文献阅读(46)——MPViT
文章目录
- 文献阅读(46)——MPViT
- MPViT
- 先验知识/知识拓展
- 文章结构
- 文章结果
- 1. ImageNet 分类
- 2. 物体检测和实例分割
- 3. 语义分割
- 方法
- 1. MPViT architecture
- 2. MS-Patch Embed Block
- 3. MP-Transformer Block 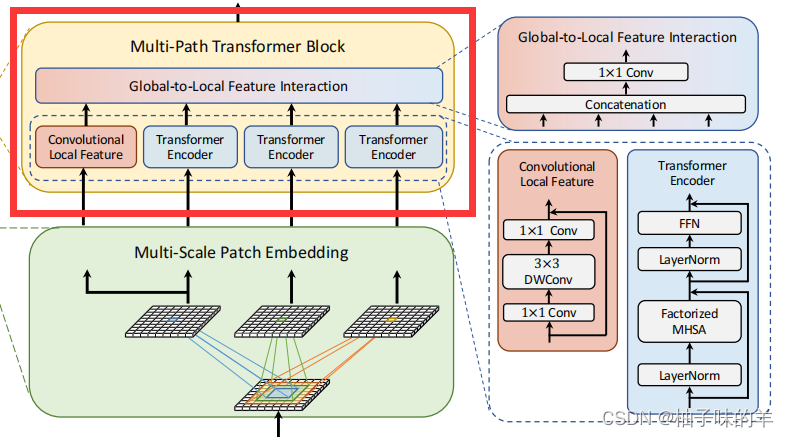
- Global-to-Local Feature Interaction
- 4. 模型配置
- 总结
- 1. 文章优点
- 2. 文章不足
- 可借鉴点/学习点?
MPViT
MPViT : Multi-Path Vision Transformer for Dense Prediction

CVPR
先验知识/知识拓展
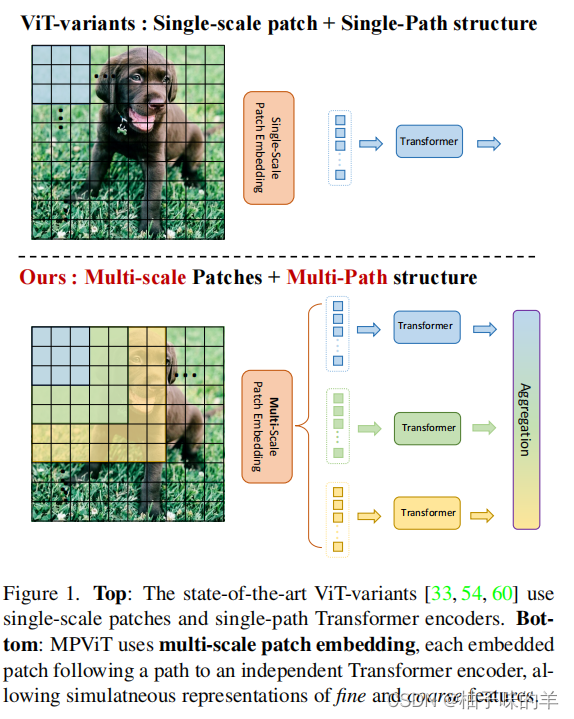
新的backbone,里面用到transformer(顾名思义用到注意机制),为了弥补transformer的缺点,增加了卷积部分考虑全局信息
文章结构
-
摘要
-
introduction
-
related works
- ViT
- comparison of concurrent works
-
multi-path vision transformer(MPViT)(★★★★★重点)
- 网络结构
- 多尺度patch embedding
- global to local 特征融合
- 模型配置
-
实验
-
讨论和总结
文章结果
无论是在ImageNet上做分类,物体检测和实例分割,还是语义分割上几乎都可以达到SOTA级别
1. ImageNet 分类
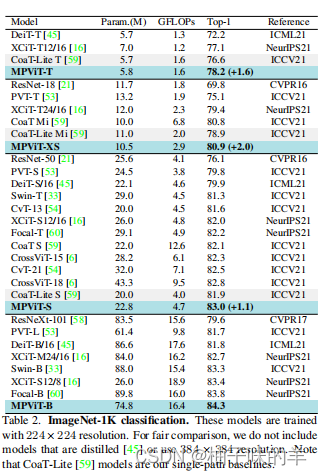
2. 物体检测和实例分割
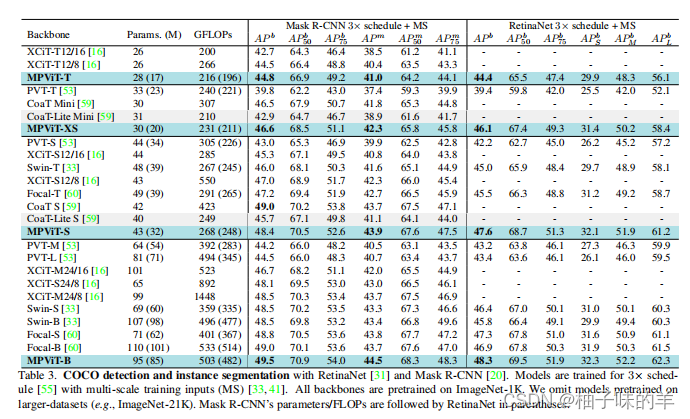
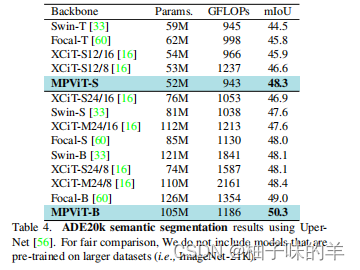
3. 语义分割
方法
1. MPViT architecture
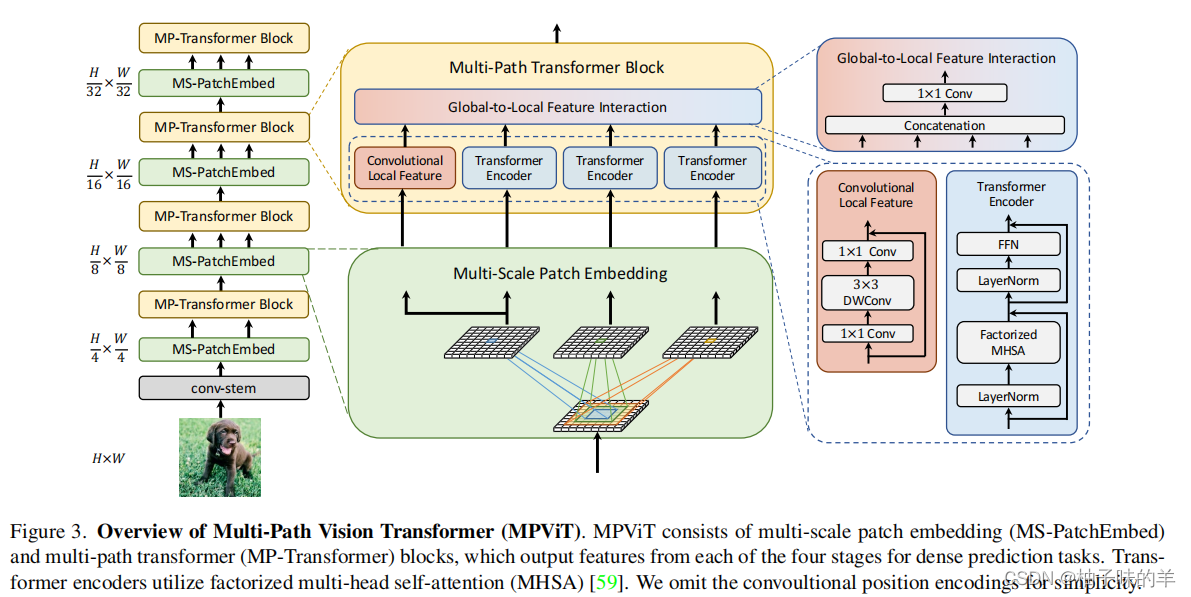
作为backbone,主要功能就是提取数据特征,相当于一个encoder,后面做什么任务只需要根据任务进行相应的decoder就OK。
主要包括4个stage,每个stage都由两个block组成,一个是MS-Patch Embed,另一个是MP-Transformer。
2. MS-Patch Embed Block
Multi-Scale Patch Embedding,一看到Multi-Scale大家应该有种亲切感,多尺度已经很多文章了,感觉被研究的花里胡哨了。在这篇文章中,作者使用的卷积网络可以通过改变stride和padding调整token的序列长度,即使是不同大小的patch也可以输出相同尺度的特征图。在这个过程中使用到三个不同的卷积核,分别为33,55和77,但是考虑到参数量,因为一个55的卷积核和2个33的卷积核具有相同的感受野,1个77卷积核和3个33卷积核具有相同的感受野,所以全部使用33的卷积核替代55和77的卷积核。(很巧妙!极大地减少了时间成本)

3. MP-Transformer Block 
在这个部分因为transformer其实是需要有位置编码的,针对不同长度的token需要不同长度的位置编码,在这个地方作者使用卷积生产位置编码!——这一点确实难以理解,因为一般的位置编码无非就是0,1,2,3这样子的,使用卷积学到的信息你怎么能确定学习到的是位置信息?但是确实有效果。大概是这样的思路:
- 进入transformer的是一个序列(可以将其假想为一个一维数据)
- 将它reshape成一个矩阵(特征图):feature_ori
- 使用卷积处理feature_ori得到feature_conv
- feature = feature_ori+feature_conv
- 再讲feature矩阵展开为一个一维数据就是为知编码
(咱也不知道为什么就可以使用卷积生成为知编码,但是确实消融实验是由效果的)
这里上一步得到的三张特征图,其中由3*3卷积得到的特征图需要copy一个作为卷积神经网络的输入(用它表示特征的局部信息),其他三个特征图进入transformer。为什么这么做呢?
- 首先,transformer的内部是自注意力机制,他可以学习到较长范围的依赖关系(全局上下文信息)但是他很容易忽略结构性信息和局部关系,也正是由于注意力机制,他会更加关注图片的关键部分
- 其次,CNN具有平移不变性,这就使得卷积后得到的特征局部依然有连通性——图像中的每个patch都是用相同的权重处理的。
- 因此,MPViT就用这种互补的方式将卷积得到的local信息和transformer得到的global信息拼接——Global-to-Local Feature Interaction
Global-to-Local Feature Interaction
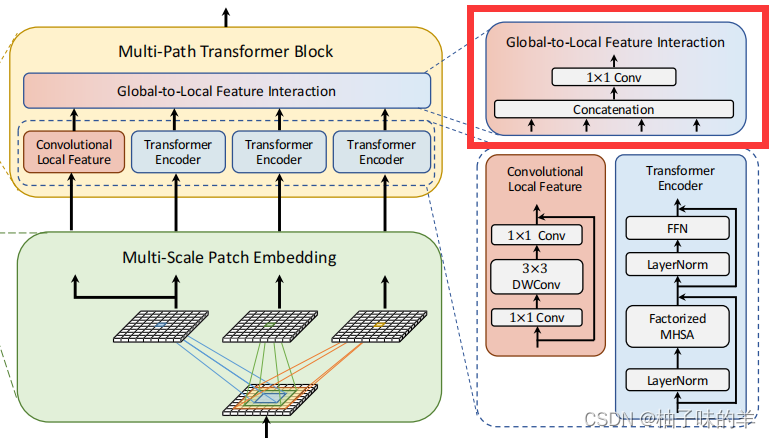
在局部信息的部分增加了一个残差模块。
4. 模型配置
在这部分,其实作者说明了他们transformer中用的不是平时大家熟悉的自注意力机制,是改进版
- 一般的自注意力机制
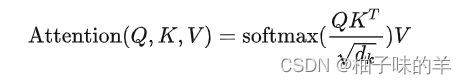
- 改进版(可以降低计算量)
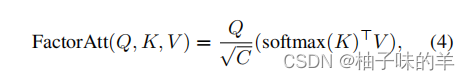
这是一个叫CoaT的文章提出的,证明了确实使用这种方式计算会减少计算量-
总结
1. 文章优点
- 学到了新的位置编码的方式
- 通过卷积层的stride和padding的处理,不同大小的patch可以得到相同尺度的特征——一个非常棒的多尺度思想
- 既考虑全局信息又考虑局部信息,卷积+transformer结合
2. 文章不足
- 使用卷积计算得到位置编码,理解不了,引用了一篇但是也没有解释清楚
可借鉴点/学习点?
无论是分类,物体检测还是语义分割,其实encoder得到一个完整的(既有全局又兼顾局部)特征非常重要,作者的这个思想很新奇~





![[文件操作] File 类的用法和 InputStream, OutputStream 的用法](https://img-blog.csdnimg.cn/d7d099a838f74cc88a171c0ed8efbf3b.png)