参考文章
numpy学习
numpy中的浅复制和深复制的详细用法
numpy中的np.where
torch.gather()
Numpy的核心数据结构,就叫做array就是数组,array对象可以是一维数组,也可以是多维数组
array本身的属性
shape:返回一个元组,表示array的维度x.shape
ndim:一个数字,表示array的维度的数目
size:一个数字,表示array中所有数据元素的数目
dtype:array中元素的数据类型
创建array
1.从Python的列表List和嵌套列表创建array,需要用到numpy的array方法
注意n维就有n个右中括号,比如2维,就是([[
>>> a=np.array([1,2])
>>> a
array([1, 2])
>>> b=np.array([[1,2],[2,3]])
>>> b
array([[1, 2],
[2, 3]])
2.使用预定函数arange、ones/ones_lik(全为1)e、zeros/zeros_like(全为0)、empty/empty_like(全为空)、full/full_like(指定数值)、eye(单位矩阵)等函数创建
3.生成随机数的np.random模块构建
>>> a=np.arange(2,10,2)
>>> a
array([2, 4, 6, 8])
>>> a=np.random.randn(2,2,2)
>>> a
array([[[ 0.652504 , 1.16510023],
[-0.75828046, 0.95137823]],
[[ 0.39619081, 0.54900311],
[ 0.94932242, -0.66919562]]])
numpy拷贝
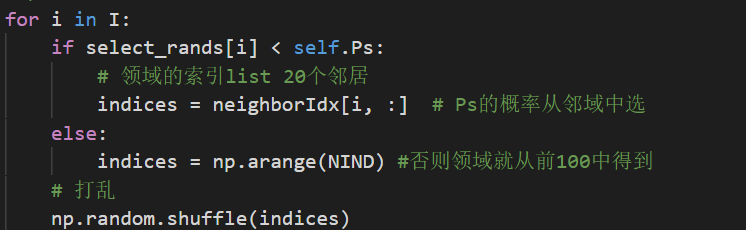
看这段的时候,在想neighborIdx应该是不会改变的,但是每次用pdb调试的时候,这个矩阵都会改变
其实是因为切片其实是浅拷贝,也就是视图。切片改变,原数组也会改变
也就是b is a,a[:]都是浅拷贝,对应的复制数组变,原数组也变
深拷贝a.copy(),两者互不影响
浅复制:主要有两种方式,简单的赋值或者使用视图(view)
简单的赋值:其实就是制造了一个别名,数组并没有被copy成新的一份,当使用其中一个别名改变数组值的时候,另一个别名对应的值一并改变。也就是b is a
>>>a = np.arange(12)
>>>a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>>b = a
>>>b is a
True
>>>b.shape = 3,4
>>>b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
视图:就是制造了一个原数组的在numpy中定义为view的东西,新视图的base是原数组,区别在于新视图可以和原数组有不同的shape,但当视图的值改变,原数组的值也会发生改变。需要注意的是数组的切片其实就是生成视图的过程。如c = a[:],其实就是生成了和a形状相同的a的view(完全切片)。也就是切片c = a[:]
>>>a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>c = a.view
>>>c is a
False
>>>c.base is a
True
>>>c.shape = 12
>>>c[0] = 520
>>>a
array([[520, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
深复制:就是制作一份原数组的copy了。
>>>d = a.copy()
>>>d[0][0] = 1314
>>>d
array([[1314, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
array索引
简单索引-切片索引
行列用都逗号分隔,:表示从哪到n-1的位置,步长
注意负数,‘-’表示最后,位置为负,表示从最后开始算第一个,步长为负表示从后面开始数
a[x:y:m,:]
>>> a
array([[-0.50549574, -0.68884199, -0.84651543, -1.31251463],
[-0.24952212, -0.01200736, 0.31297518, 0.90562104],
[-0.88056443, 0.71146101, 0.8669948 , 0.46530352],
[ 0.8001467 , 0.14129991, 0.29295588, -1.31864503]])
>>> a[1:3:1,:]
array([[-0.24952212, -0.01200736, 0.31297518, 0.90562104],
[-0.88056443, 0.71146101, 0.8669948 , 0.46530352]])
>>> a[-1:1:-1,:]
array([[ 0.8001467 , 0.14129991, 0.29295588, -1.31864503],
[-0.88056443, 0.71146101, 0.8669948 , 0.46530352]])
神奇索引(用整数数组进行的索引,叫神奇索引)数组里面套数组
这个我也是看了源码才知道,还有这种索引方式
一维数组
indexs = np.array([[0, 2], [1, 3]]) 两行两列对应四个位置索引
也就是a的第0个,第2个组成第1行,第1个,第3个组成第2个
>>> indexs = np.array([[0, 2], [1, 3]])
>>> a=np.arange(2,20,2)
>>> a
array([ 2, 4, 6, 8, 10, 12, 14, 16, 18])
>>> a[indexs]
array([[2, 6],
[4, 8]])
可以用到.argsort()方法:会返回从小到大排序后的索引index
这个方法也在论文源码中常常用到
# 随机生成1到100之间的,10个数字
>>> arr = np.random.randint(1,100,10)
>>> arr
array([56, 74, 87, 82, 26, 23, 15, 12, 84, 48])
>>> arr.argsort()
array([7, 6, 5, 4, 9, 0, 1, 3, 8, 2], dtype=int64)
>>> arr.argsort()[-3:]
array([3, 8, 2], dtype=int64)
>>> arr[arr.argsort()[-3:]]
array([82, 84, 87])
二维数组
注意a[[0,2]]和a[0,2]不同!!!!
注意筛选多列时,行不可省略
描述形式就是两个中括号,一个表示行,一个表示列
>>> a=np.arange(20).reshape(4,5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
>>> a[[0,2]]
array([[ 0, 1, 2, 3, 4],
[10, 11, 12, 13, 14]])
>>> a[0,2]
2
>>> a[:,[0,1,2]]
array([[ 0, 1, 2],
[ 5, 6, 7],
[10, 11, 12],
[15, 16, 17]])
>>> a[[0, 2, 3], [1, 3, 4]]
array([ 1, 13, 19])
布尔索引