从Demo讲起:FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout.setCycle(true);TridentTopology topology = new TridentTopology();
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);Trident keeps track of a small amount of state for each input source (metadata about what it has consumed) in Zookeeper, and the "spout1" string here specifies the node in Zookeeper where Trident should keep that metadata. (Trident 在zookeeper中为每一个输入资源(metaData)建立一系列状态监控和追踪. "spout1" 指定了在zookeer中,Trident应该存储metaData的位置.)
the spout emits a stream containing one field called "sentence". The next line of the topology definition applies the Split function to each tuple in the stream, taking the "sentence" field and splitting it into words. Each sentence tuple creates potentially many word tuples – for instance, the sentence "the cow jumped over the moon" creates six "word" tuples. (就是说每一个处理输入就是一个tuple,输出就是一个单独的tuple.)
One of the cool things about Trident is that it has fully fault-tolerant, exactly-once processing semantics. This makes it easy to reason about your realtime processing. Trident persists state in a way so that if failures occur and retries are necessary, it won't perform multiple updates to the database for the same source data.
Trident实现了容错和一次执行的原子性操作, 通过事务管理数据的整个处理过程。 并且失败后,可以重新尝试, 同一组数据不会多次更新。
DRPC
a low latency distributed query on the word counts
低延迟的分布式查询
DRPCClient client = new DRPCClient("drpc.server.location", 3772);
System.out.println(client.execute("words", "cat dog the man");"words" 表示流名称.topology.newDRPCStream("words")
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));wordCounts: 另外一个数据流拓扑对象.Each DRPC request is treated as its own little batch processing job that takes as input a single tuple representing the request. The tuple contains one field called "args" that contains the argument provided by the client.
一个单独的tuple 代表一个 ERPC request. tuple 包含一个“args”字段,里面包含客户端请求参数. 比如:"cat dog the man"
Trident is intelligent about how it executes a topology to maximize performance.
1.Operations that read from or write to state (like persistentAggregate and stateQuery) automatically batch operations to that state. 从state中读或者向state中写,自动转换为批量处理. 也可以可以设置cache,最大程度限制读写次数,提高性能和提供方便.
2.Trident aggregators are heavily optimized. 聚合最优化.
Rather than transfer all tuples for a group to the same machine and then run the aggregator, Trident will do partial aggregations when possible before sending tuples over the network. For example, the Count aggregator computes the count on each partition, sends the partial count over the network, and then sums together all the partial counts to get the total count. This technique is similar to the use of combiners in MapReduce.
aggregators 并不是转换所有的tuple给一个相同的机器,然后再去做聚合. Trident 会对tuple做部分聚合,然后把部分聚合发送到其他集群节点,一起汇总一个总的聚合.
另外一个例子:
TridentState urlToTweeters =
topology.newStaticState(getUrlToTweetersState()); //曾经转发url的tweeter用户.
TridentState tweetersToFollowers =
topology.newStaticState(getTweeterToFollowersState()); //tweeter用户的粉丝数量.
topology.newDRPCStream("reach")
.stateQuery(urlToTweeters, new Fields("args"), new MapGet(), new Fields("tweeters")) // args,DRPCClient的请求参数,url. 根据url获取到转发该url的tweeter用户集合. 一个tuple.
.each(new Fields("tweeters"), new ExpandList(), new Fields("tweeter")) // 展开tweeters集合用户, tweeter, 很多个tuple,取决于用户集合数量.
.shuffle()
.stateQuery(tweetersToFollowers, new Fields("tweeter"), new MapGet(), new Fields("followers")) // 根据个体用户tweeter,查询他或她的粉丝群,followers集合,一个tuple.
.parallelismHint(200) // 为粉丝群开启200个并行任务. .each(new Fields("followers"), new ExpandList(), new Fields("follower")) //展开粉丝群, followers -> follower. 多个tuple.
.groupBy(new Fields("follower")) //对粉丝群进行分组.
.aggregate(new One(), new Fields("one")) //合并相同的粉丝为一个.
.parallelismHint(20)
.aggregate(new Count(), new Fields("reach")); // 计算人数.Fields and tuples
The Trident data model is the TridentTuple which is a named list of values.
过滤操操作:
Consider this example. Suppose you have a stream called "stream" that contains the fields "x", "y", and "z". To run a filter MyFilter that takes in "y" as input, you would say:
stream.each(new Fields("y"), new MyFilter())
Suppose the implementation of MyFilter is this:
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(0) < 10;
}
}
This will keep all tuples whose "y" field is less than 10. 会过滤掉所有y<10的tuple.
each 操作:
假设stream里面有x,y,z字段.
stream.each(new Fields("x", "y"), new AddAndMultiply(), new Fields("added", "multiplied")); // 运算完之后的字段是: x, y, z, added, multipliedpublic class AddAndMultiply extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) { // 这个tuple里面仅仅有x,y两个字段.没有z字段.
int i1 = tuple.getInteger(0);
int i2 = tuple.getInteger(1);
collector.emit(new Values(i1 + i2, i1 * i2));
}
}聚合操作:
With aggregators, on the other hand, the function fields replace the input tuples. So if you had a stream containing the fields "val1" and "val2", and you did this:
stream.aggregate(new Fields("val2"), new Sum(), new Fields("sum"))
The output stream would only contain a single tuple with a single field called "sum", representing the sum of all "val2" fields in that batch.
流输出结果仅包含一个tuple,tuple里面仅有一个字段sum. 代表在此轮批量处理中val2的总和.
分组聚合操作:
With grouped streams, the output will contain the grouping fields followed by the fields emitted by the aggregator. For example:
stream.groupBy(new Fields("val1")) // 输出字段里包含正在分组的字段val1, 跟随着聚合字段sum.
.aggregate(new Fields("val2"), new Sum(), new Fields("sum")) // sum 字段替换val2字段.
In this example, the output will contain the fields "val1" and "sum".
State
如何保证每个消息仅仅执行一次:
Trident solves this problem by doing two things:
- Each batch is given a unique id called the "transaction id". If a batch is retried it will have the exact same transaction id. 给每个批次赋予交易id, 失败重试的时候,交易id是一样的.
- State updates are ordered among batches. That is, the state updates for batch 3 won't be applied until the state updates for batch 2 have succeeded. //交易id按序列运行, 如果2没有成功,3也不会执行.
存储交易id和计数value到数据库里面,
Then, when updating the count, you can just compare the transaction id in the database with the transaction id for the current batch. If they're the same, you skip the update – because of the strong ordering, you know for sure that the value in the database incorporates the current batch. If they're different, you increment the count.
交易id也不是必须得存储起来,Trident有一套自己的"至少一次消息处理"机制,保证失败的情况.
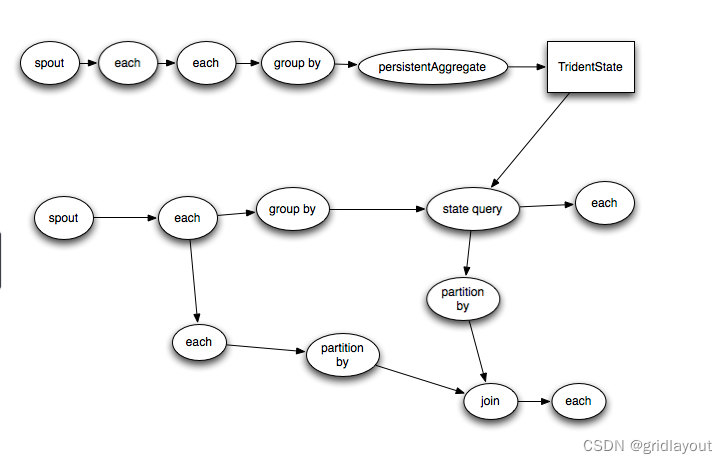
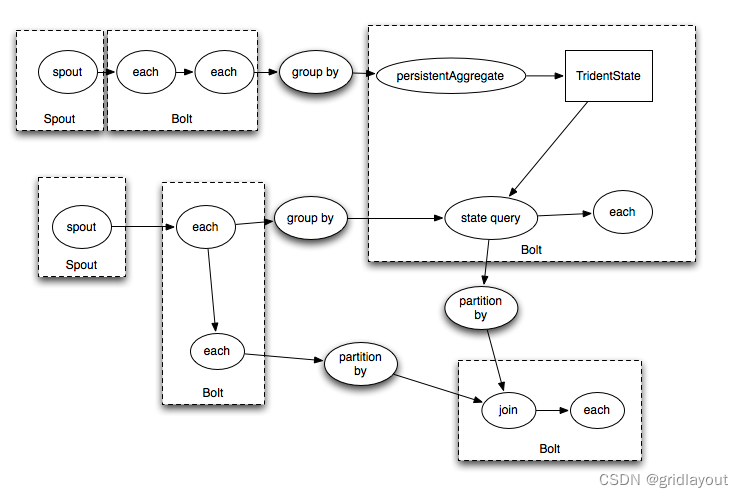
Execution of Trident topologies , Trident 拓扑的执行流程:
tuple 只有在shuffle或group的时候,才会进行网络同步.
Tuples are only sent over the network when a repartitioning of the data is required, such as if you do a groupBy or a shuffle.
Trident topologies compile down into as efficient of a Storm topology as possible. Tuples are only sent over the network when a repartitioning of the data is required, such as if you do a groupBy or a shuffle.
Trident拓扑会最优化的编译成最高效的Storm拓扑.
So if you had this Trident topology: