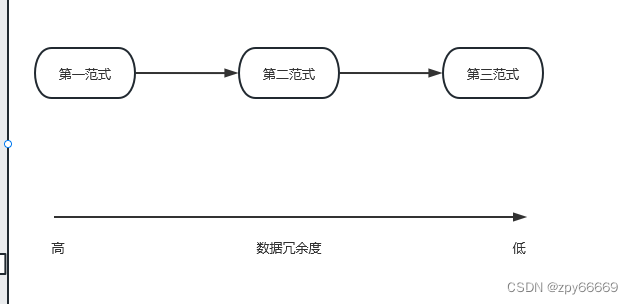
三大范式图解概括
第一范式(1NF)
确保数据库表字段的原子性
会存在数据冗余过大,插入异常,删除异常,修改异常的问题
举例:
某个字段name:‘西瓜 1566666‘
依照第一范式就需要拆分成 name:‘西瓜’ ,phone:'1566666’
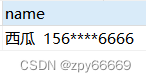 ------>拆分成
------>拆分成 
第二范式(2NF)
首先要满足第一范式,另外包含两部分内容,一是表必须有一个主键;二是非主键列必须完全依赖于主
键,而不能只依赖于主键的一部分。
举例:
这是一个课程关系表,
其中fraction(分数)完全依赖subject(课程)
其中name(姓名),age(年龄)完全依赖s_num(学号)
不符合第二范式
会导致数据冗余(学生考n门课程,姓名年龄有n条记录)、插入异常(插入一门课程,因为没有学号,无法保存新课程记录)等问题。
应拆分成三个表
studen(表名) id,s_num, name age
course(表名) id,subject, fraction
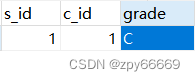
student_course(表名) s_id ,c_id ,grade
 -------->拆分成
-------->拆分成
 ------
------ -----
-----
第三范式(3NF)
首先要满足第二范式,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列
A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
举例:
为了满足第三范式,消除依赖传递,应该继续拆分
 ----
---- -----
----- ----
----
2NF和3NF的区别?
2NF依据是非主键列是否完全依赖于主键,还是依赖于主键的一部分。
3NF依据是非主键列是直接依赖于主键,还是直接依赖于非主键。
个人看法
实际业务中除了数据冗余,还有性能、复杂度、容灾、安全性等多个考虑因素。如果为了减少冗余,造成数据库性能暴跌,或是编程复杂性大增,都是不可接受的。但是具体到底选择向哪个方向妥协,这就是工作经验了。
如果完全按照第三范式,那么数据的查询一定需要大量的表关联,自然会造成性能上的问题,在阿里巴巴开发规约中,明确说明了禁止超过三表关联,为了满足规范,最简单的解决方法就是可以允许表中一些字段的传递依赖,造成数据冗余 ,这样在一些查询query的情况下,可以不用频繁的联表操作,提高查询效率,典型的空间换时间,具体冗余和分表的界限就需要根据实际开发来解决