支持向量机(Support Vector Machine, SVM)不仅具有坚实的统计学理论基础,还可以很好地应用于高维数据、避免维度灾难问题,已经成为一种倍受关注的机器学习分类技术。
为了解释SVM的基本思想,我们首先介绍一下最大边缘超平面(Maximal Margin Hyperplane)

给定训练数据集,线性分类器最基本的想法是:在样本空间中寻找一个超平面,将不同类别的样本分开。
每个超平面B,都对应着一对平行的超平面:bi1,和bi2,
它们之间的间隔称为超平面的边缘(margin)
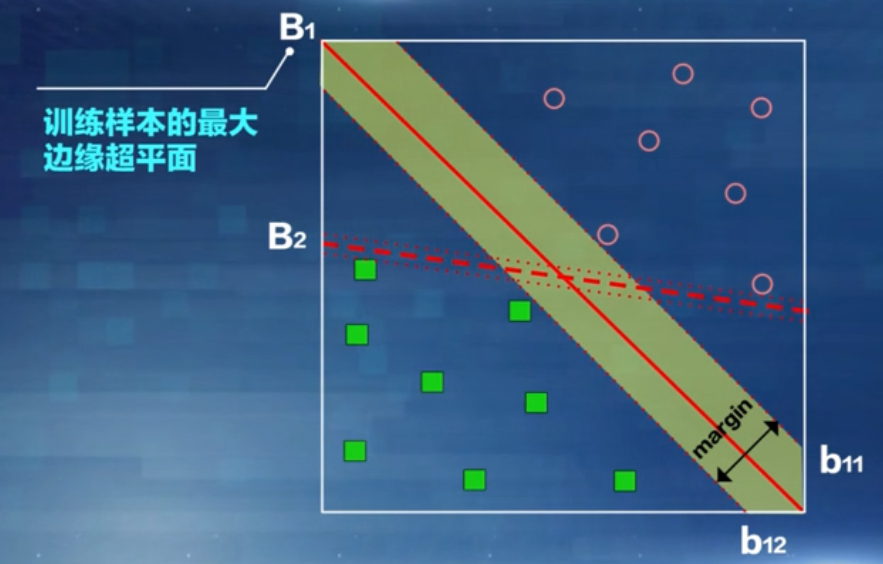
图中,超平面B的边缘明显大于B的边缘。因此,在这个例子中,B就是训练样本的最大边缘超平面。
直觉上,决策边界的边缘较小,决策边界任何轻微的扰动都可能对分类结果产生较大的影响。也就是说,具有较大边缘的决策边界比那些具有较小边缘的决策边界具有更好的泛化误差。
因此,根据结构风险最小化原理,需要设计最大化决策边界的边缘的线性分类器,以确保最坏情况下的泛化误差最小。线性支持向量机(linear SVM)就是这样的分类器。

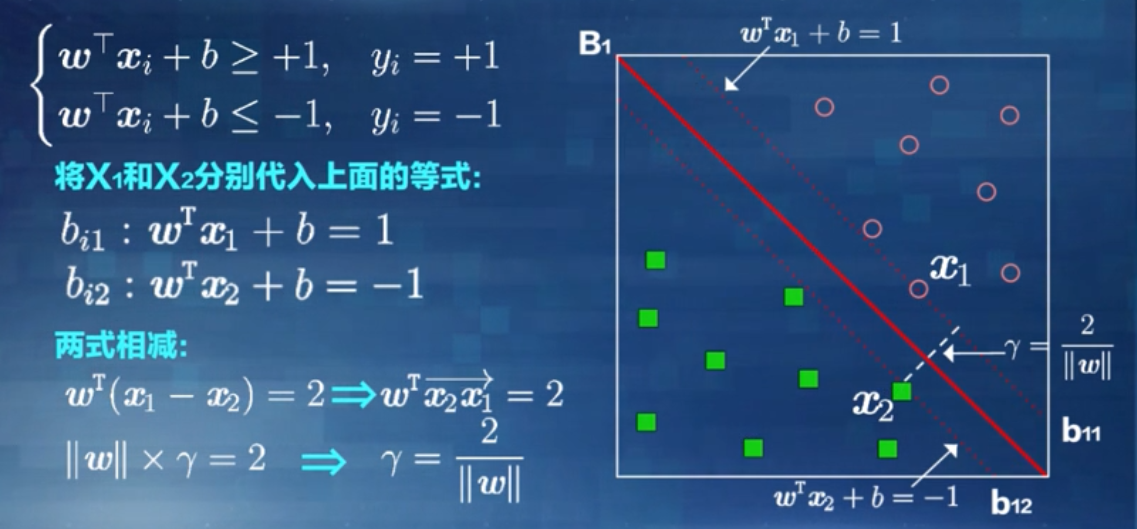
距离决策边界最近的训练样本点使得上式中的等号成立,因此被称为“支持向量”(support vector)。两个异类支持向量到决策边界的距离之和被称为决策边界的“边缘”(margin),刚好等于超平面bi1和bi2之间的间隔。


由于目标函数是二次的,并且约束条件在参数w和b上是线性的,因此线性支持向量机的学习问题是一个凸二次优化问题,可以直接用现成的优化计算包求解,或者用更高效的拉格朗日乘子法求解


KKT条件表明,除非训练样本满足9if(;) =1,否则必有拉格朗日乘子Q =0。那些a > 0的训练样本,
即 gJ;f (;)= 1的训练样本都落在最大边缘的边界6;和b;2上,都是支持向量。
可见,最终支持向量机模型的参数和b仅仅依赖于这些支持向量。

由于对偶优化问题是一个二次规划问题,可使用通用的二次规划算法来求解;
然而,该问题的规模正比于训练样本的数目,对于大型数据集,会造成很大的开销。为了避开这个障碍,人们通过利用问题本身的特性,提出了很多高效的算法,比如:SMO序列最小化优化算法
线性SVM假定训练样本是线性可分的,即存在一个线性的决策边界能将所有的训练样本正确分类。
然而在实际应用中,在原始的样本空问内也许并不存在这样的决策边界。
对于这样的问题,可将样本从原始空问映射到一个更高维的特征空间,使得样本在映射后的特征空间内线性可分。例如在下图中,如果将原始的二维空间映射到一个合适的三维空间,就能找到一个合适的划分超平面。幸运的是,如果原始空间是有限维,即属性数目有限,那么一定存在一个更高维的特征空间使得样本线性可分。
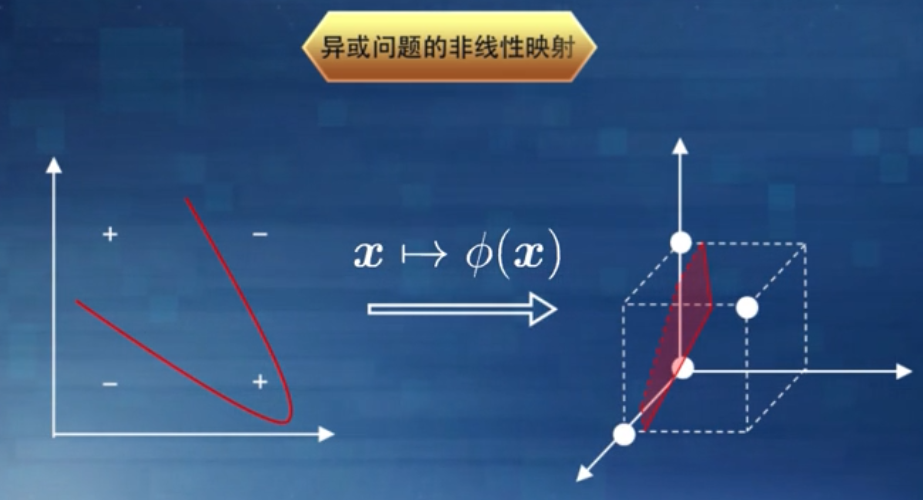

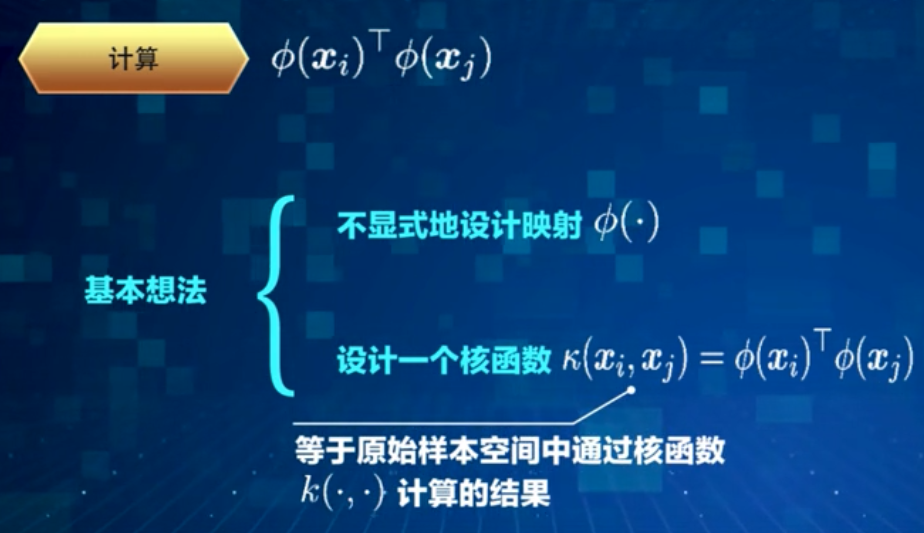
那么,合适的核函数是否一定存在呢?什么样的函数才能做核函数呢?
根据Mercer定理,只要一个对称函数所对应的核矩阵半正定,那么它就能作为核函数来使用。

于是,核函数的选择成为非线性SVM的最大变数,若核函数选择不合适,就意味着将样本映射到了一个不合适的特征空间,从而很可能导致非线性SVM性能不佳。