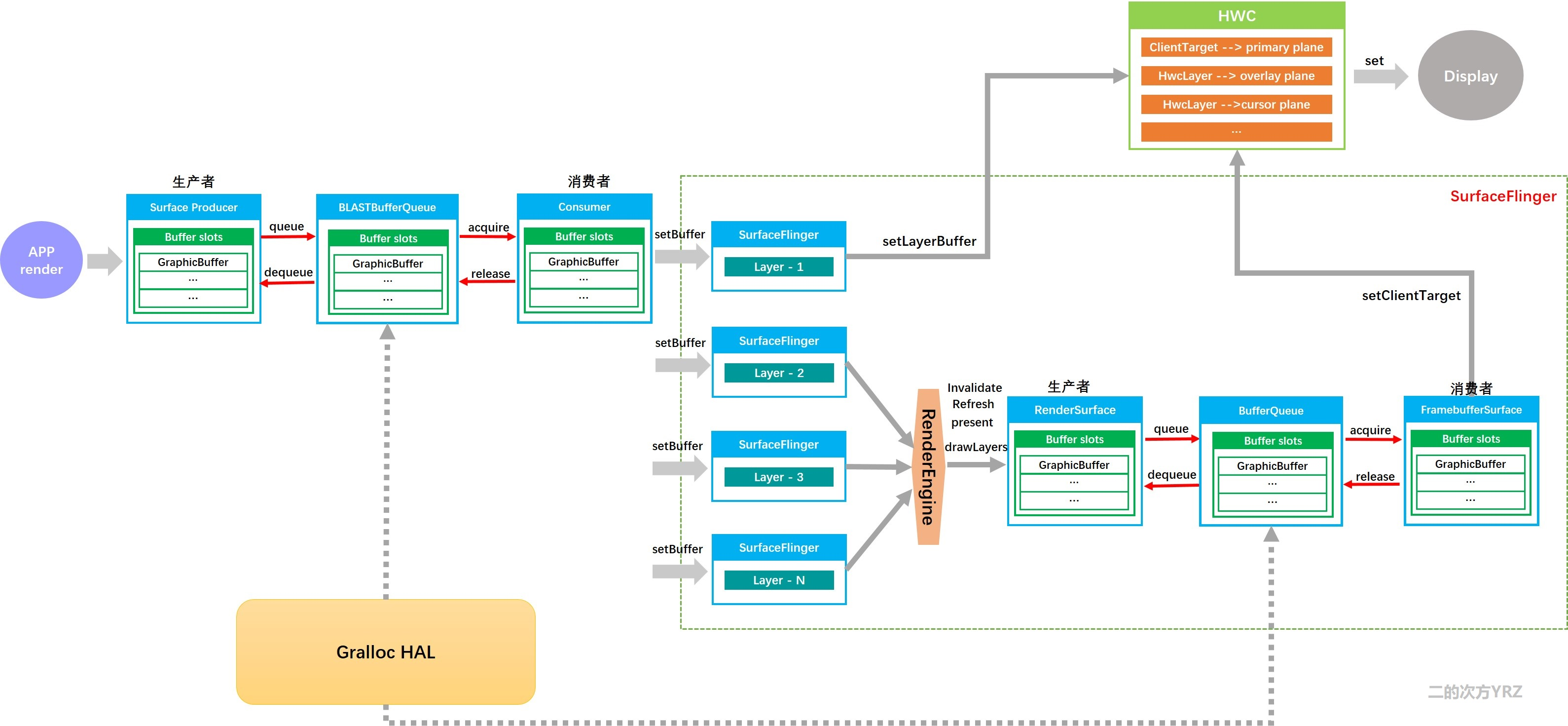
之前看到过的一篇论文,挺有意思的,虽然查到了有讲解的博客,但是不太符合我的思考逻辑 于是自己梳理一下。
CVPR 2022丨清华大学提出:无监督域泛化 (UDG)_我爱计算机视觉的博客-CSDN博客
方法引入:
针对现有的处理域泛化问题的方法存在一个弊端:高度依赖于充足的已标注数据——这些获得是昂贵甚至困难的,因此考虑引入无监督学习:利用未标注数据对对模型进行pretrain、再利用已标注数据进行充分训练并在没有见过的目标域进行测试。
测试是与在ImageNet上的预训练模型对比,有相当甚至优秀的表现,即使数据更大部分是无标注的。
背景介绍:
目前DNN表现好,但是在可观的distribution shift之后表现不好(要求OOD假设),因此催生了DG问题。
然鹅,现在的DG问题往往需要充分的已标注数据。因此有了UDG(unsupervised domain generalization),UDG的目标是在无监督的情况下学习能跨领域通用的辨别性表征,从而减少DG方法对标记数据的依赖性。
在无监督领域,已有一个方法是对比学习(contrastive learning)原文如下:
In the field of unsupervised learning [22, 50, 65], contrastive learning (CL) advances in discriminative representation learning for downstream tasks compared to its counterparts [6, 23, 57]. Actually, the objective of CL, which is to maximize the similarity between a given image and its variant under disturbance while contrasting with negatives [16, 34, 66], agrees with the target of DG. However, current CL only learns robust representations against predefined perturbation under independent and identically distributed (I.I.D) hypothesis [3, 26, 28] and fails to consider severe distribution shifts across domains beyond predefined perturbation types [45, 67]. With samples from various do[1]mains as negative pairs, current CL methods leverage both domain-related (i.e., features irrelevant to categories) and category-discriminative features to push their representations away. Furthermore, in UDG, the distribution shifts across domains in training data are significant and can not be fully counterweighed via data transformations (for instance, one can hardly transform a dog in sketch to photo). The strong heterogeneity induces models to leverage the domain-related features to distinguish one sample from its negatives [2, 52] and thus, hinders the learning of an invariant representation space where dissimilarity across domains is minimized [41,43]. Thus current contrastive learning can not perfectly handle the UDG problem.
在无监督学习领域[22, 50, 65],与同行相比,对比学习(CL)在下游任务的鉴别性表示学习方面取得了进展[6, 23, 57]。实际上,对比学习的目标是在干扰下最大限度地提高给定图像和其变体之间的相似性,同时与底片进行对比[16, 34, 66],与DG的目标一致。然而,目前的CL只在独立同分布(I.I.D)假设下针对预定的扰动学习稳健的表征[3, 26, 28],并且未能考虑超出预定扰动类型的跨域严重分布转变[45, 67]。以各种不同域的样本为负样本,目前的CL方法同时利用领域相关的(即与类别无关的特征)和类别区分的特征来推开他们的表征。此外,在UDG中,训练数据中各领域的分布偏移是显著的,不能通过数据转换来完全抵消(例如,我们很难将素描中的狗转换为照片)。强烈的异质性诱导模型利用领域相关的特征来区分一个样本和它的反面样本[2,52],因此,阻碍了不变的表示空间的学习,在这个空间里,各领域的不相似性是最小的[41,43]。因此,目前的对比性学习不能完美地处理UDG问题
因为UDG的必要性和目前现有CL方法的不可靠性,提出了一种新的CL方法DARING。两个领域的相似度越高,负面样本对中的两个样本就越有可能分别来自这两个领域。直观地说,如果考虑来自两个领域的样本在分布上有巨大的差异,那么其与领域相关的特征有足够的鉴别力,可以将它们区分开来、并反过来在表示空间中提升各领域的差异性。相反,如果一对负面的样本来自一个领域,并且具有相同的领域相关特征,那么就会学习领域不相关的表征来对比它们。这就是我们想要的领域不相关的稳定特征了。
问题表述:
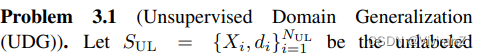

两个假设,(1)表示不同域之间没有overlap,(2)表示测试域和有标签数据集的类别空间一致。
根据未标记的数据分布和标记的数据之间的类别和领域空间的交集,具体描述了支持无监督领域泛化(UDG)的所有可能的4种设置:
全相关 当数据被部分随机标注时,未标注的数据和标注的数据是同源的,因此它们之间的类别空间和域空间可以有重叠。形式上,Supp(P SUL D ) = Supp(P SL D ),Supp(P SUL Y ) = Supp(P SL Y )。
域相关 一个更具挑战性但又常见的设定是,无标签数据和有标签数据共享同一个域空间,而无标签数据和有标签数据的类别空间之间没有重叠。形式上,Supp(P SUL D )=Supp(P SL D ),Supp(P SUL Y )∩Supp(P SL Y ) = ∅。
类别相关 与领域相关类似,这种设置假设未标记数据和标记数据共享相同的类别空间,而未标记数据和标记数据的领域空间之间没有重叠。形式上,Supp(P SUL D ) ∩Supp(P SL D ) = ∅,Supp(P SUL Y ) = Supp(P SL Y )。
不相关 当无法获得与标注数据相同来源(领域)的额外数据时,未标注数据和标注数据的类别和领域空间之间可能没有重叠,导致最具挑战性和灵活性的设置。形式上,Supp(P SUL D ) ∩Supp(P SL D ) = ∅,Supp(P SUL Y ) ∩Supp(P SL Y ) = ∅


具体的方法主要参考参考文献[2],放图如下:
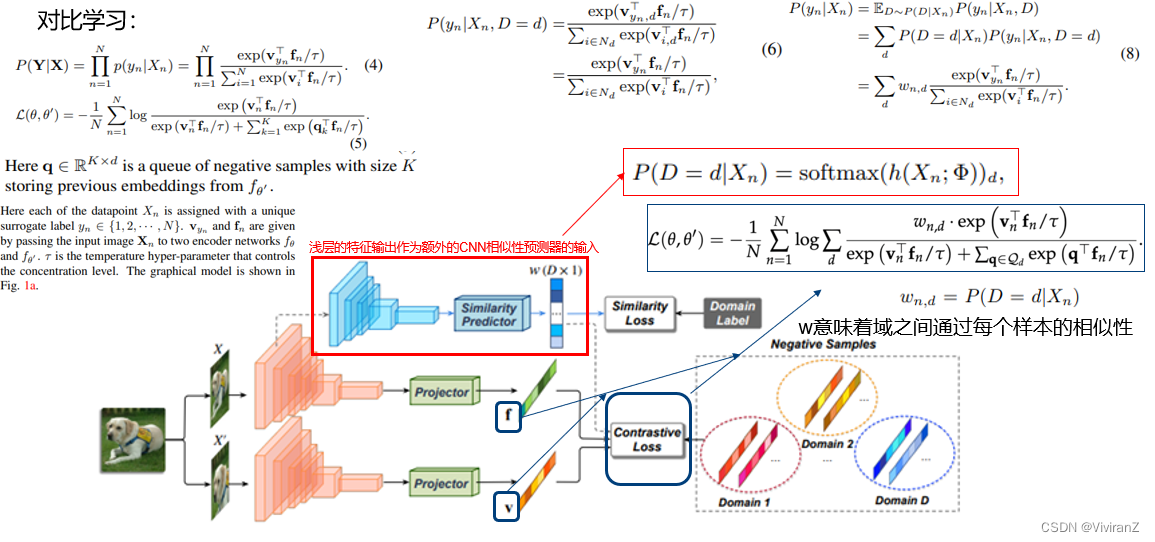
([2]参考了一篇博客安全验证 - 知乎知乎,中文互联网高质量的问答社区和创作者聚集的原创内容平台,于 2011 年 1 月正式上线,以「让人们更好的分享知识、经验和见解,找到自己的解答」为品牌使命。知乎凭借认真、专业、友善的社区氛围、独特的产品机制以及结构化和易获得的优质内容,聚集了中文互联网科技、商业、影视、时尚、文化等领域最具创造力的人群,已成为综合性、全品类、在诸多领域具有关键影响力的知识分享社区和创作者聚集的原创内容平台,建立起了以社区驱动的内容变现商业模式。![]() https://zhuanlan.zhihu.com/p/361325581 )
https://zhuanlan.zhihu.com/p/361325581 )
其实我们看到的这篇论文整个逻辑基本上是对比学习,主要贡献和创新点是新加入了红框表示的相似性预测器,利用预测器对下面的对比学习进行重加权。
负样本生成的方法主要参考[3],具体来说就是跟随正样本的变化改变负样本,
同样找到了安全验证 - 知乎知乎,中文互联网高质量的问答社区和创作者聚集的原创内容平台,于 2011 年 1 月正式上线,以「让人们更好的分享知识、经验和见解,找到自己的解答」为品牌使命。知乎凭借认真、专业、友善的社区氛围、独特的产品机制以及结构化和易获得的优质内容,聚集了中文互联网科技、商业、影视、时尚、文化等领域最具创造力的人群,已成为综合性、全品类、在诸多领域具有关键影响力的知识分享社区和创作者聚集的原创内容平台,建立起了以社区驱动的内容变现商业模式。![]() https://zhuanlan.zhihu.com/p/370180403
https://zhuanlan.zhihu.com/p/370180403
但是这一篇对于负样本生成的讲解我没太看懂、后补

[1]Zhang X, Zhou L, Xu R, et al. Towards unsupervised domain generalization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 4910-4920.
[2]Tsai T W, Li C, Zhu J. Mice: Mixture of contrastive experts for unsupervised image clustering[C]//International conference on learning representations. 2021.
[3]Hu Q, Wang X, Hu W, et al. Adco: Adversarial contrast for efficient learning of unsupervised representations from self-trained negative adversaries[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1074-1083. https://zhuanlan.zhihu.com/p/370180403

![[ 云计算入门与实战 - AWS ] 在控制台创建 Amazon EC2 实例](https://img-blog.csdnimg.cn/20e9cf4402d94f6fa8245139a5c0b92a.png)