目录
- 1、最近邻算法 KNN
- 1.1 K的选择
- 1.2 案例:鸢尾花
- 2、决策树
- 2.1 决策树介绍
- 2.2 案例:鸢尾花数据
- 2.3 补充
1、最近邻算法 KNN
原理:找到K 个与新数据最近的样本,取样本中最多的一个类别作为新数据的类别
要点:距离—是欧式距离,即两点之间的连线
优点:
- 简单易实现
- 对于边界不规则的数据效果较好,对于线性分类器在于边界不规则的数据上效果就不好,线性分类器可以理解成画一条线来分类,不规则的数据则很难找到一条线将其分成左右两边。
缺点:
- 只适合小数据集。每次预测新数据都需要使用全部的数据集,所以如果数据集太大会消耗大量时间,占用大量存储空间
- 数据不平衡效果不好。有的类别数据特别多,有的类别数据特别少,那么这种方法就会失效了
- 必须要做数据标准化: 由于使用距离来进行计算,如果数据量纲不同,数值较大的字段影响就会变大,所以需要对数据进行标准化,比如都转换到 0-1 的区间。
1.1 K的选择
当 K 越小的时候容易过拟合,因为结果的判断与某一个点强相关。而 K越大的时候容易欠拟合,因为要考虑所有样本的情况,那就等于什么都不考虑。
对于 K 的取值,一种办法就是从 1 开始不断地尝试,查看准确率。随着 K 的增加,一般情况下准确率会先变大后变小,然后选取效果最好的那个 K 值就好了。当然,关于 K 最好使用奇数,偶数可能会存在两个类别的数量一样
1.2 案例:鸢尾花
from sklearn import datasets #数据集
from sklearn.neighbors import KNeighborsClassifier #sklearn中KNN
import numpy as np
np.random.seed(0) #设置随机种子
iris = datasets.load_iris()
iris
iris_x = iris.data
iris_y =iris.target
iris_y

#划分测试集,训练集 这里用的产生随机数
randomarr= np.random.permutation(len(iris_x))
randomarr
iris_x_train = iris_x[randomarr[:-10]]
iris_y_train = iris_y[randomarr[:-10]]
iris_x_test = iris_x[randomarr[-10:]]
iris_y_test = iris_y[randomarr[-10:]]
#训练模型
knn = KNeighborsClassifier()
knn.fit(iris_x_train,iris_y_train)
iris_y_predict = knn.predict(iris_x_test) #模型预测
probility=knn.predict_proba(iris_x_test) #预测,输出概率形式
probility

score=knn.score(iris_x_test,iris_y_test,sample_weight=None) #模型准确率
print('iris_y_predict = ')
print(iris_y_predict) #测试集预测值
print('iris_y_test = ')
print(iris_y_test) #测试集真值
print('Accuracy:',score) #输出准确率

2、决策树
2.1 决策树介绍
决策树最初的版本称为 ID3( Iterative Dichotomiser 3 ),ID3 的缺点是无法处理数据是连续值的情况,也无法处理数据存在缺失的问题,需要在准备数据环节把缺失字段进行补齐或者删除数据。
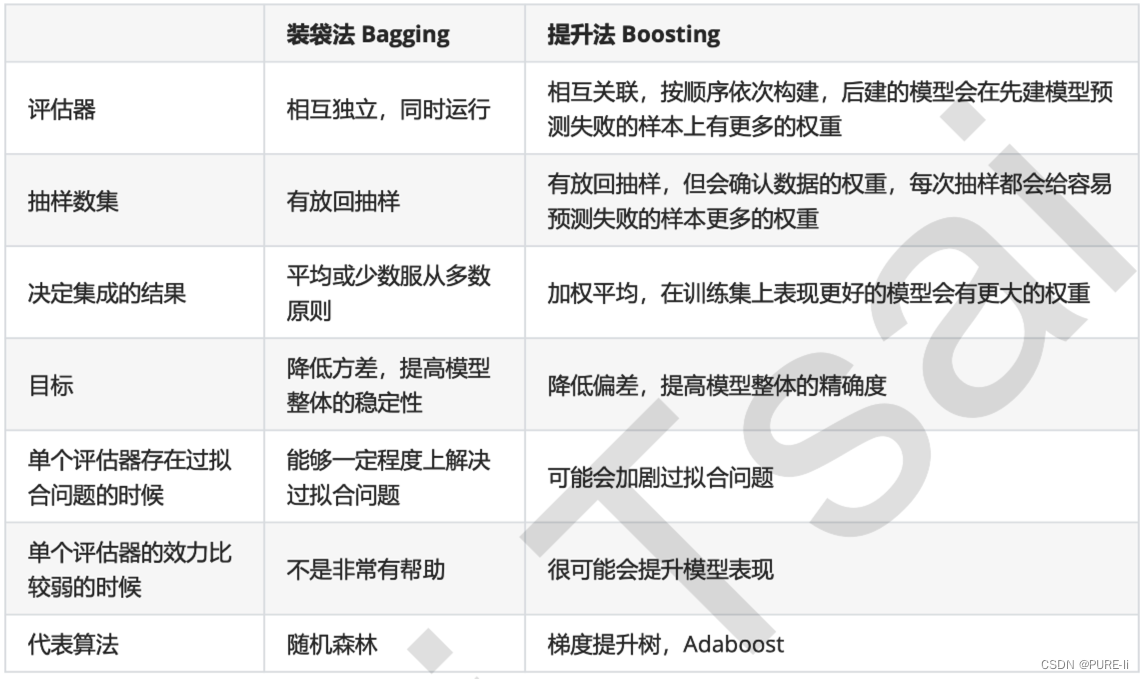
| 决策树 | 模型类型 | 树结构 | 特性选择 | 连续值处理 | 缺失值处理 |
|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不可以 | 不可以 |
| C4.5 | 分类 | 多叉树 | 信息增比 | 可以 | 可以 |
| CART | 分类与回归 | 二叉树 | 基尼系数 | 可以 | 可以 |
CART优点:
- 直观,可解释性强
- 预测速度快
- 可以处理连续值、缺失值、离散值
缺点:
- 容易过拟合。如果样本与测试数据存在一定差距时,泛化性能不好
- 需要处理样本不均衡的问题
过拟合解决:剪枝
- 预剪枝:在决策树构建之初就设定一个阈值,当分裂节点的熵阈值小于设定值的时候就不再进行剪枝了
- 后剪枝:的决策树已经构建完成以后,再根据设定的条件来判断是否要合并一些中间节点,使用叶子节点来代替
2.2 案例:鸢尾花数据
准备:
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
import numpy as np
np.random.seed(0)
iris=datasets.load_iris()
iris_x=iris.data
iris_y=iris.target
indices = np.random.permutation(len(iris_x))
iris_x_train = iris_x[indices[:-10]]
iris_y_train = iris_y[indices[:-10]]
iris_x_test = iris_x[indices[-10:]]
iris_y_test = iris_y[indices[-10:]]
训练模型:
clf = DecisionTreeClassifier(max_depth=4)
clf.fit(iris_x_train,iris_y_train)
作图:
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
预测:
输出预测值,真实值,和得分
iris_y_predict = clf.predict(iris_x_test)
score = clf.score(iris_x_test,iris_y_test,sample_weight=None)
print('iris_y_predict = ')
print(iris_y_predict)
print('iris_y_test = ')
print(iris_y_test)
print('Accuracy:',score)
2.3 补充
随机森林:
为了更好地解决泛化及树结构变动等问题,从决策树演进出来随机森林算法。
随机森林就是使用了 bagging 方案构建了多棵决策树。即对所有树结果取平均
GBDT:
梯度提升决策树算法。GBDT 是基于 boosting 的策略。GBDT 构建的多棵树之间是有联系的,每个分类器在上一轮分类器的残差基础上进行训练。
XGBoost:
不是一个算法,是对 GBDT 的一种工程实现,它优化了 GBDT 里面的求解过程,并加入了很多工程上的优化项目,使得数据处理、运算速度等环节都有了很大的提升。