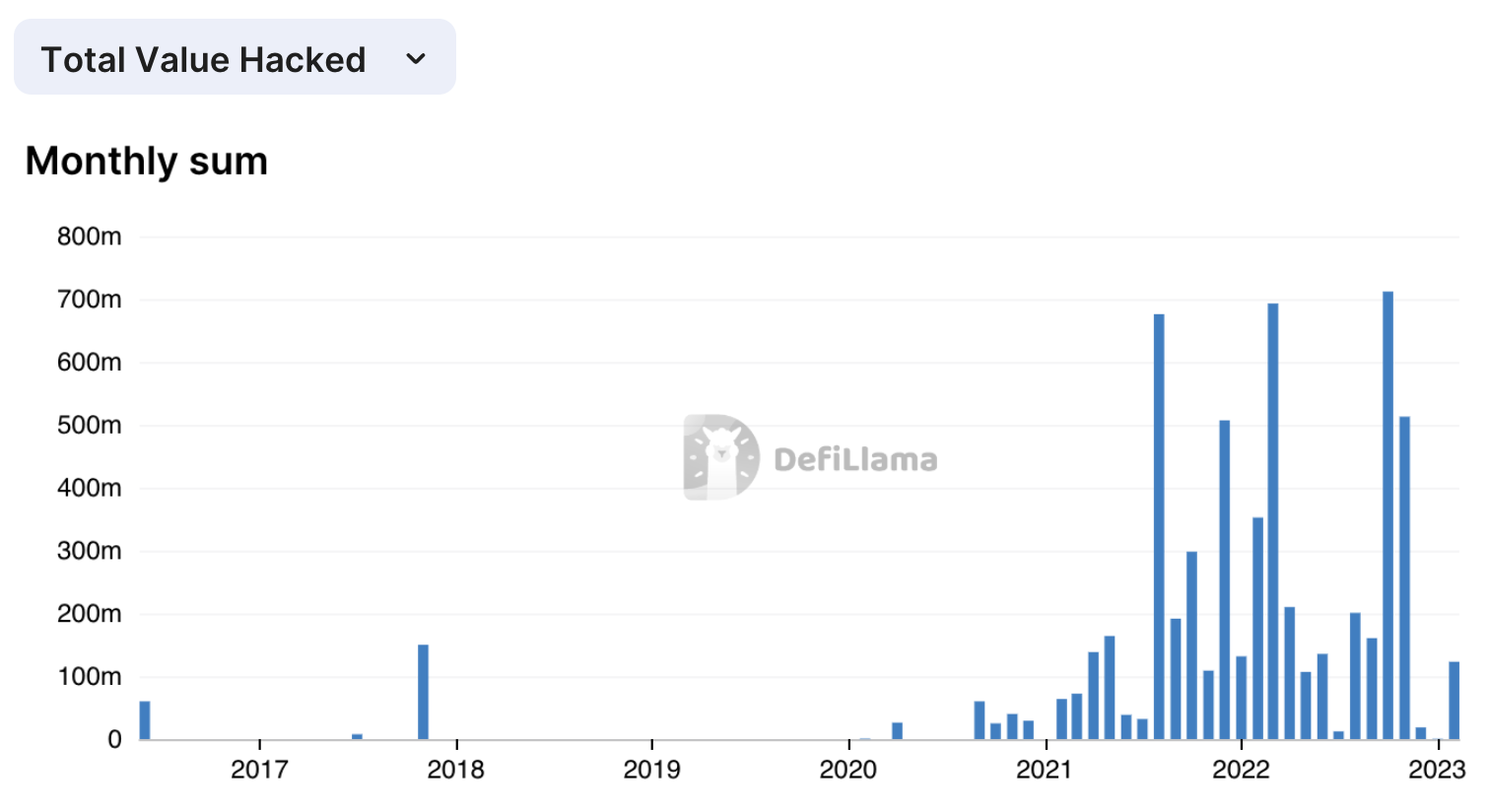
前言 语义分割的弱增量学习(WILSS)目的是学习从廉价和广泛可用的图像级标签中分割出新的类别,但图像级别的标签不能提供定位每个片段的细节。为了解决该问题,本文提出了一个新颖且数据高效的框架(FMWISS)。该框架提出了基于预训练的共同分割,以提炼出互补基础模型的知识来生成密集的伪标签。用师生结构进一步优化噪声伪标签,并引入基于内存的复制-粘贴增强技术,以改善旧类的灾难性遗忘问题。
FMWISS在Pascal VOC和COCO数据集上的广泛实验证明了其优越性能,例如,在15-5 VOC设置中实现了70.7%和73.3%,分别比最先进的方法高出3.4%和6.1%。
Transformer、目标检测、语义分割交流群
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
计算机视觉入门1v3辅导班

论文:https://arxiv.org/pdf/2302.14250.pdf
论文出发点
已有的语义分割方法在一个数据集上预训练的模型,在另一个有新类别的数据集上重新训练时,很容易忘记学到的知识。这种现象被称为 "灾难性遗忘"。解决这种灾难性遗忘问题的一个很有前途的方法被称为增量学习。
最近,有一些方法被提出来解决语义分割的增量学习(ILSS)任务,进一步发展这些方法的一个关键障碍是对新类别的像素级注释的要求。以此为基础,从图像级别的标签中逐步更新模型,以获得新的类别。但图像级别的标签不能提供准确定位每个片段的细节,这限制了WILSS的性能和发展。
这篇论文提出一个基础模型驱动弱增量学习的语义分割框架,被称为FMWISS,旨在改进并更有效地利用给定的图像级标签对新类别的监督,同时保留旧类别的知识。
创新思路
本文尝试利用互补的基础模型来改善和更有效地使用仅给定图像级别标签的监督,提出了基于预训练的共同分割,通过从预训练的基础模型中提炼出类别意识和类别无关的知识来生成密集的掩码,这针对原始图像标签提供了密集的监督。
同时为了有效地利用伪标签,使用了一个师生架构,并提出了密集对比损失,以动态地优化嘈杂的伪标签。进一步引入了基于内存的复制-粘贴增强技术,以弥补旧类的遗忘问题,也可以提高性能。
方法
预训练的协同分割方法
为了获得新类别图像的密集预测,作者应用预训练的 CLIP 模型来提取给定图像级标签的类别感知像素注释:
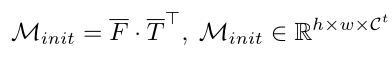
由 CLIP 生成的伪掩码可以提供丰富的类别感知像素注释,但由于基于图像文本对的 CLIP 训练范式注定擅长实例级分类而不是分割,因此掩码有噪声。为了提高掩码质量,本文提炼另一种基础模型的知识,即自监督预训练模型。这些模型可以生成紧凑的类别不可知注意力图。但是,如何在给定可能包含多个对象的图像的情况下为目标类提取分割是个难点。为了解决这个问题,作者通过特定类别的种子指导来改进初始掩码:
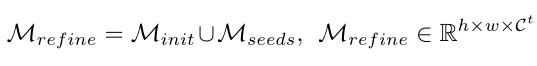
伪标签优化
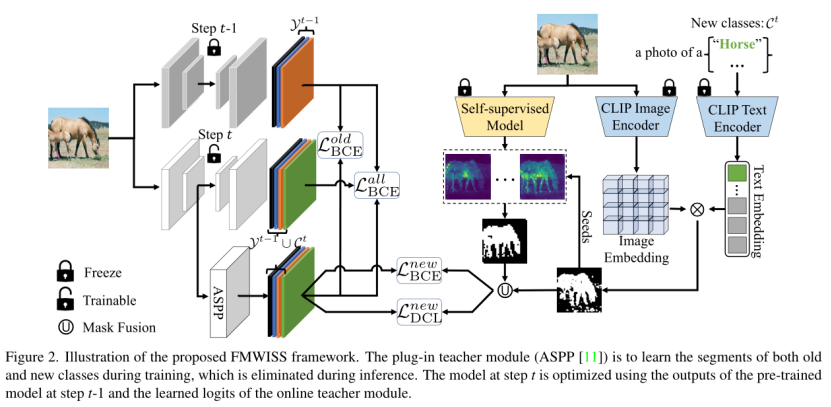
为了有效利用生成的伪像素标签,以提供比图像级标签更多的信息。因此,作者使用师生架构来进一步优化仍然嘈杂的伪掩码。具体来说,通过将分割模型作为学生模型,引入了一个插件教师模块(图 2 中的 ASPP 网络),以在训练过程中动态学习更好的伪掩码。
受无监督表示学习中 InfoNCE 损失的启发,本文执行密集对比学习,计算如下:
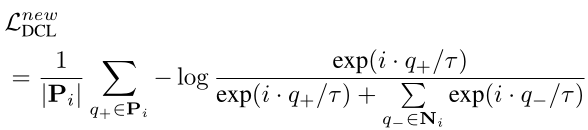
逐像素 BCE 损失和上式中的密集对比损失可以互相补充,帮助教师模块学习判别像素特征以及通过类内和类间像素特征建模来规范像素特征空间。
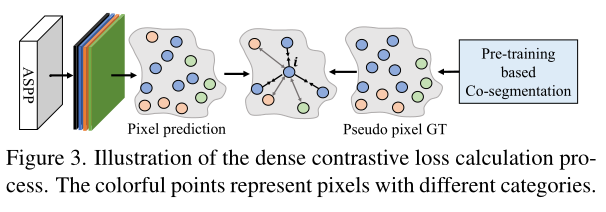
基于内存的复制粘贴增强
首先为每个旧类构建一个 memory bank,每个类存档将在基础模型训练期间存储 B 个前景实例和分割标签。然后,在每个步骤中,从随机选择的旧类档案中随机挑选一对前景图像和标签,并将它们随机粘贴到新类图像中。训练样本包含第 t 步的新类图像以及第 t-1 步的旧类图像和像素标签,如图4所示:

整体优化
通过提取训练模型和动态更新的教师模型的知识,在步骤 t 优化分割模型。由于教师模型主要通过二元交叉熵损失进行优化,因此,使用 BCE 损失将教师模型的预测进行提炼。考虑到学习到的伪掩码并不完美,作者使用软像素标签作为新类别的最终监督,并使用旧模型和教师模块输出的加权平均值作为旧类的监督。
结果
之前的 WILSS SoTA 和本文的 FMWISS 在 10-10 VOC 设置下的定性比较。从左到右:原始图像、WILSON、FMWISS 和 ground-truth。

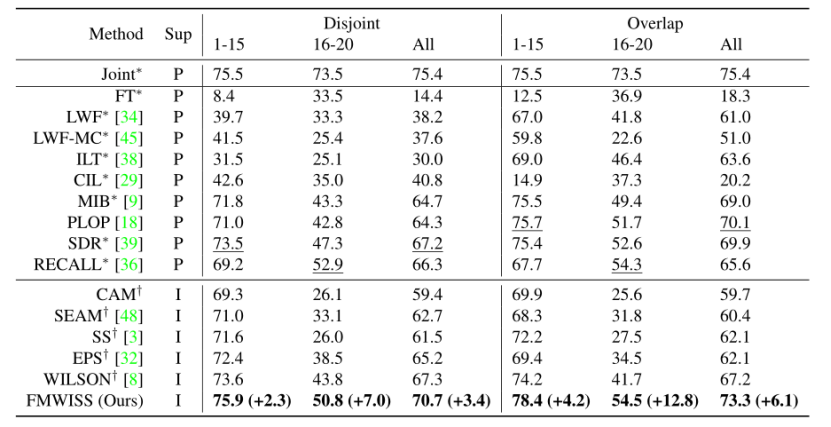
在Pascal VOC 15-5数据集上设置的结果。其中,“P”和“I”分别表示像素级和图像级标签。使用图像级标签和使用像素级标签作为监督的最佳方法分别以粗体和下划线表示。
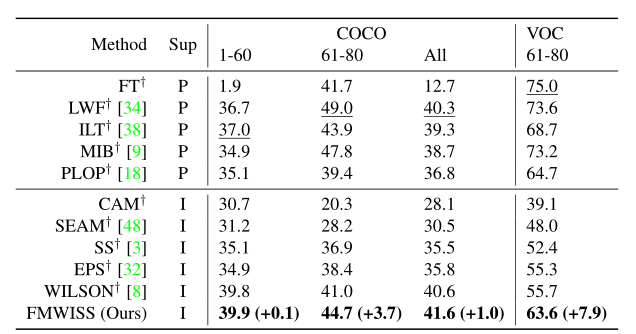
COCO-to-VOC 设置的结果:
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章
DiffusionDet:用于对象检测的扩散模型
CV小知识讨论与分析(7) 寻找论文创新点的新方式
CV小知识分析与讨论(6)论文创新的一点误区
一文看尽深度学习中的各种注意力机制
MMYOLO 想你所想:训练过程可视化
顶刊TPAMI 2023!Food2K:大规模食品图像识别
用于精确目标检测的多网格冗余边界框标注
2023最新半监督语义分割综述 | 技术总结与展望!
原来Transformer就是一种图神经网络,这个概念你清楚吗?
快速实现知识蒸馏算法,使用 MMRazor 就够啦!
知识蒸馏的迁移学习应用
TensorFlow 真的要被 PyTorch 比下去了吗?
深入分析MobileAI图像超分最佳方案:ABPN
3D目标检测中点云的稀疏性问题及解决方案
一文深度剖析扩散模型究竟学到了什么?
OpenMMLab教程【零】OpenMMLab介绍与安装
代码实战:YOLOv5实现钢材表面缺陷检测
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
超全汇总 | 计算机视觉/自动驾驶/深度学习资料合集!
高精度语义地图构建的一点思考
点云分割训练哪家强?监督,弱监督,无监督还是半监督?