生态)插件化能力,为用户提供可定制满足自身特殊需求的独有系统。
设计哲学
ShardingSphere采用Database Plus设计哲学,该理念致力于构建数据库上层的标准和生态,在生态中补充数据库所缺失的能力。
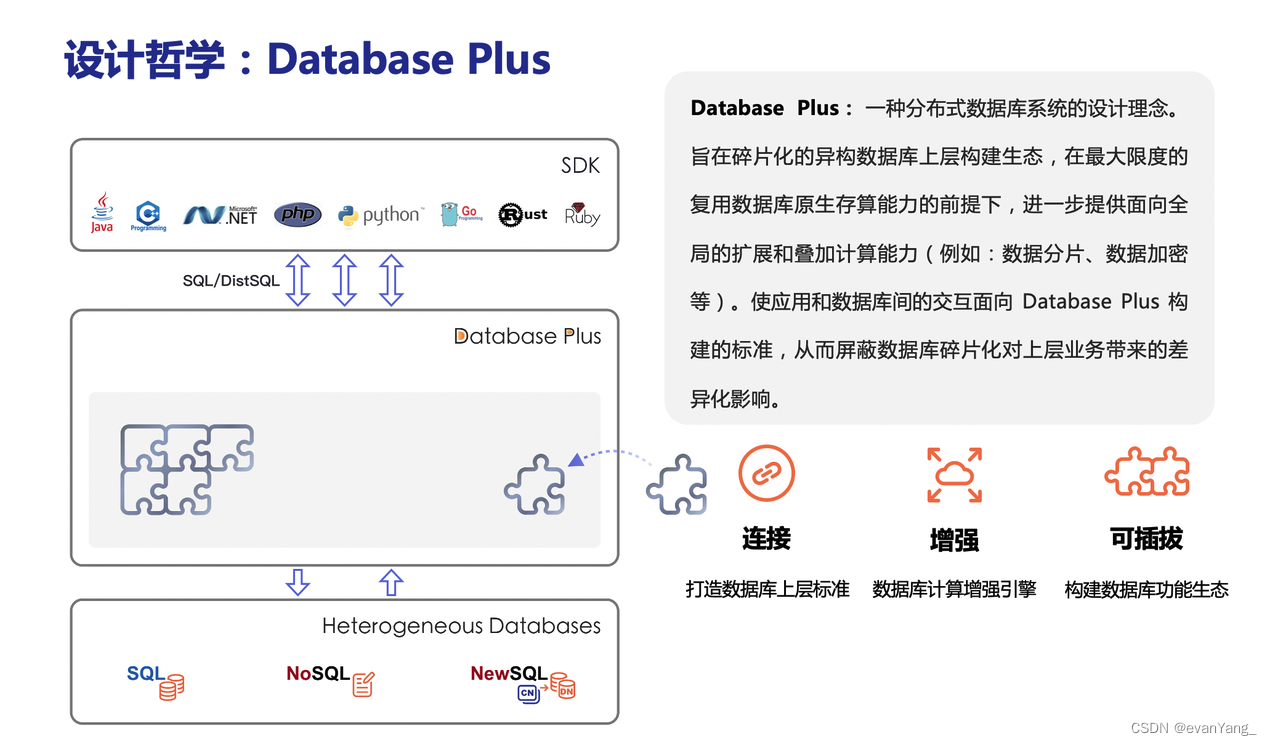
连接
打造数据库上层标准
通过对数据库协议、SQL方言以及数据库存储的灵活适配,快速构建多模异构数据库上层的标准,同时通过内置DistSQL为应用提供标准化的连接方式。
增强
数据库计算增强引擎
在原生数据库基础能力之上,提供分布式及流量增强方面的能力。前者可突破底层数据库在计算与存储上的瓶颈,后者通过对流量的变形、重定向、治理、鉴权及分析能力提供更为丰富的数据应用增强能力。
可插拔
构建数据库功能生态
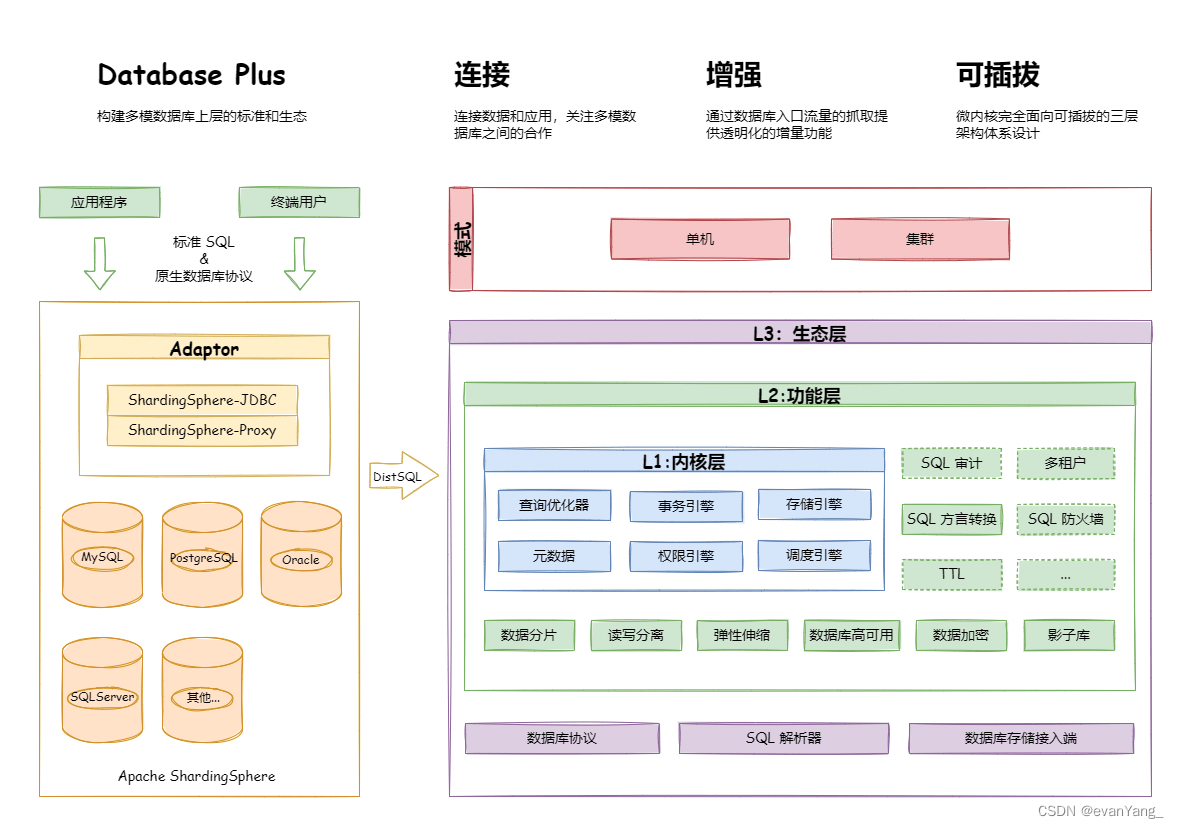
L1内核层
是数据库基本能力抽象,其所有组件均必须存在,但具体实现方式可通过可插拔的方式替换。主要包括查询优化器、分布式事务引擎、分布式执行引擎、权限引擎和调度引擎等。
L2功能层
用于提供增量能力,其所有组件均是可选的,可以包含零至多个组件。组件之间完全隔离,互无感知,多组件可通过叠加的方式相互配合使用。主要包括数据分片、读写分离、数据库高可用、数据加密、影子库等。用户自定义功能可完全面向Apache ShardingSphere定义的接口进行定制化扩展,而无需改动内核代码。
L3生态层
用于对接和融入现有数据库生态,包括数据库协议、SQL解析器和存储适配器,分别对应于Apache ShardingSphere以数据库协议提供服务的方式、SQL方言操作数据的方式以及对接存储节点的数据库类型。
部署形态
ShardingSphere-JDBC和Sharding-Proxy这2款既能够独立部署,又支持混合部署配合使用的产品组成。
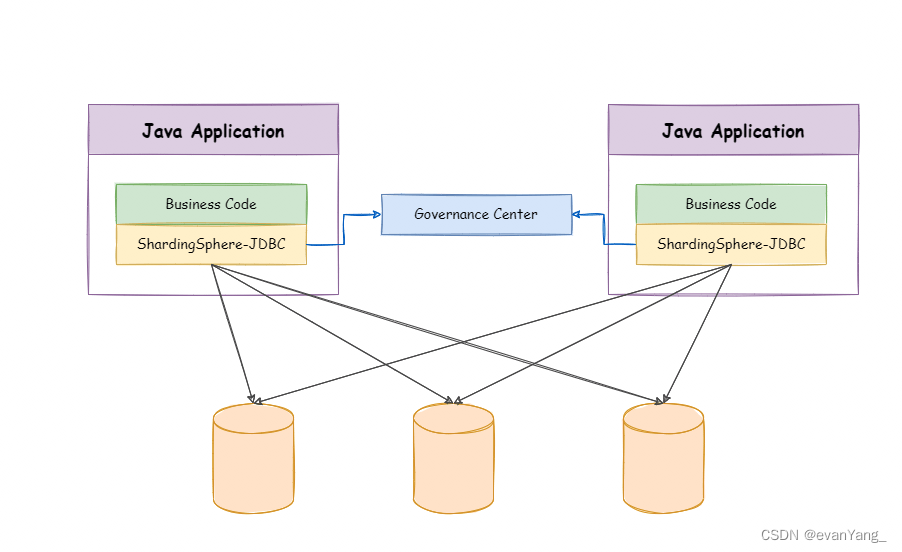
ShardingSphere-JDBC独立部署
定位为轻量级框架,在java的JDBC层提供额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,Mybatis,SpringJDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP,C3P0,BoneCP,HIkariCP等;
- 支持任意实现JDBC规范的数据库,目前支持M有SQL,PostgreSQL,Oracle,SQL Server以及任何可使用JDBC访问的数据库。
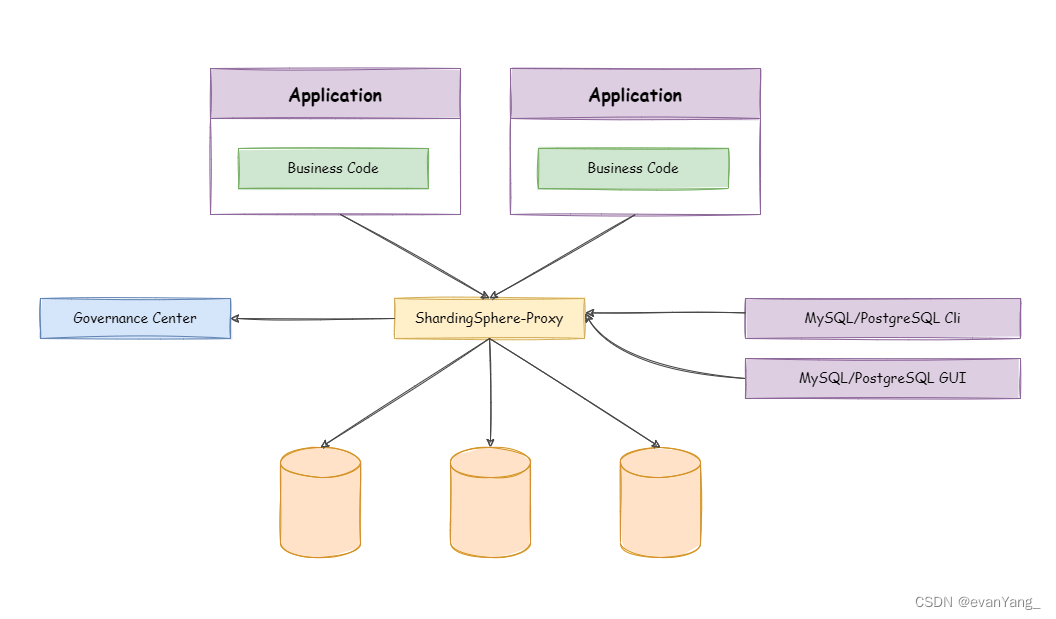
ShardingSphere-Proxy独立部署
定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。目前提供MySQL和PostgreSQL协议,透明化数据库操作,对DBA更加友好
- 向应用程序完全透明,可直接当作Mysql/PostgreSQL使用。
- 兼容MariaDB等基于Mysql协议的数据库,以及openGauss等基于PostgreSQL协议的数据库。
- 适用于任何兼容Mysql/PostgreSQL协议的客户端,如:MySQL CommandClient,Mysql Workbench,Navicat等。
|| ShardingSphere-JDBC| ShardingSphere-Proxy |
|–|–|–|
| 数据可 | 任意 |
| 数据可 | 任意 |
|特性| 定义 |
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | Mysql?PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
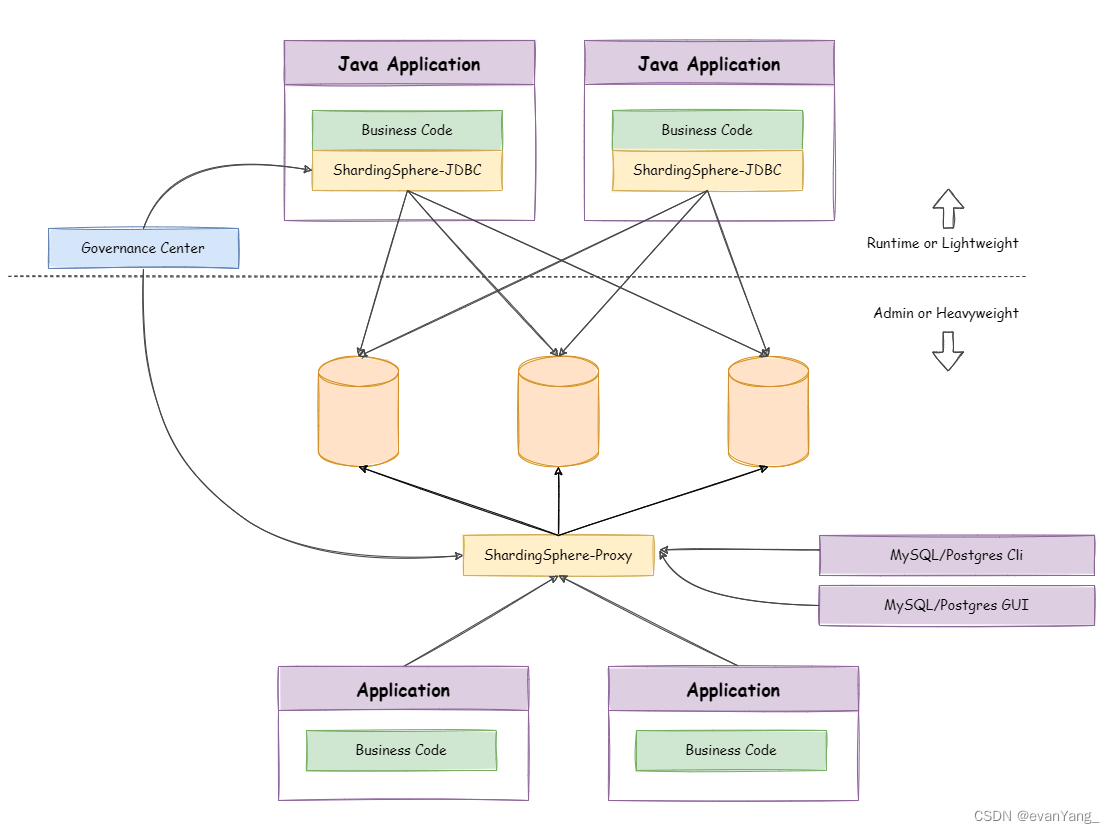
混合部署架构
ShardingSphere-JDBC 采用无中心化架构,与应用程序共享资源,适用于Java高性能的轻量级OLTP应用;ShardingSphere-Proxy提供静态入口以及异构语言的支持,独立于应用程序部署,使用于OLAP引用以及对分片数据库进行管理和运维的场景。
Apache ShardingSphere是多接入端共同组成的生态圈。通过混合使用ShardingSphere-JDBC和ShardingSphere-proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合于当前业务的最佳系统架构。