目录
三、MySQL高级03
3.1 MyCat
3.1.1 MyCat简介
3.1.2 中间件的作用
3.2 安装MyCat
3.3 主从复制
3.3.1 主从复制的原理
3.3.2 主从复制的好处
3.3.3 配置主从复制
三、MySQL高级03
如果虚拟机的磁盘已满,可以对磁盘进行重新分配
参考:虚拟机扩展磁盘与增加磁盘操作_虚拟机新增磁盘_石头城12345的博客-CSDN博客
3.1 MyCat
3.1.1 MyCat简介
Mycat 是数据库中间件。 java->mycat->mysql1 Cobar属于阿里B2B事业群,始于2008年,在阿里服役3年多,接管3000+个MySQL数据库的schema,集群日处理在线SQL请求50亿次以上。由于Cobar发起人的离职,Cobar停止维护。 2 Mycat是开源社区在阿里cobar基础上进行二次开发,解决了cobar存在的问题,并且加入了许多新的功能在其中。青出于蓝而胜于蓝。 3 OneProxy基于MySQL官方的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件。舍弃了一些功能,专注在性能和稳定性上。 4 kingshard由小团队用go语言开发,还需要发展,需要不断完善。 5 Vitess是Youtube生产在使用,架构很复杂。不支持MySQL原生协议,使用需要大量改造成本。 6 Atlas是360团队基于mysql proxy改写,功能还需完善,高并发下不稳定。 7 MaxScale是mariadb(MySQL原作者维护的一个版本) 研发的中间件 8 MySQLRoute是MySQL官方Oracle公司发布的中间件
3.1.2 中间件的作用
1、读写分离

2、数据分片
垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)

3、多数据源整合

4、原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
这种方式把数据库的分布式从代码中解耦出来,用户察觉不出来后台使用Mycat 还是MySQL。

3.2 安装MyCat
注:使用mycat1.6的应用于要求
jdk版本在1.7以上
mysql版本支持5.+,不支持8.+
mysql版本如果不正确,会一直报错
Can't connect to MySQL server on'XXXXX'1、安装wget
-- 使用yum安装wget
yum -y install wget
Installed:
wget.x86_64 0:1.14-18.el7_6.1
Complete!2、使用wget下载MyCat压缩包
wget http://dl.mycat.org.cn/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz3、解压安装包
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz4、配置环境变量
-- 进入配置文件
vim /etc/profile
-- 配置MyCat的环境变量
export MYCAT_HOME=/usr/lwl/soft/mycat/mycat
export PATH=$MYCAT_HOME/bin:$PATH
配置完之后使配置文件生效
source /etc/profile5、修改server.xml
vim /usr/lwl/soft/mycat/mycat/conf/server.xml
1、端口号在第33行,默认为8066(不用进行修改)
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
2、修改root用户密码(第81行)
原始密码:123456 修改后的密码root6、修改schema.xml
方式一:
修改配置文件 schema.xml
删除<schema>标签间的表信息,<dataNode>标签只留一个,
<dataHost>标签只留一个,<writeHost>
<readHost>只留一对 方式二:
或者将原本的schema.xml文件更名为schema-bak.xml
再建一个新的文件名为schema.xml,内容如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--这里的TESTDB对应server.xml文件中的property标签-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!--表名为test1,这张表在数据库test中一定要存在-->
<table name="test1" dataNode="dn1" />
</schema>
<!--节点名字为dn1,dataHost对应下面的dataHost标签,database是指明数据库-->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<!--数据库的一些信息,比如dbType="mysql"是说数据库类型是mysql-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!--一直在运行的时候,使用的是user-->
<heartbeat>select user()</heartbeat>
<!--用来进行数据库写操作的主机信息,默认的用户名和密码都是root-->
<writeHost host="hostM1" url="192.168.111.127:3306" user="root" password="密码">
<!--用来进行数据库读操作的主机信息,默认的用户名和密码都是root-->
<readHost host="hostS2" url="192.168.111.128:3306" user="root" password="密码"></readHost>
</writeHost>
</dataHost>
</mycat:schema>
配置完成后,要赋予新的schema.xml文件高级权限
chmod 777 schema.xmlschema文件解释:
引用:使用Mycat实现数据库读写分离 - 简书
1、schema 解释 <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> name属性:表示的是逻辑库的名字,是应用程序连接的时候的数据库名称. checkSQLschema属性:当该值设置为 true 时,如果我们执行语句select * from TESTDB.travelrecord;则 MyCat 会把语句修改为select * from travelrecord;。即把表示 schema 的字符去掉,避免发送到后端数据库执行时报(ERROR 1146 (42S02): Table ‘testdb.travelrecord’ doesn’t exist)。 sqlMaxLimit属性:当该值设置为某个数值时。每条执行的 SQL 语句,如果没有加上 limit 语句,MyCat 也会自动的加上所对应的值。例如设置值为 100,执行select * from TESTDB.travelrecord;的效果为和执行select * from TESTDB.travelrecord limit 100;相同。设置该值的话,MyCat 默认会把查询到的信息全部都展示出来,造成过多的输出。所以,在正常使用中,还是建议加上一个值,用于减少过多的数据返回。 当然 SQL 语句中也显式的指定 limit 的大小,不受该属性的约束。 需要注意的是,如果运行的 schema 为非拆分库的,那么该属性不会生效。需要手动添加 limit 语句 2、table标签解释 <table name="test1" dataNode="dn1" /> Table 标签定义了 MyCat 中的逻辑表,所有需要拆分的表都需要在这个标签中定义。 name 属性:定义逻辑表的表名,这个名字就如同我在数据库中执行 create table 命令指定的名字一样,同个 schema 标签中定义的名字必须唯一。 dataNode属性:定义这个逻辑表所属的 dataNode, 该属性的值需要和后面 dataNode 标签中 name 属性的值相互对应。 3、dataNode标签解释 <dataNode name="dn1" dataHost="localhost1" database="test" /> dataNode 标签定义了 MyCat 中的数据节点,也就是我们通常说所的数据分片。一个 dataNode 标签就是一个独立的数据分片。 name 属性:定义数据节点的名字,这个名字需要是唯一的,我们需要在table 标签上应用这个名字,来建立表与分片对应的关系。 dataHost 属性:该属性用于定义该分片属于哪个数据库实例的,属性值是引用 dataHost 标签上定义的 name 属性。 database 属性:该属性用于定义该分片属性哪个具体数据库实例上的具体库,因为这里使用两个纬度来定义分片,就是:实例+具体的库。因为每个库上建立的表和表结构是一样的。所以这样做就可以轻松的对表进行水平拆分。 4、dataHost标签解释 <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> 作为 Schema.xml 中最后的一个标签,该标签在 mycat 逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。 name 属性:唯一标识 dataHost 标签,供上层的标签使用 maxCon 属性:指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的 writeHost、readHost 标签都会使用这个属性的值来实例化出连接池的最大连接数 minCon 属性:指定每个读写实例连接池的最小连接,初始化连接池的大小 balance 属性: 负载均衡类型,目前的取值有 3 种: balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。 balance="1",全部的 readHost 与 stand by writeHost参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载 均衡。 balance="2",所有读操作都随机的在 writeHost、readhost 上分发。 balance="3",所有读请求随机的分发到 wiriterHost 对应的readhost 执行,writerHost 不负担读压力, 注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。 writeType 属性: 负载均衡类型,目前的取值有 3 种: ① writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties . ② writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。switchType 属性 -1 表示不自动切换。 1 默认值,自动切换。 2 基于 MySQL 主从同步的状态决定是否切换。 dbType 属性:指定后端连接的数据库类型,目前支持二进制的 mysql 协议,还有其他使用 JDBC 连接的数据库。例如:mongodb、oracle、spark 等。 dbDriver 属性:指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用 native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。 从 1.6 版本开始支持 postgresql 的 native 原始协议。 如果使用 JDBC 的话需要将符合 JDBC 4 标准的驱动 JAR 包放到MYCAT\lib 目录下,并检查驱动 JAR 包中。 包括如下目录结构的文件:META-INF\services\java.sql.Driver。在这个文件内写上具体的 Driver 类名,例如: com.mysql.jdbc.Driver。 5、heartbeat标签解释 <heartbeat>select user()</heartbeat> 这个标签内指明用于和后端数据库进行心跳检查的语句。例如,MYSQL 可以使用 select user(),Oracle 可以使用 select 1 from dual 等。 6、writeHost 标签、readHost 标签解释 这两个标签都指定后端数据库的相关配置给 mycat,用于实例化后端连接池。唯一不同的是,writeHost 指定写实例、readHost 指定读实例,组着这些读写实例来满足系统的要求。在一个 dataHost 内可以定义多个 writeHost 和 readHost。 但是,如果 writeHost 指定的后端数据库宕机,那么这个 writeHost 绑定的所有 readHost 都将不可用。另一方面,由于这个 writeHost 宕机系统会自动的检测到,并切换到备用的 writeHost 上去。 host 属性:用于标识不同实例,一般 writeHost 我们使用M1,readHost 我们用S1。 url 属性:后端实例连接地址,如果是使用 native 的 dbDriver,则一般为 ipaddress:port 这种形式。用 JDBC 或其他的dbDriver,则需要特殊指定。当使用 JDBC 时则可以jdbc:mysql://localhost:3306/。 user 属性:后端存储实例需要的用户名字。 password 属性:后端存储实例需要的密码。
7、修改服务器名字(可以不修改)
修改前:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#主机修改后:
# 这里的hostM1对应schema.xml中的writeHost标签
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 hostM1
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 hostM1
192.168.111.127 hostM1
#从机修改后
# 这里的hostM1对应schema.xml中的readHost标签
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 hostS1
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 hostS1
192.168.111.128 hostS18、开启主机(127)mycat
1、使用窗口(A)进入到mycat中的logs文件中 /usr/lwl/soft/mycat/mycat/logs
2、展示其中的日志文件
[root@hostM1 logs]# ls
2023-02 2023-03 console.log mycat.log mycat.pid wrapper.log
3、动态显示日志文件
tail -f wapper.log
4、然后再开启一个窗口(B)开启mycat
开启命令:mycat start
5、在窗口(A)中的日志中可以观察到
MyCAT Server startup successfully. see logs in logs/mycat.log
即是mycat开启成功9、连接mycat
mysql -uroot -proot -h192.168.111.127 -P8066 -DTESTDB
-u 代表输入用户
-p 代表密码
-h 代表IP地址
-P 代表端口号
-D 代表连接的数据库名称10、测试是否连接成功
向TESTDB数据库的test1表中添加一条数据
切换到192.168.111.127的mysql数据库,查看test1的表中是否有相应的数据,如果有就代表读写分离成功
测试读写:
连接mycat的mysql,进行添加个查询操作,并且查看操作日志3.3 主从复制
3.3.1 主从复制的原理
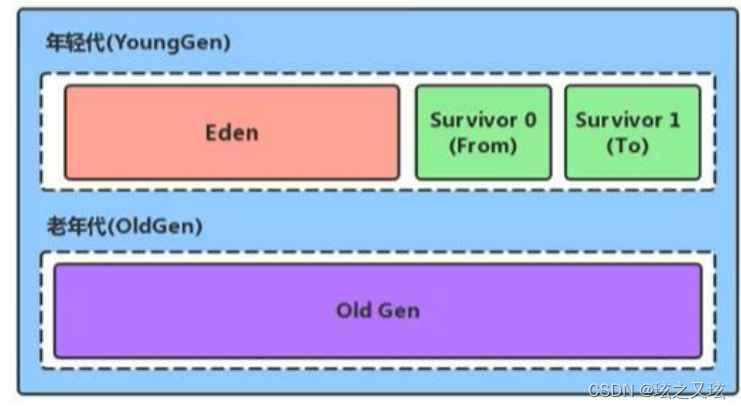
mysql要做到主从复制,其实依靠的是二进制日志,即:假设主服务器叫Master,从服务器叫Slave;主从复制就是Slave跟着Master学,Master做什么,Slave就做什么。 那么Slave怎么同步Master的动作呢?现在Master有一个日志功能,把自己所做的增删改查的动作全都记录在日志中,Slave只需要拿到这份日志,照着日志上面的动作施加到自己身上就可以了。这样就实现了主从复制,具体实现如下图:

3.3.2 主从复制的好处
1) 实现服务器负载均衡
2) 通过复制实现数据的异地备份
3) 提高数据库系统的可用性3.3.3 配置主从复制
1、配置主从复制的要求
1、配置主从复制要求主机、从机安装相同版本的mysql
2、主机、从机的mysql中都需要有远程连接的权限
3、两台服务器都关闭防火墙
systemctl stop firewalld
4、主机和从机能够互相连通(能ping通)
在主机127执行:ping 192.168.111.128
在从机128执行:ping 192.168.111.1272、两台主机都开启mysql服务
systemctl start mysqld 或者 service mysqld start3、修改mysql的配置文件 (/etc/my.cnf)
主机:修改192.168.111.127的配置文件
[mysqld] # 一定要在这下面配置
log-bin=mysql-bin # 二进制的文件
server-id=127 # 唯一的标识 默认是1
从机:修改192.168.111.128的配置文件
[mysqld] # 一定要在这下面配置
log-bin=mysql-bin # 二进制的文件
server-id=128 # 唯一的标识 默认是1
注:
1、可以只在一台服务器上配置即可,一定要保证主机和从机的server-id不一样
2、log-bin可以不写,会有默认的名字4、重启mysql服务
systemctl restart mysqld 或者 service mysqld restart5、主机(127)连接mysql查看主机的状态
show master status;
6、从机(128)连接mysql配置对应的主机信息
连接mysql后,配置对应的主机信息,
主机的ip地址,主机的用户名和密码,二进制文件名字和位置
change master to master_host='192.168.111.127',
master_user='root',master_password='root',
master_log_file='mysql-bin.000001',master_log_pos=154;
7、启动从机
-- 启动从机
start slave;
-- 查看从机状态
show slave status\G;问题1、Slave_IO_Running: No

解决uuid相同的问题
1、可以先查看两台服务器的uuid
show variables like '%server_uuid%';
2、查找auto.cnf
find / -name auto.cnf
3、这个文件可以修改任何一个数字,也可以直接删除
这里修改了从机(128)的配置文件
[auto] #修改前
server-uuid=647f2cac-b7ff-11ed-aefd-000c29102664
[auto] #修改后 将倒数第五位的0改为7
server-uuid=647f2cac-b7ff-11ed-aefd-000c29172664
修改后可以先停止从机
stop slave;
重启主机和从机的mysql服务
systemctl restart mysqld;
再开启从机
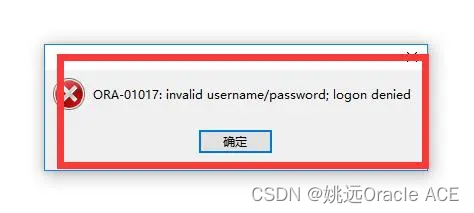
start slave;问题2、Slave_IO_Running: Connecting

出现上图就是连接不上主机:
1、防火墙没有关闭
2、主机的用户名和密码不对
3、日志文件的名字不对
4、pos的值不对
先停止从机:
stop slave;
重启主机和从机的mysql服务
systemctl restart mysqld;
再开启从机
start slave;
再排除情况
可以先查看日志文件名字是否更改8、验证主从复制是否成功
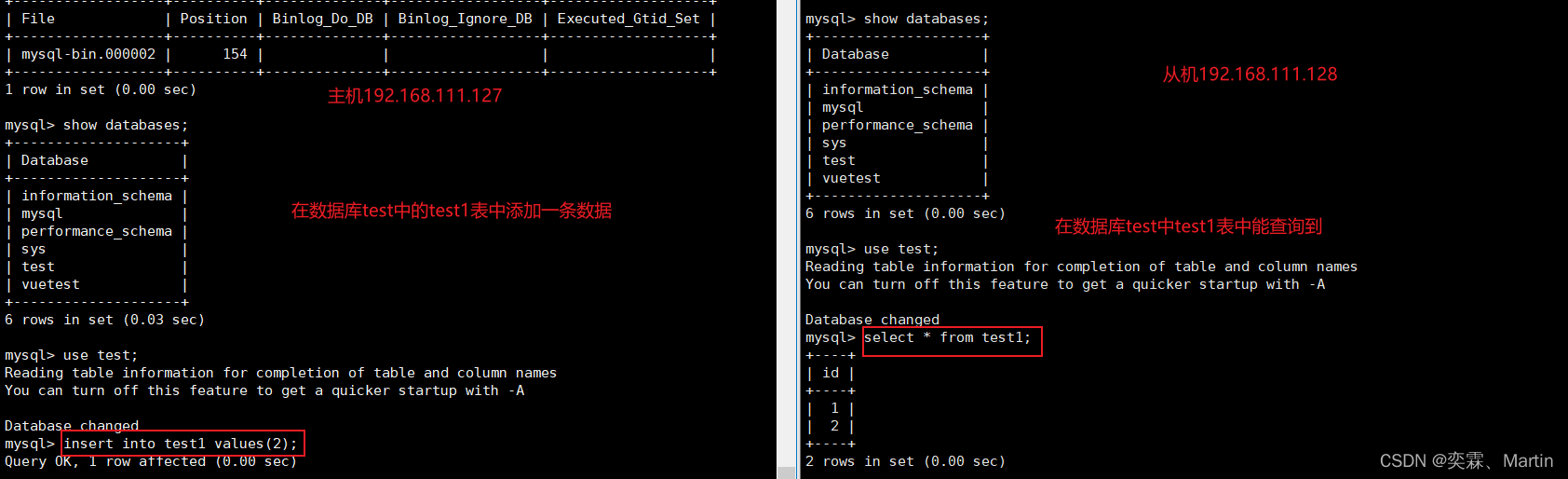
在主机中test库中test1表中添加一条数据
然后在从机的test库中的test1表进行查询,能查到就代表配置成功