概述
分类

数据源
任何位置。
如:集合、数组、文件、随机数、 Stream 静态工厂等。
支持的数据类型
- 整型、长整型、双精度浮点型基本数据类型。
- 引用数据类型。
流管道的数据处理流程
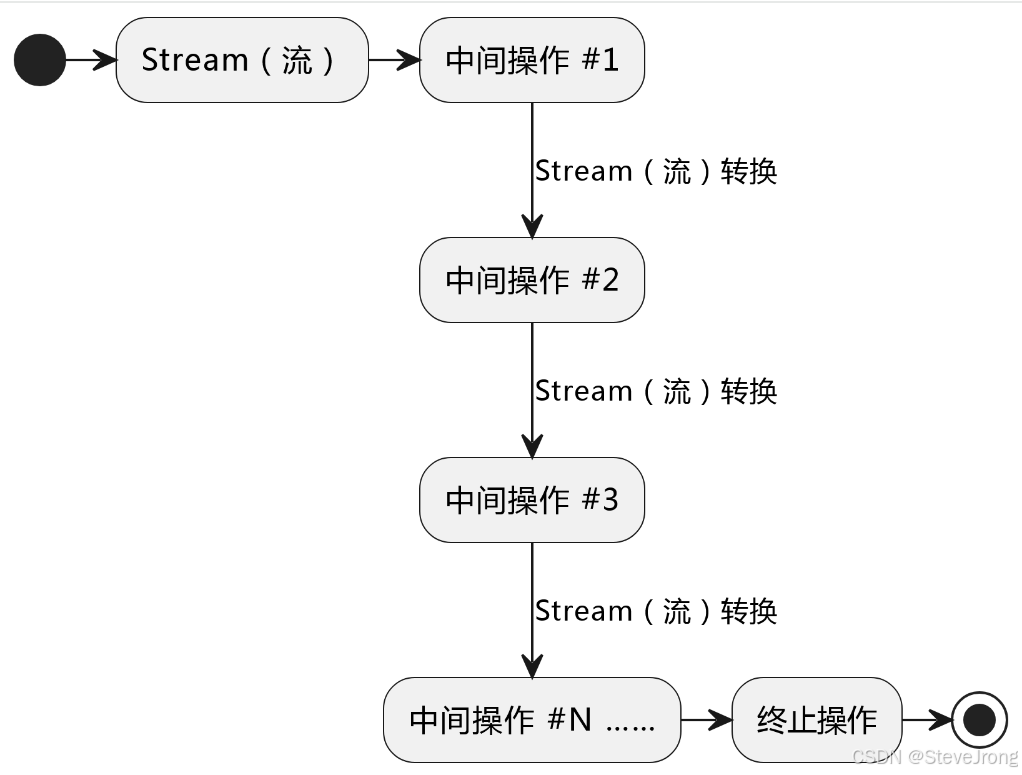
- 流管道必须要有终止操作。否则永不执行,只是一个静默的无操作指令。
- 流管道是懒运算的。当执行终止操作时,计算才真正去执行。
常用的函数式接口
均位于 java.util.function 包中。

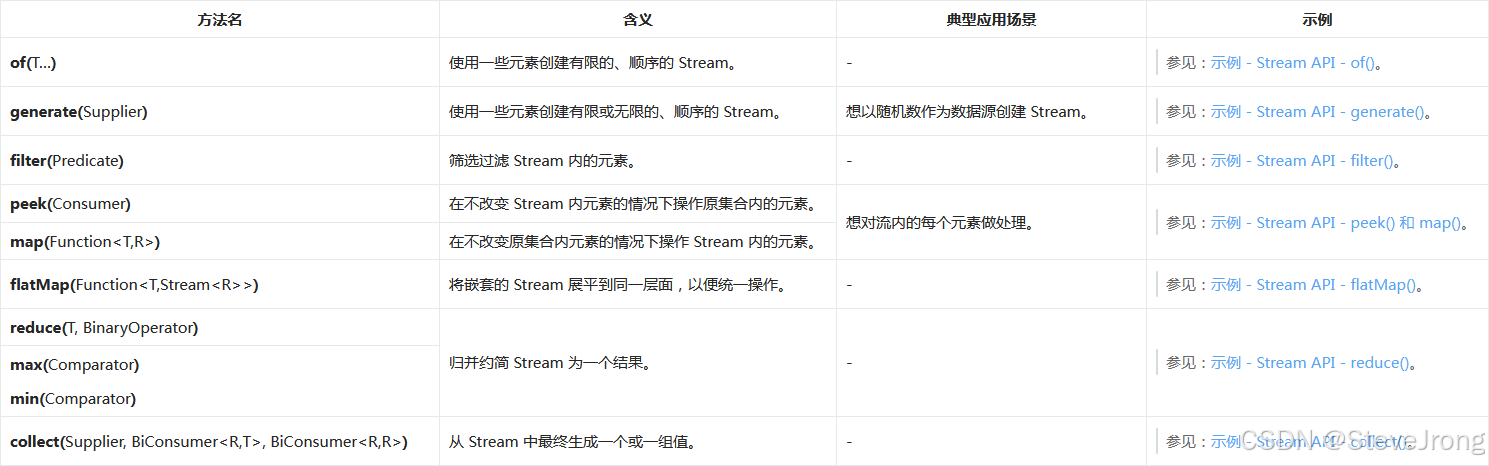
常用的 Stream API
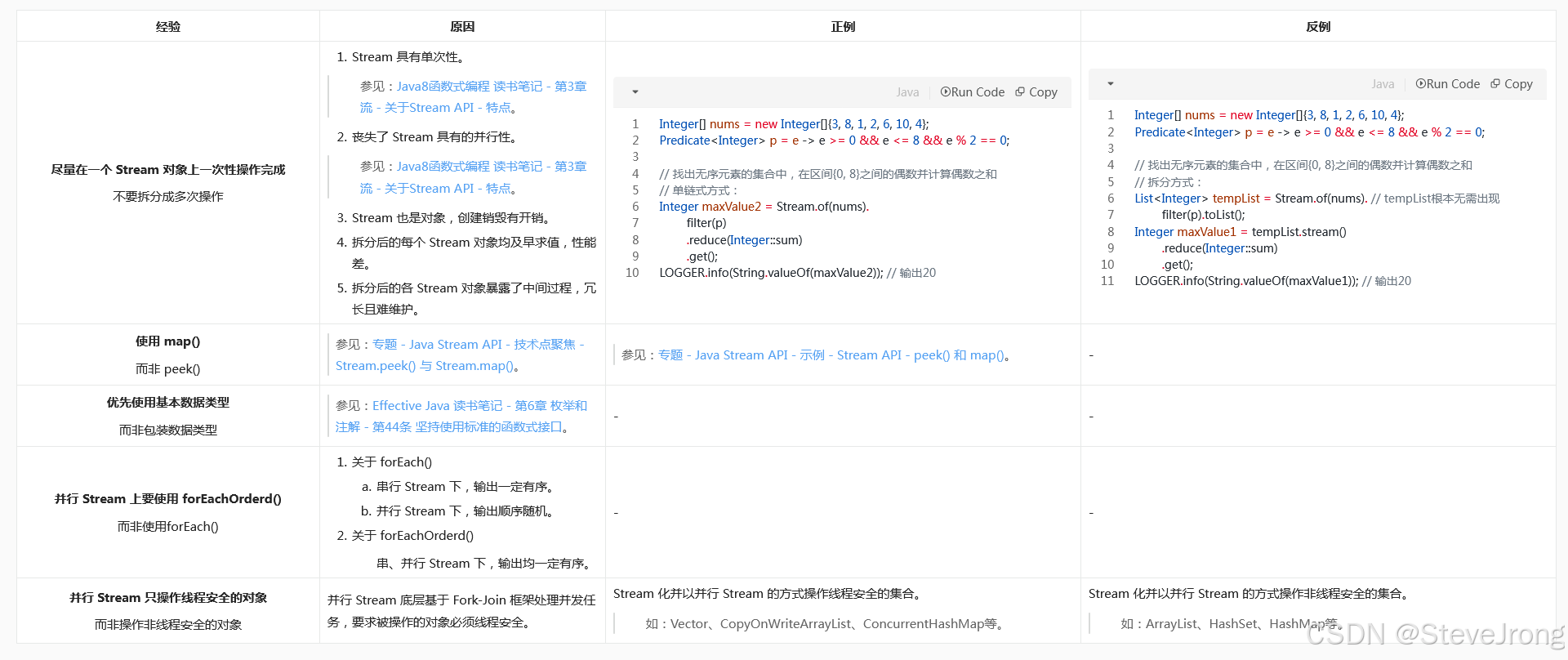
经验总结
技术点聚焦
Stream.peek() 与 Stream.map()

并行流
适用场景:
- 硬件方面:CPU核心数多。
- 流方面:
- 数据量大。
- 易于被Fork-Join框架分解。
- 其内的元素,尽量为基本数据类型。
- 其内的元素间,尽量避免有状态、有关联、有依赖。
- 操作方面:
-
处理每个元素的耗时长。
-
进行无状态操作。
如map()、filter()、flatMap()。
-
进行线程安全操作。
-
示例
函数式接口
Predicate
示例1:将判断逻辑,封装进Predicate对象内,并将其应用至集合的每个元素,来筛选出所需元素
// 初始化测试数据
Integer[] arrays = new Integer[]{
22, 108, 11, 33, 3, 7};
// 表示一个可应用于整型包装类型的断言/判断:当目标数值 >= 20时,将返回true,否则返回false。
Predicate<Integer> p1 = e -> e >= 20;
// 表示一个可应用于整型包装类型的断言/判断:当目标数值 <= 50时,将返回true,否则返回false。
Predicate<Integer> p2 = e -> e <= 50;
Stream.of(arrays) // 将元素载入Stream流中
.filter(p1.and(p2)) // filter()方法的定义:Stream<T> filter(Predicate<? super T> predicate);,表示返回一个由满足Predicate元素构成的流。
// 即filter()方法的入参要传入Predicate类型的。
// filter()方法的入参:p1.and(p2),表示将流中的每个元素套入此表达式中,注意判断是否同时满足两个Predicate。
// 如果某个元素同时满足两个Predicate,则将这个元素加入到新返回的Stream流中。
.forEach(e -> LOGGER.info(e));
22
33
示例2:将判断逻辑,封装进Predicate对象内,并将其应用至集合的每个元素,来筛选出所需元素
// 人类信息Bean
private static final class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
/* ********************** 以下是main()方法 ********************** */
// 初始化测试数据
Person[] persons = new Person[]{
new Person("张三", 22),
new Person("李四", 77),
new Person("王五", 13),
new Person("赵六", 36),
new Person("孙七", 81)
};
// 使用断言筛选高龄老人。当年龄 >= 80岁,则视为老人
// 表示一个可应用于Person类型的断言/判断:当Person对象中的属性age的值 >= 80时,将返回true,否则返回false。
Predicate<Person> agedPredicate = item -> item.age >= 80;
List<Person> agedList = Stream.of(persons) // 将元素载入Stream流中
.filter(item -> agedPredicate.test(item)) // 将流中的每个元素,逐一套入到agedPredicate断言中进行判断,返回true的元素才添加到待返回的流中
.collect(Collectors.toList());
// 输出老人信息
agedList.forEach(item -> LOGGER.info(item.name));
孙七
Consumer
示例1:将指定入参且无返回值的业务逻辑,封装进Consumer对象内,并指定对象来消费
// 初始化测试数据
int[] numbers = new int[]{
22, 108, 11, 33, 3, 7};
List<Integer> newNumbers = Lists.newArrayList();
// 为集合内的每个元素都+1,并放入一个新集合的消费者
// 这是一个无需返回值的复杂业务逻辑,将这个业务逻辑封装进了Consumer对象中
Consumer<Integer> addOneConsumer = (item) -> newNumbers.add(item + 1);
// 迭代原始数组,并调用Consumer接口的accept()方法,逐个执行addOneConsumer对象中的业务逻辑
for (Integer item : numbers) {
addOneConsumer.accept(item);
}
// 输出新集合
newNumbers.forEach(item -> LOGGER.info(item + ""));
23
109
12
34
4
8
示例2:将指定入参且无返回值的业务逻辑,封装进Consumer对象内,并做为函数参数来传递,实现指定对象的消费
/**
* 教师类
*/
class Teacher {
private final String teacherName; // 教师姓名
private final List<Student> students; // 班上学生
private final Consumer<Student> calculateScoreConsumer; // 打印输出学生成绩的消费者
public Teacher(String teacherName, List<Student> students, Consumer<Student> calculateScoreConsumer) {
this.teacherName = teacherName;
this.students = students;
this.calculateScoreConsumer = calculateScoreConsumer;
}
/**
* 打印输出学生成绩
*/
public void outputStudentScore() {
// 迭代这位教师下的所有学生,然后依次调用Consumer接口的accept()方法去消费学生
// Consumer接口的特点是给定入参,直接消费掉,没有出参。而此处正好只是做输出,所以也没必要有返回值,正好符合Consumer接口的使用场景。
for (Student s : students) {
calculateScoreConsumer.accept(s);
}
}

















![[实现Rpc] 客户端划分 | 框架设计 | common类的实现](https://i-blog.csdnimg.cn/img_convert/c009256cdc24c9f8b44b82516a99a487.jpeg)

