文章目录
一、merge() 函数 1. inner 2. left 和 right 3. outer 二、set_index() 函数 三、drop_duplicates() 函数 四、tolist() 函数 五、视频数据分析案例
在最开始,我们先导入常规的 numpy 和 pandas 库。 import numpy as np
import pandas as pd
为了方便维护,数据在数据库内都是分表存储的,比如用一个表存储所有用户的基本信息,一个表存储用户的消费情况。 所以,在日常的数据处理中,经常需要将两张表拼接起来使用,这样的操作对应到 SQL 中是 join,在 Pandas 中则是用 merge 来实现。这篇文章就讲一下 merge 的主要原理。 上面的引入部分说到 merge 是用来拼接两张表的,那么拼接时自然就需要将用户信息一一对应地进行拼接,所以进行拼接的两张表需要有一个共同的识别用户的键(key)。 总结来说,整个 merge 的过程就是将信息一一对应匹配的过程,下面介绍 merge 的四种类型,分别为 inner、left、right 和 outer。 pd. merge( left, right, how: str = 'inner' , on= None , left_on= None , right_on= None , left_index: bool = False ,
right_index: bool = False , sort: bool = False , suffixes= ( '_x' , '_y' ) , copy: bool = True , indicator: bool = False , validate= None , )
merge() 函数的参数含义如下: left/right 表示两个不同的 DataFrame 对象。 how 表示要执行的合并类型,从 {‘left’, ‘right’, ‘outer’, ‘inner’} 中取值,默认为 inner 内连接。 on 表示指定用于连接的键(即列标签的名字),该键必须同时存在于左右两个 DataFrame 中,如果没有指定,并且其他参数也未指定,那么将会以两个 DataFrame 的列名交集做为连接键。 left_on 表示指定左侧 DataFrame 中作连接键的列名。该参数在左、右列标签名不相同,但表达的含义相同时非常有用。 right_on 表示指定左侧 DataFrame 中作连接键的列名。 left_index 为布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键。 right_index 为布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键。 sort 为布尔参数,默认为 False,则按照 how 给定的参数值进行排序。设置为 True,它会将合并后的数据进行排序。 suffixes 表示字符串组成的元组。当左右 DataFrame 存在相同列名时,通过该参数可以在相同的列名后附加后缀名,默认为 (‘x’,‘y’)。 copy 默认为 True,表示对数据进行复制。 这里需要注意的是,Pandas 库的 merge() 支持各种内外连接,与其相似的还有 join() 函数(默认为左连接)。 merge() 的 inner 的类型称为内连接,它在拼接的过程中会取两张表的键(key)的交集进行拼接。 下面以图解的方式来一步一步拆解。
首先我们有以下的数据,左侧和右侧的数据分别代表了用户的基础信息和消费信息,连接两张表的键是 userid。 例如,我们先生成 df_1 的初始数据。 df_1 = pd. DataFrame( {
"userid" : [ 'a' , 'b' , 'c' , 'd' ] ,
"age" : [ 23 , 46 , 32 , 19 ]
} )
df_1
df_2 = pd. DataFrame( {
"userid" : [ 'a' , 'c' ] ,
"payment" : [ 2000 , 3500 ]
} )
df_2
使用 merge() 函数对 df_1 和 df_2 进行拼接。由于 df_2 中只有 a 和 c 的参数,因此,合并之后只有 a 和 c。 df_1. merge( df_2, on= 'userid' )
pd. merge( df_1, df_2, on= 'userid' )
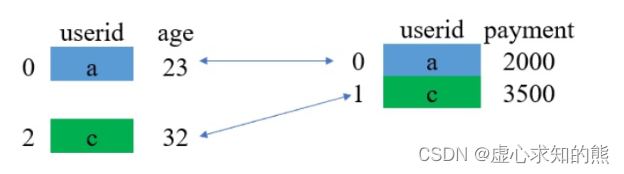
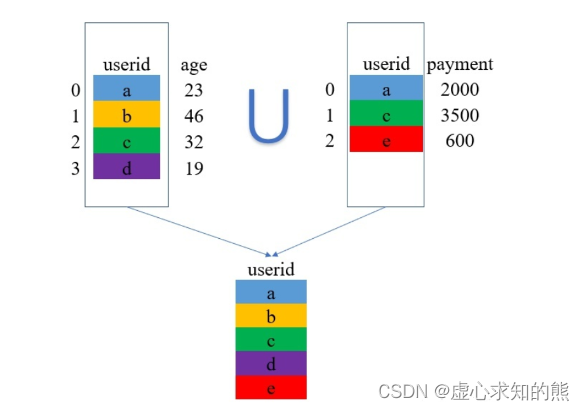
对于上述过程,我们可以采用如下图片进行解释。 (1) 取两张表的键的交集,这里 df_1 和 df_2 的 userid 的交集是 {a,c}。
相信整个过程并不难理解,上面演示的是同一个键下,两个表对应只有一条数据的情况(一个用户对应一条消费记录)。 那么,如果一个用户对应了多条消费记录的话,那又是怎么拼接的呢? 假设现在的数据变成了下面这个样子,在 df_2 中,有两条和 a 对应的数据: 我们同样用 inner 的方式进行 merge: df_1 = pd. DataFrame( {
"userid" : [ 'a' , 'b' , 'c' , 'd' ] ,
"age" : [ 23 , 46 , 32 , 19 ]
} )
df_2 = pd. DataFrame( {
"userid" : [ 'a' , 'c' , 'a' , 'd' ] ,
"payment" : [ 2000 , 3500 , 500 , 1000 ]
} )
pd. merge( df_1, df_2, on= "userid" )
整个过程除了对应匹配阶段,其他和上面基本都是一致的。 left 和 right 的 merge 方式其实是类似的,分别被称为左连接和右连接。这两种方法是可以互相转换的,所以在这里放在一起介绍。 left 在 merge 时,以左边表格的键为基准进行配对,如果左边表格中的键在右边不存在,则用缺失值 NaN 填充。 right 在 merge 时,以右边表格的键为基准进行配对,如果右边表格中的键在左边不存在,则用缺失值 NaN 填充。 这是什么意思呢?我们用一个例子来具体解释一下,这是演示的数据。
df_1 = pd. DataFrame( {
"userid" : [ 'a' , 'b' , 'c' , 'd' ] ,
"age" : [ 23 , 46 , 32 , 19 ]
} )
df_2 = pd. DataFrame( {
"userid" : [ 'a' , 'c' , 'e' ] ,
"payment" : [ 2000 , 3500 , 600 ]
} )
pd. merge( df_1, df_2, how= 'left' , on= "userid" )
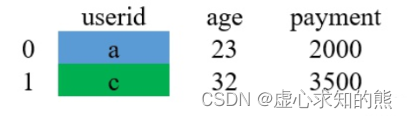
其过程可用如下图片进行解释。 (1) 以左边表格的所有键为基准进行配对。图中,因为右表中的e不在左表中,故不会进行配对。
(2) 若右表中的 payment 列合并到左表中,对于没有匹配值的用缺失值 NaN 填充。
对于 right 类型的 merge 和 left 其实是差不多的,只要把两个表格的位置调换一下,两种方式返回的结果就是一样的,如下: pd. merge( df_1, df_2, how= 'right' , on= "userid" )
outer 是外连接,在拼接的过程中它会取两张表的键(key)的并集进行拼接。看文字不够直观,还是上例子吧! 还是使用上方用过的演示数据
pd. merge( df_1, df_2, how= 'outer' , on= 'userid' )
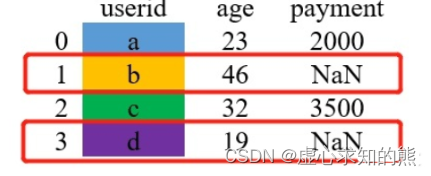
其过程可用如下图片进行解释。 取两张表键的并集,这里是 {a,b,c,d,e}。
专门用来将某一列设置为 index 的方法。 其语法模板如下: DataFrame. set_index( keys, drop= True , append= False , inplace= False , verify_integrity= False )
其参数含义如下: keys 表示要设置为索引的列名(如有多个应放在一个列表里)。 drop 表示将设置为索引的列删除,默认为 True。 append 表示是否将新的索引追加到原索引后(即是否保留原索引),默认为 False。 inplace 表示是否在原 DataFrame 上修改,默认为 False。 verify_integrity 表示是否检查索引有无重复,默认为 False。 首先,我们生成初始数据。 df = pd. DataFrame( { 'month' : [ 1 , 4 , 7 , 10 ] ,
'year' : [ 2012 , 2014 , 2013 , 2014 ] ,
'sale' : [ 55 , 40 , 84 , 31 ] } )
df
df. set_index( 'month' )
year sale
month
我们将 month 列设置为 index 之后,并保留原来的列。 df. set_index( 'month' , drop= False )
df. set_index( 'month' , append= True )
df. loc[ 0 ]
df. set_index( 'month' , inplace= True )
df
我们通过新建 Series 并将其设置为 index。 df. set_index( pd. Series( range ( 4 ) ) )
去重通过字面意思不难理解,就是删除重复的数据。 在一个数据集中,找出重复的数据删并将其删除,最终只保存一个唯一存在的数据项,这就是数据去重的整个过程。 删除重复数据是数据分析中经常会遇到的一个问题。通过数据去重,不仅可以节省内存空间,提高写入性能,还可以提升数据集的精确度,使得数据集不受重复数据的影响。 Panda DataFrame 对象提供了一个数据去重的函数 drop_duplicates()。 其语法模板如下: DataFrame. drop_duplicates( subset= None , keep= 'first' , inplace= False , ignore_index= False )
其部分参数含义如下: subset 表示要进去重的列名,默认为 None。 keep 有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。 inplace 为布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。 我们先生成初始数据,用以后续的观察操作。 df = pd. DataFrame( {
'brand' : [ 'Yum Yum' , 'Yum Yum' , 'Indomie' , 'Indomie' , 'Indomie' ] ,
'style' : [ 'cup' , 'cup' , 'cup' , 'pack' , 'pack' ] ,
'rating' : [ 4 , 4 , 3.5 , 15 , 5 ]
} )
df
32 Indomie cup 3.5
df. drop_duplicates( )
df. drop_duplicates( subset= [ 'brand' ] )
df. drop_duplicates( subset= [ 'brand' , 'style' ] , keep= 'last' )
pandas 的 tolist() 函数用于将一个系列或数据帧中的列转换为列表。 首先,我们查看 df 中的 索引取值,他的起始值是 0,终止值是 1,步长是 1。 df. index
df. index. tolist( )
问题 1:分析出不同导演电影的好评率,并筛选出 TOP20。 要求: (1) 计算统计出不同导演的好评率。 (2) 通过多系列柱状图,做图表可视化。 提示: (1) 好评率 = 好评数 / 评分人数。 (2) 可自己设定图表风格。 问题 2: 统计分析 2001-2016 年每年评影人数总量,求出不同剧的评分人数、好评数总和。 首先,我们导入 numpy 和 pandas 库,由于要进行图表可视化,因此,我们再导入 matplotlib 库。 import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
data = pd. read_csv( '爱奇艺视频数据.csv' , encoding= "gbk" )
data. info( )
pandas 读取 csv 文件默认是按块读取的,即不一次性全部读取。 另外 pandas 对数据的类型是完全靠猜的,所以 pandas 每读取一块数据就对 csv 字段的数据类型进行猜一次,所以有可能 pandas在读取不同块时对同一字段的数据类型猜测结果不一致。 low_memory=False 参数设置后,pandas 会一次性读取 csv 中的所有数据,然后对字段的数据类型进行唯一的一次猜测。这样就不会导致同一字段的 Mixed types 问题了。 但是这种方式真的非常不好,一旦 csv 文件过大,就会内存溢出;所以推荐用第 1 中解决方案。 (1) 设置 read_csv 的 dtype 参数,指定字段的数据类型。 pd. read_csv( sio, dtype= { "user_id" : int , "username" : object } )
(2) 设置 read_csv的low_memory 参数为 False。 pd. read_csv( sio, low_memory= False } )
data. head( 3 )
data. columns
data. groupby( '导演' ) [ [ '好评数' , '评分人数' ] ] . sum ( )
df_q1 = data. groupby( '导演' ) . sum ( ) [ [ '好评数' , '评分人数' ] ]
df_q1[ '好评率' ] = df_q1[ '好评数' ] / df_q1[ '评分人数' ]
df_q1
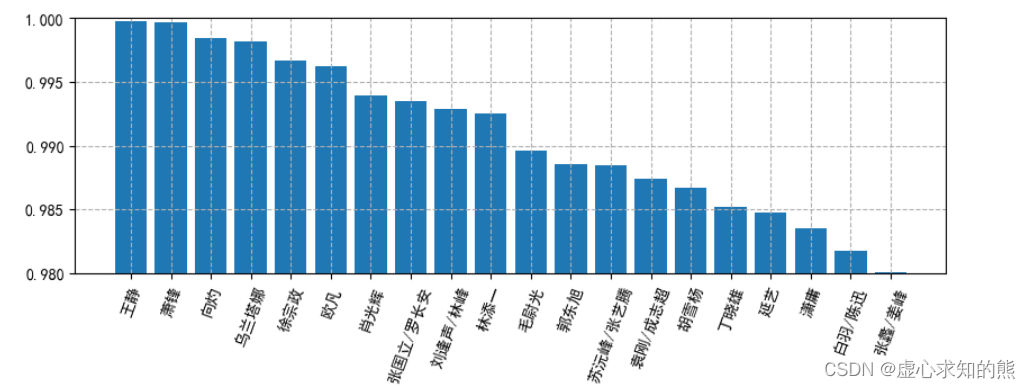
result_q1 = df_q1. sort_values( '好评率' , ascending= False ) [ : 20 ]
result_q1
plt. rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
plt. rcParams[ 'figure.dpi' ] = 100
plt. rcParams[ 'figure.figsize' ] = ( 10 , 3 )
plt. bar( result_q1. index, result_q1[ '好评率' ] )
plt. ylim( 0.98 , 1 )
plt. xticks( rotation= 70 )
plt. grid( True , linestyle= '--' )
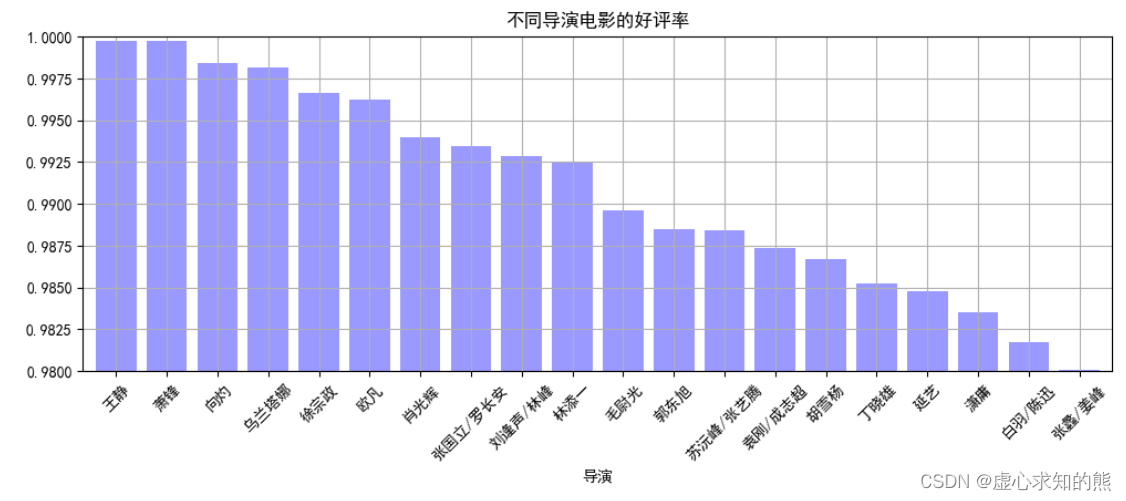
result_q1[ '好评率' ] . plot( kind= 'bar' ,
color = 'b' ,
width = 0.8 ,
alpha = 0.4 ,
rot = 45 ,
grid = True ,
ylim = [ 0.98 , 1 ] ,
figsize = ( 12 , 4 ) ,
title = '不同导演电影的好评率' )
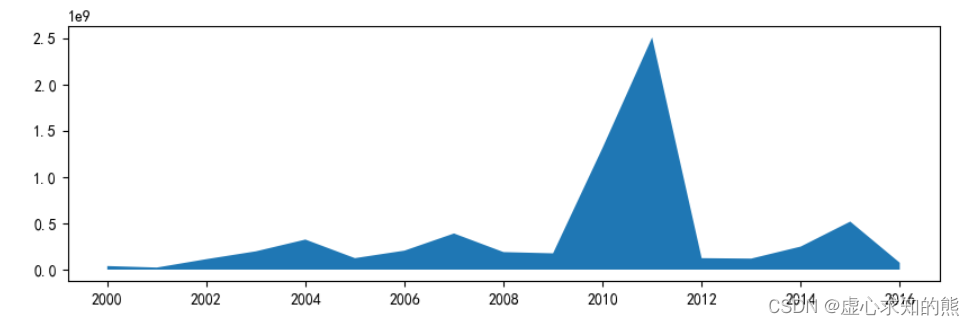
至此,我们的问题一就得到了解决,下面进行问题二的计算。 我们取出大于 2000 年的数据,并绘制面积图。 movie_year = data. groupby( '上映年份' ) [ [ '评分人数' ] ] . sum ( )
movie_year_2000 = movie_year. loc[ 2000 : ]
plt. stackplot( movie_year_2000. index, movie_year_2000[ '评分人数' ] )
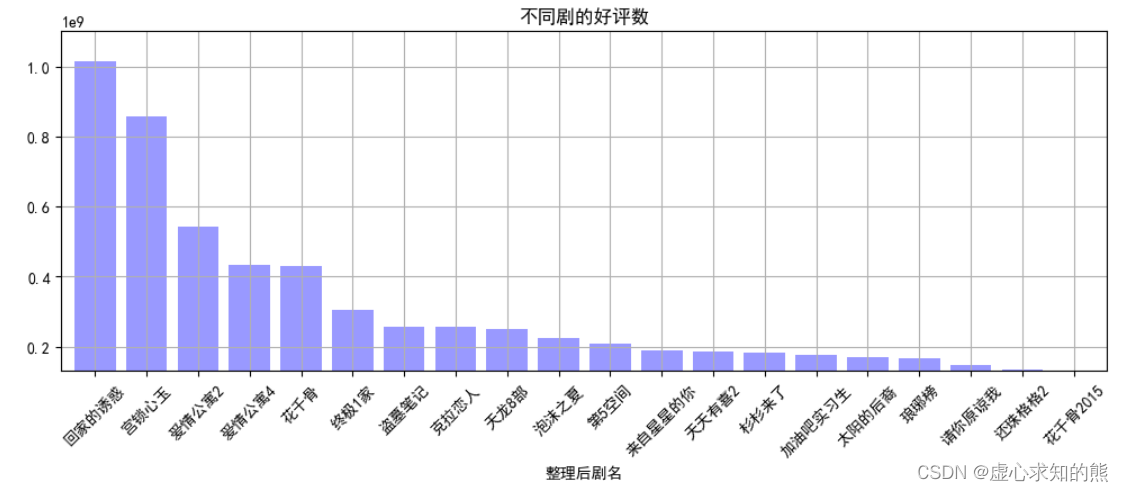
然后,我们求出不同剧的评分人数、好评数总和,好评数前 20 绘图。 movie_title_group = data. groupby( '整理后剧名' ) [ [ '评分人数' , '好评数' ] ] . sum ( )
result_title = movie_title_group. sort_values( '好评数' , ascending= False ) [ : 20 ]
result_title
result_title[ '好评数' ] . plot( kind= 'bar' ,
color = 'b' ,
width = 0.8 ,
alpha = 0.4 ,
rot = 45 ,
grid = True ,
ylim = [ 1.3e+08 , 1.1e+09 ] ,
figsize = ( 12 , 4 ) ,
title = '不同剧的好评数' )










![“速通“ 老生常谈的HashMap [实现原理源码解读]](https://img-blog.csdnimg.cn/198fd6850c4f490b8ecd0ee15cf11c24.gif)