一、搜索用途
通常一个电商平台里面的商品,少则几十万多则上千万甚至上亿的sku,在这么多的商品中,如何让用户可以快速查找到自己想要的商品,那么就需要用到搜索功能来实现。
通过分析数据发现,接近40%的点击率是直接通过搜索来的。对于电商网站和平台来讲,一个好的搜索功能,能帮助用户精准快速的找到想买的商品,是提高转化率的重要因素。
二、搜索原理及常用算法
2.1搜索原理简介
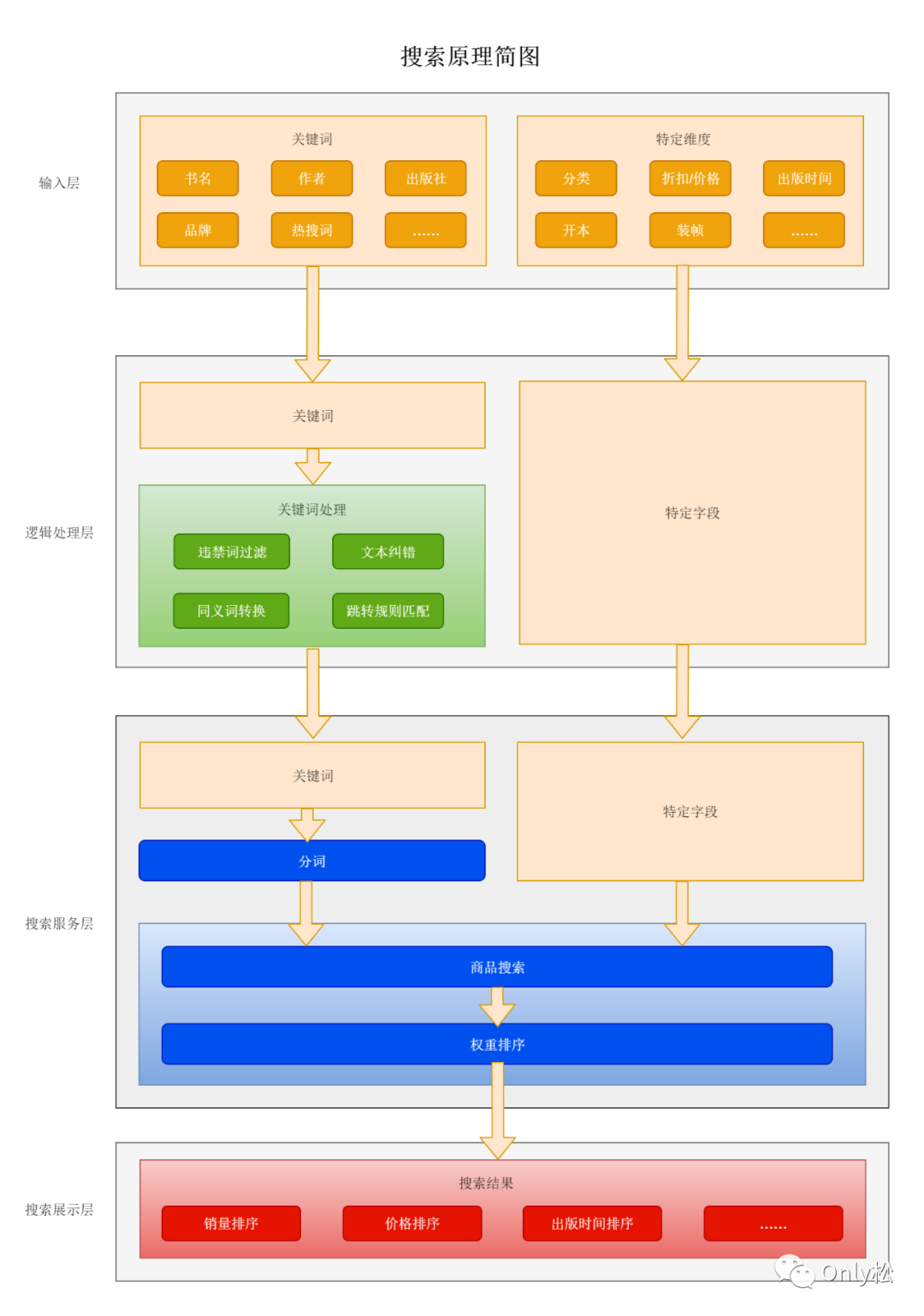
当用户输入关键词或者选择特定维度进行搜索时,系统一般会经过以下几个流程步骤进行处理:1.输入层→2.逻辑处理层→3.搜索服务层→4.搜索展示层,详情见下图:
2.2搜索常用算法简介
搜索技术的基石是NLP(Natural Language Processing):自然语言处理,基于NLP会衍生出各种的搜索算法。
本文将简单介绍下其中几种常见的算法,如果感兴趣可以自己知乎百度了解。
2.2.1贝叶斯学习
算法思想:如果一个事物在一些属性条件发生的情况下,事物属于A的概率>属于B的概率,则判定事物属于A。
适用场景:贝叶斯算法适用于商品打标分类、个性化推荐等场景。
2.2.2N-Gram分词(交叉切分算法)
算法思想:将文本内容按字节流进行大小为N的滑动窗口操作,形成长度为N的字符串,每个字符串称为gram,对全部gram的出现频度进行统计,并按照事先设定的阈值进行过滤,抛弃垃圾字符串得到新词。
适用场景:适用于新书和用户搜索词中的未登录词的识别。
2.2.3TF-IDF算法(重点词提取)
提取重点词的算法有很多种,比如TF-IDF算法,TextRank算法和CRF序列标注、主题模型算法(包括LSA,LSI,LDA等)。但是对短文本的提取,特别是字符小于10的文本提取关键词,行业上也没有比较好的解决办法,从目前的测试数据来看,TF-IDF算法比较好一些。
算法思想:简单的理解为一个词在文档中出现的次数越多,而在其它文档中出现的次数少,这个词就越重要。
适场场景:对于分词工具分词后有多个分词结果,提取其中重点关键词的场景。
三、搜索逻辑简介
3.1输入层
按照内部逻辑划分,电商系统中的查询方式通常有两种:关键词查询和特定维度查询。
3.1.1关键词查询
关键词查询是整个搜索功能最重要的入口,可以允许用户随意输入要查询的关键词,通常仅有一个查询关键字长度的限制。
关键词通常跟用户想买的商品有及其密切的关联,以图书网站为例,经过埋点数据分析发现,关键词通常有以下几类:书名、作者、出版社、品牌、热搜词等;
关键词通常可以直接在搜索框输入,有的网站也增加了图片识别、语音识别等高级搜索功能,但本质上还是通过关键词搜索。比如图片识别,就是通过OCR技术识别并提取图片上面的关键词后再进行搜索。
3.1.2特定维度查询
特定维度仅可查询由系统指定的部分可属性,如分类、价格/折扣、出版时间、开本、装帧等,并且用户无法输入查询值,仅能选择查询值。
由于这些数据在系统内部都维护有基础数据,并且保存在指定的字段中,所以对它们的查询相对比较简单。用户在选中对应选项时,可以获得唯一ID,之后根据ID查询相应字段获得结果,查询相对比较准确。
3.2逻辑处理层
当关键词输入之后,系统会对输入的关键词进行一系列的清洗处理,比如违禁词过滤、文本纠错、同义词转换、跳转规则匹配等。
3.2.1违禁词过滤
由于用户输入的搜索词系统是无法控制的,所以可能会存在违禁内容,为了符合国家法律规定,系统需要对用户输入的搜索词进行违禁词过滤后才能进行搜索。
违禁词通常分为极限词、敏感词和禁售类违禁词三大类。①极限词是指对商品有夸大存在且与实物描述不符表极限的词汇,比如最佳、第一、史无前例等。②敏感词是指国家领导人名称或黄、暴、不雅、带侮辱性、政治倾向等不适合公共场合展示的词汇。③禁售类违禁词是指不允许在网站或平台售卖商品的词汇,比如大麻、三唑仑等。
要屏蔽对应的违禁词,后台就需要维护一套违禁词词库,当用户输入的关键字在非法词库中就不再做搜索,这样可以减轻服务器压力。
每个电商网站或平台的违禁词都不相同,而且时常更新。当然网上一般有现成的词库,也可以可以直接导入系统,不满足的后台再人工进行维护扩充即可。
3.2.2文本纠错
当用户输入查询关键词时,可能会输入成拼音、或者错别字,比如用户本来想要输入"水浒传",实际却输入成“shuihuzhuan"或者"水许传",但是结果依然能返回和"水浒传"匹配的数据。这是因为系统逻辑中有一套文本纠错的程序在处理,当系统对比有错误时,会进行纠正处理。
同样后台也需要维护一套纠错词库,当用户输入的关键字如果在纠错词库中,则系统会自动将错误关键字替换为设置好的关键字,如:shuihuzhuan->水浒传;水许传->水浒传,之后查询实际采用的是转换后的关键字。
3.2.3同义词转换
当用户输入查询关键词时,也有可能输入了和关键词意思相近的词语,比如用户本来想要输入"三体",但实际却输入成"3体",这个时候系统就会将"3体"转换为"三体",再进行下一步处理。
实现的原理和文本纠错一样,在此便不再赘述。
3.2.4跳转规则匹配
有时我们在电商网站或平台上输入查询关键词后,会发现部分关键词结果不会跳转到结果列表页,而是跳转到一个商家店铺主页或者活动页,如输入关键词"4.23世界读书日",可能直接就进入到了读书节的活动页面。
要实现这个功能,后台同样需要维护一套跳转规则映射库。用户的搜索关键词与规则库中的关键词匹配时,则返回规则所指定的跳转路径,前端页面直接跳转过去,通常这个跳转规则是有时间限定的。
3.3搜索服务层
当用户输入的查询关键词通过违禁词过滤、文本纠错、同义词转换、特定跳转匹配后,依然没有匹配结果。这时系统会将关键字交给商品搜索服务器,搜索服务器首先会对关键字进行分词处理,然后再根据分词进行商品查询,并根据权重规则获得商品权重值,之后再进行权重值排序,最后返回查询结果。
3.3.1分词
分词是指将一个比较长的关键字拆分成多个合理的比较短的关键字的过程。
由于中文不像英文有天然的分隔符,因此需要有专门的分词工具来处理。比如‘人人都是产品经理’这个搜索词,经过分词后可以将其拆分为‘人人、都是、产品经理’。
分词看起来很简单,但是如何将关键词拆分为好的分词并非易事,分词结果的质量好坏直接影响着搜索质量。比如‘人人都是产品经理’这个搜索词,经过不同的分词工具分词后可以有不同的结果,比如:
‘人人、都是、产品经理’
‘人、人、都是、产品、经理’
经过实际的搜索结果来看,第一种分词得到的搜素结果要比第二种好很多。
目前图书行业常用的分词工具有百度分词、jieba(结巴分词)、HanLP(汉语言处理包)、NLPIR(汉语分词系统)等;
通常正常情况下,分词工具都能对关键词正确,但是也会出现一些分词异常情况。比如单字搜索词,当用户输入‘飘’,则会分词失败,这个时候人工将其加入分词库。另外还有一些新品,也会出现分词失败的情况,类似场景较多,在此便不再展开来讲。
3.3.2权重排序
权重是衡量某一指标的重要程度,在电商平台里都是各家的商业机密,网上公开的资料也是少之又少。
一个商品的权重高低,直接决定着商品排序情况,权重越高则商品排名越靠前,也就意味着商品有更多的曝光率,直接影响着销售。
以图书商品为例,常用的权重计算维度有销量、图片、套装类型等,当然也可以手动调整指定商品的权重。
权重的计算方法有很多中,如加权计算法、加权平均数法、AHP层次法、优序图法等等。
3.4搜索展示层
商品经过分词搜索,再经过权重模型计算排序后,就会展示在前端给客户查看,但是系统查询的结果不一定就百分百是用户想要的,所以用户可以自己根据一定的规则再次进行筛选新排序,最终找到自己的想要搜索结果。
常见的排序规则有销量排序、价格排序、销售类型、出版时间排序等。
四、搜索指标
商品从搜索到最终付款,中间主要有以下几个流程:

其中搜索结果质量的好坏,决定用户是否点击,而评估搜索质量主要有两个指标:召回率和查准率。
4.1召回率
召回率(Recall Rate,也叫查全率)是指搜索出的商品总数与系统中所有和搜索词相关商品总数的比率。
4.2查准率
查准率是指搜索出的商品中和搜索词有关系的商品总数与总召回数的比率。
召回率与查准率二者之间没有必然关联,但是又是相互制约的。召回率不是越高越,比如当召回率越高时,查准率可能越低。所以我们通产将这两个度量值融合成一个度量值,如F度量(F-measure)来进行综合评估。
来源:https://mp.weixin.qq.com/s/p_p8DeouvBLM7ako_1OBHA