DLT-Net:可行驶区域、车道线和交通对象的联合检测
- I. INTRODUCTION
- II. ANALYSIS OF PERCEPTION
- IV. DLT-NET
- A. Encoder
- B. Decoder
- 1) Drivable Area Branch(可行驶区域分支)
- 2) Context Tensor(上下文张量)
- 3) Lane Line Branch(车道线分支)
- 4) Traffic Object Branch(目标检测对象分支)
- C. Loss Function and Training
- V. EXPERIMENTS
- A. Dataset and Experimental Setting
- B. Drivable Area Results(可驾驶区域结果)
- VI. CONCLUSION
DLT-Net: Joint Detection of Drivable Areas, Lane Lines, and Traffic Objects
I. INTRODUCTION

图1。我们的方法的输入和结果。我们的目的是联合检测可行驶区域、车道线和交通目标。(b)中,绿色区域为可行驶区域,橙色线为车道线,红色边界框为交通对象。
Mask R-CNN提出了联合检测对象和段实例,每个任务都达到了最先进的性能。但它不能直接应用于智能交通领域,因为它不能检测可行驶区域和车道线。我们认为,可行驶区域、车道线和交通目标的检测是智能车辆最基本的感知任务。
我们工作的两项贡献是:
-
可行驶区域、车道线和交通目标检测集成为一个框架。
-
设计了上下文张量,通过融合可驱动区域解码器与其他两个解码器的特征映射实现任务间的互信息共享。
II. ANALYSIS OF PERCEPTION

假设智能车辆只需要使用一个摄像头进行行驶,可行驶区域的检测是感知中最紧迫的任务。当车辆行驶时,可行驶区域可能发生迅速变化。如果经常进行路径规划,就不能保证车辆的高速行驶。在大多数情况下,中心线是最好的选择,它突出了车道线检测的重要性
IV. DLT-NET
我们的网络简单而有效。我们的目标是使用统一的网络来检测可行驶区域、车道线和交通对象。该网络共享一个编码器,并为每个任务分为三个解码器。不同的部分用不同的颜色表示。在解码器中,我们设计了上下文张量结构来融合三个任务的特征映射。整个网络可以端到端的训练。
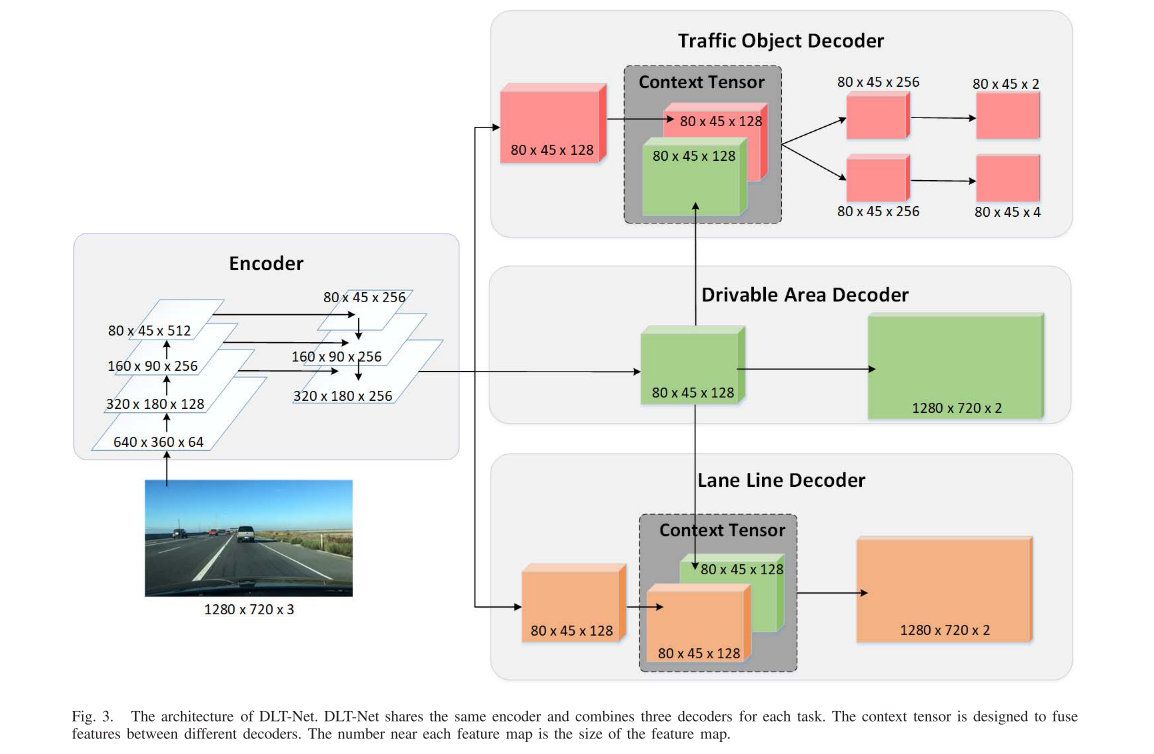
图3,DLT-Net的架构。DLT-Net共享相同的编码器,并为每个任务组合三个解码器。上下文张量的设计是为了融合不同解码器之间的特征。每个feature map附近的数字就是feature map的大小。
A. Encoder
本文采用VGG16和特征金字塔结构作为编码器。
首先,通过VGG16使用卷积层和池化层生成5种不同大小的特征图。最后一层的尺寸为(W/16, H/16, 512)。然后所有完全连接的层在这里被移除。
研究表明,深层特征和浅层特征对感知任务都有重要作用。为了结合深层特征和浅层特征,我们采用策略融合相邻层。融合方法为单元平均运算。融合三个深度最大的feature map,最终feature map的大小为(W/4, H/4, 256)。最后的特征图用于为三个解码器提供信息。
B. Decoder
1) Drivable Area Branch(可行驶区域分支)
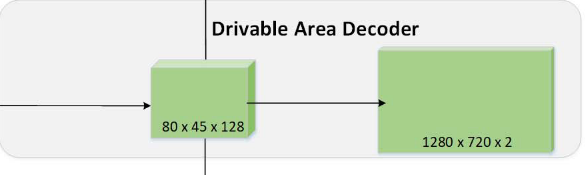
可驱动区域分支的最终输出特征图的大小为(W, H, 2),这两个通道表示每个像素对于可行驶区域和背景的可能性。
2) Context Tensor(上下文张量)
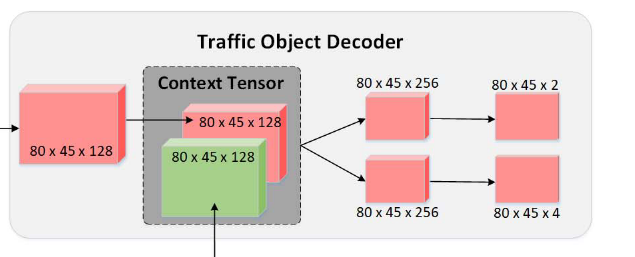
我们设计了上下文张量来融合可驾驶区域分支与其他两个分支的特征图。可行驶区域包含所有车道线,不可行驶区域包含所有潜在交通对象。交通对象在很大程度上是可驾驶区域边界的一部分。因此,可驾驶区域对其他两个任务有实际的指导。
例如,在其他的探测器中,车道线很容易与路缘混淆。由于车道线只存在于可行驶区域,因此我们的模型利用上下文张量具有很强的识别能力。
在此基础上,我们构建了上下文张量来分担任务间的指定影响。在上下文张量中,使用连接操作融合特征映射。在我们的模型中使用了两个上下文张量。
3) Lane Line Branch(车道线分支)
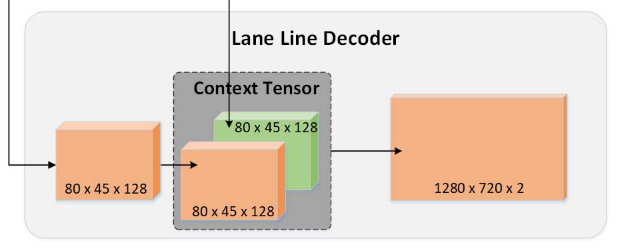
车道线部分用橙色表示。车道线分支与可行驶区域具有相同的结构。融合特征图的大小为(W/16, H/16, 256)。最终的特征图也有两个通道,表示每个像素对于车道线和背景的可能性。
4) Traffic Object Branch(目标检测对象分支)
其关键思想是用焦点损失函数代替原损失函数。在上下文张量之后,将网络分为两部分,一部分用于分类,另一部分用于边界盒回归。
C. Loss Function and Training
采用多任务丢失来训练整个网络。式1为总损失函数,为四部分之和。
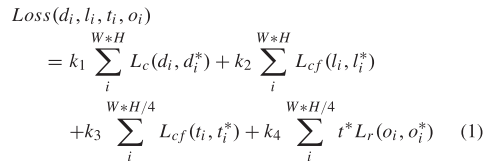
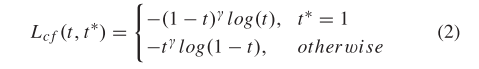
V. EXPERIMENTS
A. Dataset and Experimental Setting
BDD数据集已经发布用于自动驾驶研究。这是一个很大的数据集,包含变化的天气、场景和一天中的时间。
本文利用BDD数据集对MultiNet进行再训练。然后在可行驶区域和交通目标检测任务中直接与我们的网络进行比较。
基本的DLT-Net也用于评估上下文张量。基本的DLT-Net是没有上下文张量结构的DLT-Net。换句话说,解码器在基本的DLT-Net中是完全分离的。
我们的CPU是Intel® Xeon® E5-2630 v4,我们的GPU是NVIDIA GTX TITAN Xp。
B. Drivable Area Results(可驾驶区域结果)

图4。可行驶区域检测结果的实例。绿色区域为检测到的可行驶区域。红色圈出的区域是假阳性和假阴性。

图5。交通对象检测结果示例。红色边界框为检测到的正确车辆,黄色边界框为误报车辆。

图6。车道线检测结果实例。红线是检测到的正确车道线。黄线是假阳性。

图7。一些使用DLT-Net的假阳性和假阴性。(a)可行驶区域检测结果。(b)红色边框为检测到的正确车辆,黄色边框为假阴性车辆。©车道线检测结果。红线为检测正确车道线,黄色椭圆为假阴性。
VI. CONCLUSION
提出了一种可行驶区域、车道线和交通目标联合检测的统一网络DLT-Net。这三个任务被认为是自动驾驶汽车最关键的感知任务。该网络在BDD数据集的所有三个任务中都显示出竞争性能。在DLT-Net中设计的上下文张量显著提高了检测精度,使其性能优于多项网络。
考虑到智能交通应用的性质,与将每个任务分开相比,统一网络具有固有的优势。此外,与分离每个解码器相比,上下文张量结构在提高检测精度方面显示出固有的优势。











![[文件操作] File 类的用法和 InputStream, OutputStream 的用法](https://img-blog.csdnimg.cn/d7d099a838f74cc88a171c0ed8efbf3b.png)
