知识要点
-
fetch_california_housing:加利福尼亚的房价数据,总计20640个样本,每个样本8个属性表示,以及房价作为target
-
超参数搜索的方式: 网格搜索, 随机搜索, 遗传算法搜索, 启发式搜索
-
函数式添加神经网络:
-
model.add(keras.layers.Dense(layer_size, activation = 'relu'))
-
model.compile(loss = 'mse', optimizer = optimizer) # optimizer = keras.optimizers.SGD (learning_rate)
-
sklearn_model = KerasRegressor(build_fn = build_model)
-
from tensorflow.keras.wrappers.scikit_learn import KerasRegressor # 回归神经网络
# 搜索最佳学习率
def build_model(hidden_layers = 1, layer_size = 30, learning_rate = 3e-3):
model = keras.models.Sequential()
model.add(keras.layers.Dense(layer_size, activation = 'relu', input_shape = x_train.shape[1:]))
for _ in range(hidden_layers - 1):
model.add(keras.layers.Dense(layer_size, activation = 'relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate)
model.compile(loss = 'mse', optimizer = optimizer)
# model.summary()
return model
sklearn_model = KerasRegressor(build_fn = build_model)-
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)] # 回调函数设置
-
gv = GridSearchCV(sklearn_model, param_grid = params, n_jobs = 1, cv= 5,verbose = 1) # 找最佳参数
-
gv.fit(x_train_scaled, y_train)
1 导包
from tensorflow import keras
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
cpu=tf.config.list_physical_devices("CPU")
tf.config.set_visible_devices(cpu)
print(tf.config.list_logical_devices())2 导入数据
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data,
housing.target,
random_state= 7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all,
random_state = 11)3 标准化处理数据
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler =StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)4 函数式定义模型
from tensorflow.keras.wrappers.scikit_learn import KerasRegressor # 回归神经网络
# 搜索最佳学习率
def build_model(hidden_layers = 1, layer_size = 30, learning_rate = 3e-3):
model = keras.models.Sequential()
model.add(keras.layers.Dense(layer_size, activation = 'relu', input_shape = x_train.shape[1:]))
for _ in range(hidden_layers - 1):
model.add(keras.layers.Dense(layer_size, activation = 'relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate)
model.compile(loss = 'mse', optimizer = optimizer)
# model.summary()
return model
sklearn_model = KerasRegressor(build_fn = build_model) 
5 模型训练
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]
history = sklearn_model.fit(x_train_scaled, y_train, epochs = 10,
validation_data = (x_valid_scaled, y_valid), callbacks = callbacks)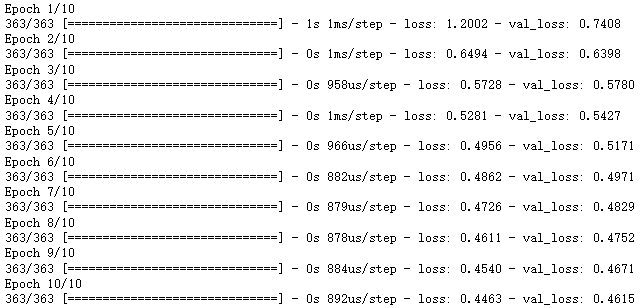
6 超参数搜索
超参数搜索的方式:
-
网格搜索
-
定义n维方格
-
每个方格对应一组超参数
-
一组一组参数尝试
-
-
随机搜索
-
遗传算法搜索
-
对自然界的模拟
-
A: 初始化候选参数集合 --> 训练---> 得到模型指标作为生存概率
-
B: 选择 --> 交叉--> 变异 --> 产生下一代集合
-
C: 重新到A, 循环.
-
-
启发式搜索
-
研究热点-- AutoML的一部分
-
使用循环神经网络来生成参数
-
使用强化学习来进行反馈, 使用模型来训练生成参数.
-
# 使用sklearn 的网格搜索, 或者随机搜索
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
params = {
'learning_rate' : [1e-4, 3e-4, 1e-3, 3e-3, 1e-2, 3e-2],
'hidden_layers': [2, 3, 4, 5],
'layer_size': [20, 60, 100]}
gv = GridSearchCV(sklearn_model, param_grid = params, n_jobs = 1, cv= 5,verbose = 1)
gv.fit(x_train_scaled, y_train)- 输出最佳参数
# 最佳得分
print(gv.best_score_) # -0.47164334654808043
# 最佳参数
print(gv.best_params_) # {'hidden_layers': 5,'layer_size': 100,'learning_rate':0.01}
# 最佳模型
print(gv.estimator)
'''<keras.wrappers.scikit_learn.KerasRegressor object at 0x0000025F5BB12220>'''
gv.score
7 最佳参数建模
model = keras.models.Sequential()
model.add(keras.layers.Dense(100, activation = 'relu', input_shape = x_train.shape[1:]))
for _ in range(4):
model.add(keras.layers.Dense(100, activation = 'relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(0.01)
model.compile(loss = 'mse', optimizer = optimizer)
model.summary()
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]
history = model.fit(x_train_scaled, y_train, epochs = 10,
validation_data = (x_valid_scaled, y_valid), callbacks = callbacks)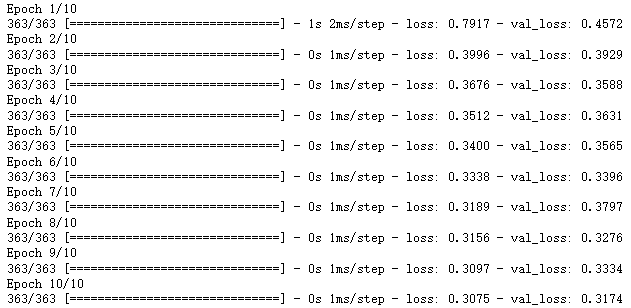
8 手动实现超参数搜索
- 根据参数进行多次模型的训练, 然后记录 loss
# 搜索最佳学习率
learning_rates = [1e-4, 3e-4, 1e-3, 3e-3, 1e-2, 3e-2]
histories = []
for lr in learning_rates:
model = keras.models.Sequential([
keras.layers.Dense(30, activation = 'relu', input_shape = x_train.shape[1:]),
keras.layers.Dense(1)
])
optimizer = keras.optimizers.SGD(lr)
model.compile(loss = 'mse', optimizer = optimizer, metrics = ['mse'])
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-2)]
history = model.fit(x_train_scaled, y_train,
validation_data = (x_valid_scaled, y_valid),
epochs = 100,
callbacks = callbacks)
histories.append(history) 
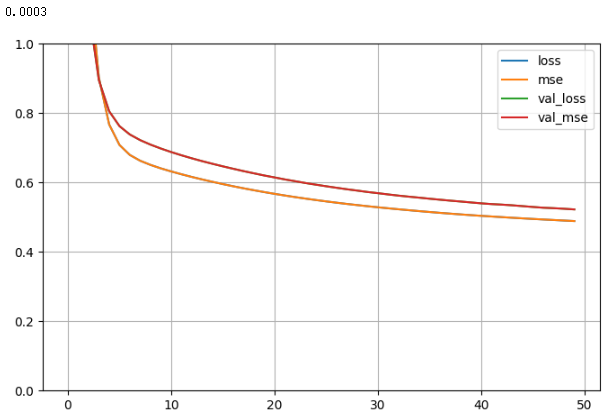
# 画图
import pandas as pd
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
for lr, history in zip(learning_rates, histories):
print(lr)
plot_learning_curves(history)