1.问题描述
10月27号,用户反馈 g_feature 资源组的回溯任务在夜间的耗时比较大。在00:49——04:16期间,查询的平均耗时是大于100ms的。
2. 分析原因
根据问题现象,在夜间的耗时比较大,白天的耗时比较小,首先想到的就是 HBase Compact 的影响,为了验证这个想法,从下面几个方面进行了分析:
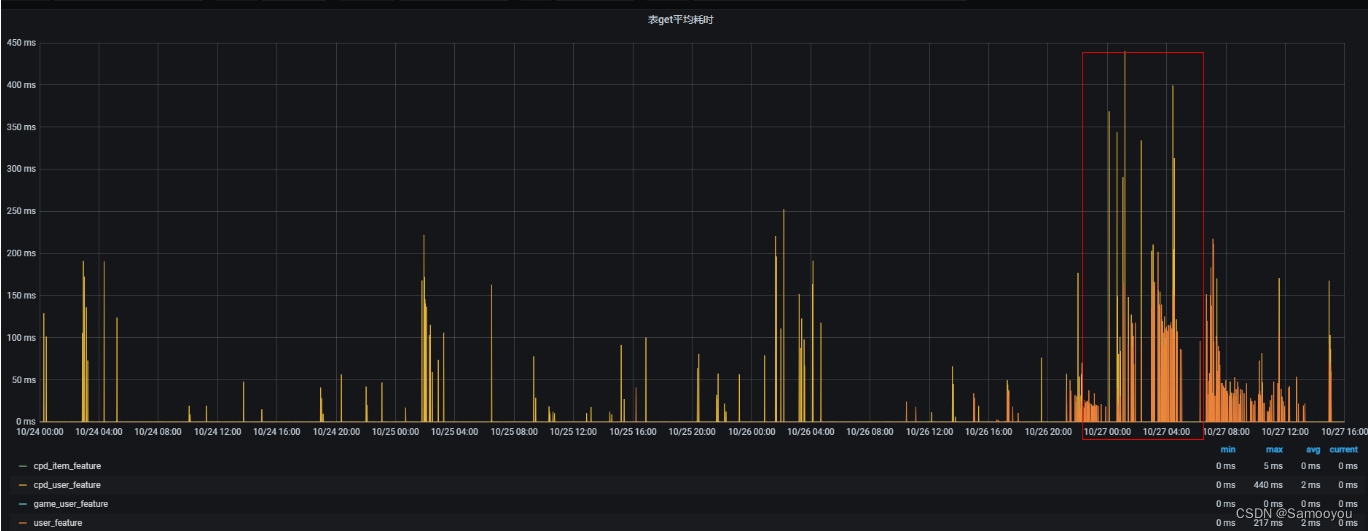
1)查看该表的耗时监控和资源组的 major compact 的监控,可以看到耗时长的时间正式 Major Compact 的高峰期。
 2)查看 RS 的日志,发现日志中有较多 WRN 级别的 IOException。
2)查看 RS 的日志,发现日志中有较多 WRN 级别的 IOException。
2022-11-03 01:43:21,042 WARN org.apache.hadoop.hdfs.DFSClient: Connection failure: Failed to connect to /xxxxx1:50010 for file /hbase/data/feature_warehouse/user_feature/2b094101104193db45905dacd78424c8/h/829db88b1d4b4eccb74d8f57566969d7 for block BP-1137402806-xxxx-1616663333574:blk_2417503147_1343767793:java.io.IOException: Got error for OP_READ_BLOCK, status=ERROR, self=/xxxx:44058, remote=/xxxx:50010, for file /hbase/data/feature_warehouse/user_feature/2b094101104193db45905dacd78424c8/h/829db88b1d4b4eccb74d8f57566969d7, for pool BP-1137402806-xxxx-1616663333574 block 2417503147_1343767793
java.io.IOException: Got error for OP_READ_BLOCK, status=ERROR, self=/xxxxx:44058, remote=/xxxx:50010, for file /hbase/data/feature_warehouse/user_feature/2b094101104193db45905dacd78424c8/h/829db88b1d4b4eccb74d8f57566969d7, for pool BP-1137402806-xxxxx-1616663333574 block 2417503147_1343767793
at org.apache.hadoop.hdfs.RemoteBlockReader2.checkSuccess(RemoteBlockReader2.java:467)
at org.apache.hadoop.hdfs.RemoteBlockReader2.newBlockReader(RemoteBlockReader2.java:432)
at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReader(BlockReaderFactory.java:890)
at org.apache.hadoop.hdfs.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:768)
at org.apache.hadoop.hdfs.BlockReaderFactory.build(BlockReaderFactory.java:377)
at org.apache.hadoop.hdfs.DFSInputStream.actualGetFromOneDataNode(DFSInputStream.java:1214)
at org.apache.hadoop.hdfs.DFSInputStream.fetchBlockByteRange(DFSInputStream.java:1154)
at org.apache.hadoop.hdfs.DFSInputStream.pread(DFSInputStream.java:1528)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:1487)
at org.apache.hadoop.fs.FSDataInputStream.read(FSDataInputStream.java:92)
at org.apache.hadoop.hbase.io.hfile.HFileBlock.positionalReadWithExtra(HFileBlock.java:757)
at org.apache.hadoop.hbase.io.hfile.HFileBlock$AbstractFSReader.readAtOffset(HFileBlock.java:1463)
at org.apache.hadoop.hbase.io.hfile.HFileBlock$FSReaderImpl.readBlockDataInternal(HFileBlock.java:1688)
at org.apache.hadoop.hbase.io.hfile.HFileBlock$FSReaderImpl.readBlockData(HFileBlock.java:1548)
at org.apache.hadoop.hbase.io.hfile.HFileReaderV2.readBlock(HFileReaderV2.java:446)
at org.apache.hadoop.hbase.util.CompoundBloomFilter.contains(CompoundBloomFilter.java:100)
at org.apache.hadoop.hbase.regionserver.StoreFile$Reader.passesGeneralBloomFilter(StoreFile.java:1381)
at org.apache.hadoop.hbase.regionserver.StoreFile$Reader.passesBloomFilter(StoreFile.java:1256)
at org.apache.hadoop.hbase.regionserver.StoreFileScanner.shouldUseScanner(StoreFileScanner.java:472)
at org.apache.hadoop.hbase.regionserver.StoreScanner.selectScannersFrom(StoreScanner.java:400)
at org.apache.hadoop.hbase.regionserver.StoreScanner.getScannersNoCompaction(StoreScanner.java:319)
at org.apache.hadoop.hbase.regionserver.StoreScanner.<init>(StoreScanner.java:193)
at org.apache.hadoop.hbase.regionserver.HStore.createScanner(HStore.java:2123)
at org.apache.hadoop.hbase.regionserver.HStore.getScanner(HStore.java:2113)
at org.apache.hadoop.hbase.regionserver.HRegion$RegionScannerImpl.<init>(HRegion.java:5682)
at org.apache.hadoop.hbase.regionserver.HRegion.instantiateRegionScanner(HRegion.java:2637)
at org.apache.hadoop.hbase.regionserver.HRegion.getScanner(HRegion.java:2623)
at org.apache.hadoop.hbase.regionserver.HRegion.getScanner(HRegion.java:2604)
at org.apache.hadoop.hbase.regionserver.HRegion.get(HRegion.java:6968)
at org.apache.hadoop.hbase.regionserver.HRegion.get(HRegion.java:6927)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.get(RSRpcServices.java:2027)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:33644)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2191)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:183)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:163)3)于是产生了疑问,这个 IOException 与 Compact 有没有关系?
为了排查这个问题,首先对这个读block的 IOException 进行了分析,详情可以参考 8.3 WARN org.apache.hadoop.hdfs.BlockReaderFactory: I/O error constructing remote block reader 问题定位
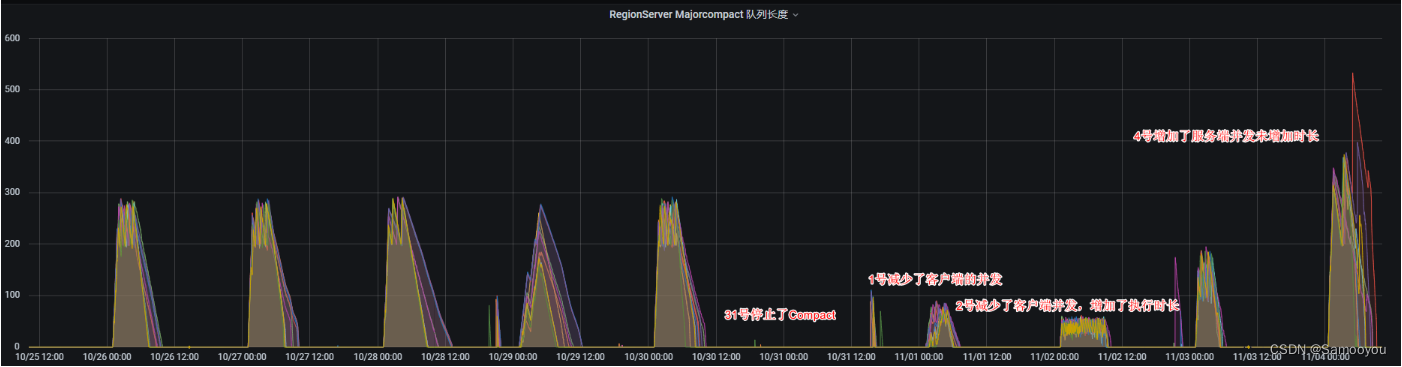
4)为了验证这个IOException 和 Major Compact 的关系,对比了停掉 Major Compact 和未停 Major Compact 的错误次数
2022-11-01是停掉了 Major Compact 的,可以看到这个 IOException 与 Major Compact 是相关的。但是这个 IOException 对读的影响有多大是未知的。

5)下面就开始对 Compact 进行优化,这优化包括2方面:Minor Compact(因为刘腾反馈过几次白天因为Minor Compact导致时延变大)、Major Compact。
3. 验证过程
1)与刘腾进行沟通后,首先从以下几个方面进行测试,Compact 相关的原理可以参考 HBase Compaction 原理与线上调优实践
- 停掉 Major Compact 任务
- 减少Major Compact 并发
- 减少Major Compact 并发但是延长 Major Compact 执行时长
| 序号 | 措施 | 日期 | 效果 | 备注 |
|---|---|---|---|---|
| 测试1 | 停掉 Major Compact 任务 | 11-31 | 业务耗时低 | 业务能接受 |
| 测试2 | 减少Major Compact 并发,从200减少到50 | 12-01 | 有个任务耗时大 | 业务能接受 |
| 测试3 | 减少Major Compact 并发到50,但是延长 Major Compact 执行时长 | 12-02 | 多个任务耗时大 | 业务不能接受 |
a)情况1的业务耗时正常,能接受
b)测试2的业务耗时,有1个任务耗时3个小时,其他都正常,总体耗时能接受;
c)测试3的业务耗时,耗时大的时长比较长,不能接受。
2)因为 Compact 的作用是合并文件并且删除过期数据,所以 Compact 是不能停的,与刘腾沟通后,业务能接受的方式是:将 Compact 集中在夜间的几个小时内做完,而这几个小时内的延迟可以大点。于是确定了下面的优化方式就是增加服务端 Compact 的并发,将 Compact 在尽可能端的时间内做完。
4. 优化措施
1)调整 hbase.hstore.compaction.max.size 参数大小为1G,将大于1G的文件不参加 Minor Compact(已完成)
2)调整 hbase.regionserver.thread.compaction.large 参数,从10提高到20,提高服务端的 Major Compact 并发线程数来减少Compact 执行时长。
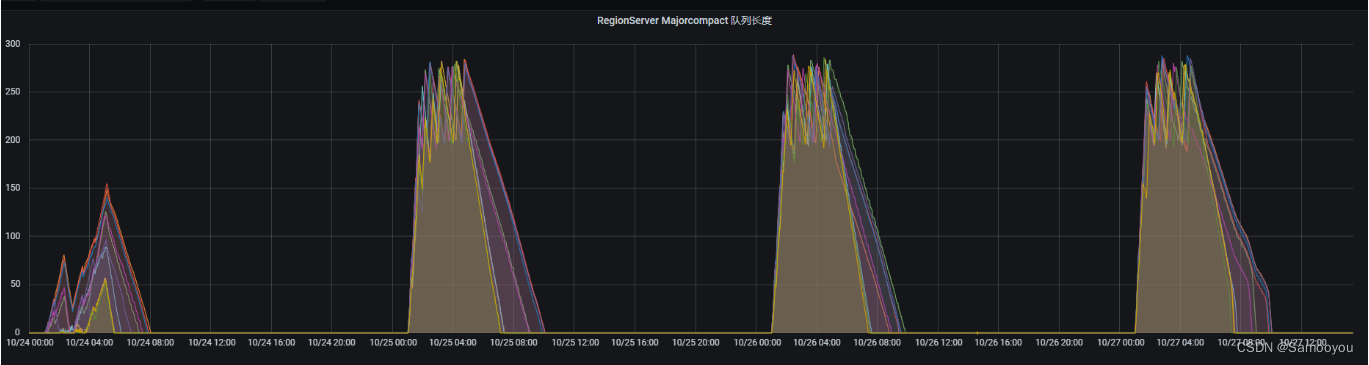
下面是之前调试的几种策略的 MajorCompact 队列图,可以看到停止 Compact 任务、 减少 Compact 并发、减少 Compact 并发但是增加执行时长这几种策略都有 Compact 执行不完的风险。增加服务端的 Compact 线程数可以明显加大 Compact 的执行力度。