目录
一、简介和环境准备
二、算法简介
2.1四种方法类:
2.1.1FKNN
2.1.2FKNCN
2.1.3BM-FKNN
2.1.3BM-FKNCN
2.2数据预处理
2.3输出视图
2.4调用各种方法看准确率
2.4.1BM-FKNCN
2.4.2BM-FKNN
2.4.3FKNCN
2.4.4FKNN
2.4.5KNN
一、简介和环境准备
knn一般指邻近算法。 K最近邻算法是一种常见的监督式学习算法,用于分类和回归问题。在K最近邻算法中,给定一个新的数据点,算法会找到训练数据集中离这个数据点最近的K个数据点,然后使用这K个数据点的标签或属性来预测新数据点的标签或属性。
主角是一种基于局部Bonferroni均值的模糊K-最近质心近邻(BM-FKNCN)分类器。下文会详细介绍BM-FKNCN。
本次实验环境需要用的是Google Colab和Google Drive(云盘),文件后缀是.ipynb可以直接用。首先登录谷歌云盘(网页),再打卡ipynb文件就可以跳转到谷歌colab了。再按以下点击顺序将colab和云盘链接。
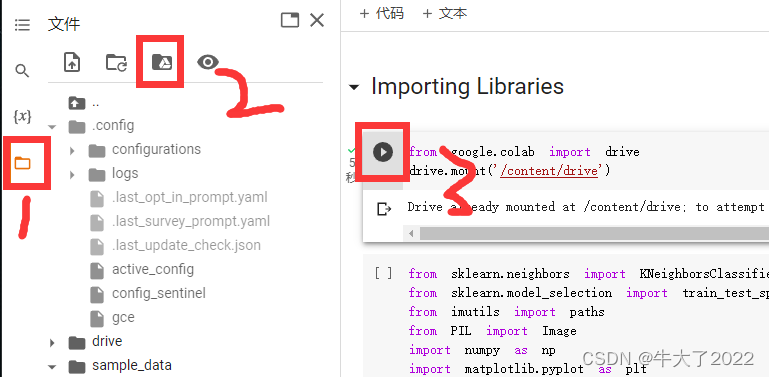
输入依赖
from google.colab import drive
import pandas as pd
import numpy as np
import scipy.spatial
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import KFold
from sklearn.metrics import confusion_matrix
from sklearn.metrics import plot_confusion_matrix
import matplotlib.pyplot as plt
drive.mount('/content/drive')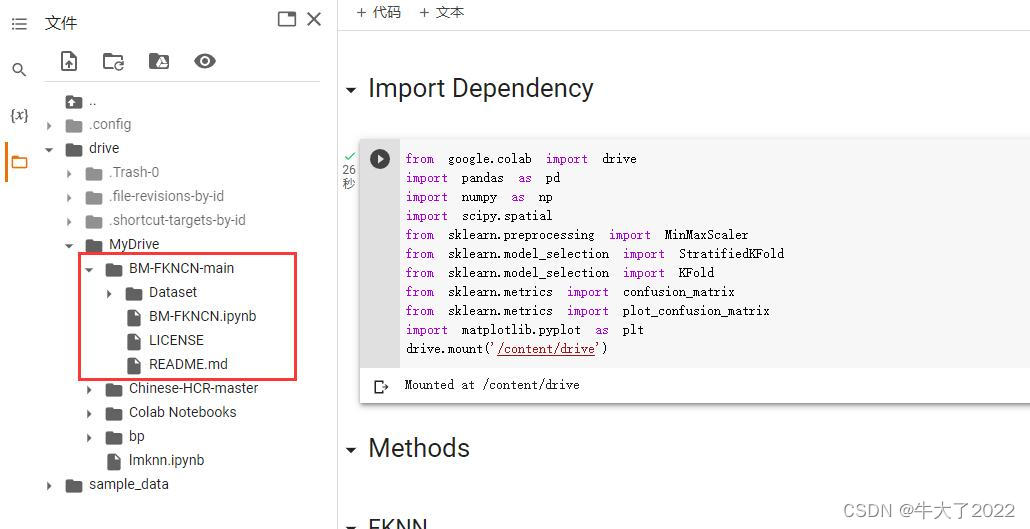
二、算法简介
2.1四种方法类:
FKNN、FKNCN、BM_FKNN和BM_FKNCN(之后再调用,不用先运行)
2.1.1FKNN
FKNN是指Fuzzy K-Nearest Neighbor(模糊K最近邻)算法。它使用模糊逻辑来考虑数据点之间的相似性。在FKNN中,每个数据点都被赋予一个隶属度(membership degree),该隶属度表示数据点属于每个类别的可能性程度。与传统的K最近邻算法不同,FKNN不仅考虑最近的K个数据点,还考虑了与目标数据点在一定距离范围内的所有数据点。FKNN的主要优点是能够处理数据集中的噪声和模糊性,并且对于不平衡的数据集也表现良好。
#Methods
##FKNN
import scipy.spatial
from collections import Counter
from operator import itemgetter
class FKNN:
def __init__(self, k):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def getDistance(self, X1, X2):
return scipy.spatial.distance.euclidean(X1, X2)
def fuzzy(self, d, m):
closestPoint = [ d[k][1] for k in range(len(d))]
classes = np.unique(self.y_train[closestPoint])
arrMembership = []
for cls in classes:
atas = 0
bawah = 0
for close in d:
if(close[0] != 0):
if(cls == self.y_train[close[1]]):
atas += np.power((1/close[0]), (2/(m-1)))
else:
atas += np.power((0/close[0]), (2/(m-1)))
bawah += np.power((1/close[0]), (2/(m-1)))
else:
atas += 0
bawah += 1
arrMembership.append([atas/bawah, cls])
return arrMembership
def predict(self, X_test):
final_output = []
for i in range(len(X_test)):
d = []
votes = []
for j in range(len(X_train)):
dist = self.getDistance(X_train[j] , X_test[i])
d.append([dist, j])
d.sort()
d = d[0:self.k]
membership = self.fuzzy(d, 2)
predicted_class = sorted(membership, key=itemgetter(0), reverse=True)
final_output.append(predicted_class[0][1])
return final_output
def score(self, X_test, y_test):
predictions = self.predict(X_test)
value = 0
for i in range(len(y_test)):
if(predictions[i] == y_test[i]):
value += 1
return value / len(y_test)
2.1.2FKNCN
模糊K-最近质心近邻(FKNCN)分类器是一种基于邻近性的模糊分类算法,是模糊K-最近邻(FKNN)算法的一种变体。与FKNN类似,FKNCN算法也使用模糊理论中的隶属度来度量样本之间的相似度。但是,与FKNN不同的是,FKNCN算法不仅考虑最近邻居的距离,还考虑了它们的质心。具体来说,对于每个测试样本,FKNCN算法首先使用K-最近邻算法来找到其K个最近的邻居。然后,对于每个类别,FKNCN算法计算其K个最近邻居的质心,并将测试样本与每个质心之间的距离作为该类别的隶属度。最后,FKNCN算法通过计算每个类别的隶属度之和,来确定测试样本所属的类别。
与FKNN相比,FKNCN具有以下优点:
-
对异常值和噪声更加鲁棒:FKNCN算法不仅考虑到每个邻居的距离,还考虑到它们的质心,因此对异常值和噪声更加鲁棒。
-
对于类别不平衡的数据集有更好的性能:FKNCN算法可以根据每个类别的质心来调整类别之间的权重,因此可以处理类别不平衡的数据集。
-
算法相对简单:FKNCN算法比一些更复杂的算法(如支持向量机)具有更简单的实现和计算。
##FKNCN
import scipy.spatial
from collections import Counter
from operator import itemgetter
class FKNCN:
def __init__(self, k):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def getDistance(self, X1, X2):
return scipy.spatial.distance.euclidean(X1, X2)
def getFirstDistance(self, X_train, X_test):
distance = []
for i in range(len(X_train)):
dist = scipy.spatial.distance.euclidean(X_train[i] , X_test)
distance.append([i, dist, self.y_train[i]])
return distance
def getCentroid(self, arrData):
result=[]
dataTran = np.array(arrData).T
for i in range(len(dataTran)):
result.append(np.mean(dataTran[i]))
return result
def kncn(self, X_test):
myclass = list(set(self.y_train))
closestPoint = []
anothersPoint = []
for indexK in range(0, self.k):
if(indexK == 0):
distance = self.getFirstDistance(self.X_train, X_test)
distance_sorted = sorted(distance, key=itemgetter(1))
closestPoint.append(distance_sorted[0])
distance_sorted.pop(0)
for anothers in (distance_sorted):
anothersPoint.append(anothers[0])
else:
arrDistance = []
closestPointTemp = [self.X_train[r[0]] for r in closestPoint]
for r in (anothersPoint):
arrQ = closestPointTemp.copy()
arrQ.append(self.X_train[r])
arrDistance.append([r, self.getDistance(self.getCentroid(arrQ), X_test)])
distance_sorted = sorted(arrDistance, key=itemgetter(1))
closestPoint.append(distance_sorted[0])
# anothersPoint = np.setdiff1d(anothersPoint, closestPoint)
return closestPoint
def fuzzy(self, d, m):
closestPoint = [ d[k][1] for k in range(len(d))]
classes = np.unique(self.y_train[closestPoint])
arrMembership = []
for cls in classes:
atas = 0
bawah = 0
for close in d:
if(close[0] != 0):
if(cls == self.y_train[close[1]]):
atas += np.power((1/close[0]), (2/(m-1)))
else:
atas += np.power((0/close[0]), (2/(m-1)))
bawah += np.power((1/close[0]), (2/(m-1)))
else:
atas += 0
bawah += 1
arrMembership.append([atas/bawah, cls])
return arrMembership
def predict(self, X_test):
final_output = []
for i in range(len(X_test)):
closestPoint = self.kncn(X_test[i])
d = []
votes = []
for j in range(len(X_train)):
dist = self.getDistance(X_train[j] , X_test[i])
d.append([dist, j])
d.sort()
d = d[0:self.k]
membership = self.fuzzy(d, 2)
predicted_class = sorted(membership, key=itemgetter(0), reverse=True)
final_output.append(predicted_class[0][1])
return final_output
def score(self, X_test, y_test):
predictions = self.predict(X_test)
value = 0
for i in range(len(y_test)):
if(predictions[i] == y_test[i]):
value += 1
return value / len(y_test)
2.1.3BM-FKNN
BM-FKNN是指一种基于贝叶斯模型的模糊K最近邻分类算法(Bayesian Model-based Fuzzy K-Nearest Neighbor)。BM-FKNN是对传统FKNN算法的改进,它通过引入贝叶斯模型来提高分类性能。具体地说,BM-FKNN使用贝叶斯分类器来计算每个类别的后验概率,并将其作为FKNN的权重,进而确定新数据点所属的类别。
BM-FKNN的主要优点是能够处理分类问题中的不确定性和噪声,同时具有高效性和灵活性。与传统的K最近邻算法相比,BM-FKNN能够更好地处理高维和大规模的数据集,并且对于不平衡的数据集也表现良好。BM-FKNN在模式识别、图像处理、生物信息学和金融等领域有广泛的应用。
##BM-FKNN
import scipy.spatial
from collections import Counter
from operator import itemgetter
class BM_FKNN:
def __init__(self, k):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def getDistance(self, X1, X2):
return scipy.spatial.distance.euclidean(X1, X2)
def getFirstDistance(self, X_train, X_test):
distance = []
for i in range(len(X_train)):
dist = scipy.spatial.distance.euclidean(X_train[i] , X_test)
distance.append([i, dist, self.y_train[i]])
return distance
def nearestPoint(self, X_test):
allPoint = [ i for i in range(len(X_test))]
distance = self.getFirstDistance(self.X_train, X_test)
distance_sorted = sorted(distance, key=itemgetter(1))
closest = distance_sorted[0:self.k]
closestPoint = [ i[0] for i in closest]
anothersPoint = np.setdiff1d(allPoint, closestPoint)
return closestPoint, anothersPoint
def bonferroniMean(self, c, closestPoint, p, q):
arrInner = [self.X_train[e] for e in closestPoint if(self.y_train[e] != c)] # j bukan angggota i
arrOuter = [self.X_train[q] for q in closestPoint if(self.y_train[q] == c)]
n = len(closestPoint)
if(n > 1):
inner = [(sum(np.power(x, q)))/n for x in zip(*arrInner)]
outer = [(sum(np.power(x, p)))/(n-1) for x in zip(*arrOuter)]
else:
inner = arrInner[0].copy()
outer = arrOuter[0].copy()
Br = [ np.power((inner[i]*outer[i]), (1/(p+q)) ) for i in range(len(inner))]
return Br
def fuzzy(self, arrBr, closestPoint, m):
arrMembership = []
for localMean in arrBr:
atas = 0
bawah = 0
for r in (closestPoint):
if(localMean[1] == self.y_train[r]):
atas += np.power((1/localMean[0]), (2/(m-1)))
else:
atas += np.power((0/localMean[0]), (2/(m-1)))
bawah += np.power((1/localMean[0]), (2/(m-1)))
arrMembership.append([atas/bawah, localMean[1]])
return arrMembership
def predict(self, X_test, p, q, m):
final_output = []
for i in range(len(X_test)):
localMean = []
closestPoint, anothersPoint = self.nearestPoint(X_test[i])
classes = np.unique(self.y_train[closestPoint])
if(len(classes) == 1):
final_output.append(classes[0])
else:
arrBr = []
for j in classes:
Br = self.bonferroniMean(j, closestPoint, p, q)
distBr = self.getDistance(X_test[i], Br)
arrBr.append([distBr, j])
membership = self.fuzzy(arrBr, closestPoint, m )
predicted_class = sorted(membership, key=itemgetter(0), reverse=True)
final_output.append(predicted_class[0][1])
return final_output
def score(self, X_test, y_test, p, q, m):
predictions = self.predict(X_test, p, q, m)
value = 0
for i in range(len(y_test)):
if(predictions[i] == y_test[i]):
value += 1
# print(value)
return value / len(y_test)
2.1.3BM-FKNCN
一种基于局部Bonferroni均值的模糊K-最近质心近邻(BM-FKNCN)分类器,该分类器根据最近的局部质心均值向量分配查询样本的类标签,以更好地表示数据集的基础统计。由于最近中心邻域(NCN)概念还考虑了邻居的空间分布和对称位置,因此所提出的分类器对异常值具有鲁棒性。此外,所提出的分类器可以克服具有类不平衡的数据集中邻居的类支配,因为它平均每个类的所有质心向量,以充分解释类的分布。
##BM-FKNCN
import scipy.spatial
from collections import Counter
from operator import itemgetter
class BM_FKNCN:
def __init__(self, k):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def getDistance(self, X1, X2):
return scipy.spatial.distance.euclidean(X1, X2)
def getFirstDistance(self, X_train, X_test):
distance = []
for i in range(len(X_train)):
dist = scipy.spatial.distance.euclidean(X_train[i] , X_test)
distance.append([i, dist, self.y_train[i]])
return distance
def getCentroid(self, arrData):
result=[]
dataTran = np.array(arrData).T
for i in range(len(dataTran)):
result.append(np.mean(dataTran[i]))
return result
def kncn(self, X_test):
myclass = list(set(self.y_train))
closestPoint = []
anothersPoint = []
for indexK in range(0, self.k):
if(indexK == 0):
distance = self.getFirstDistance(self.X_train, X_test)
distance_sorted = sorted(distance, key=itemgetter(1))
closestPoint.append(distance_sorted[0][0])
distance_sorted.pop(0)
for anothers in (distance_sorted):
anothersPoint.append(anothers[0])
else:
arrDistance = []
closestPointTemp = [self.X_train[r] for r in closestPoint]
for r in (anothersPoint):
arrQ = closestPointTemp.copy()
arrQ.append(self.X_train[r])
arrDistance.append([r, self.getDistance(self.getCentroid(arrQ), X_test)])
distance_sorted = sorted(arrDistance, key=itemgetter(1))
closestPoint.append(distance_sorted[0][0])
anothersPoint = np.setdiff1d(anothersPoint, closestPoint)
return closestPoint, anothersPoint
def bonferroniMean(self, c, closestPoint, p, q):
arrInner = [self.X_train[e] for e in closestPoint if(self.y_train[e] != c)] # j bukan angggota i
arrOuter = [self.X_train[q] for q in closestPoint if(self.y_train[q] == c)]
n = len(closestPoint)
if(n > 1):
inner = [(sum(np.power(x, q)))/n for x in zip(*arrInner)]
outer = [(sum(np.power(x, p)))/(n-1) for x in zip(*arrOuter)]
else:
inner = arrInner[0].copy()
outer = arrOuter[0].copy()
Br = [ np.power((inner[i]*outer[i]), (1/(p+q)) ) for i in range(len(inner))]
return Br
def fuzzy(self, arrBr, closestPoint, m):
arrMembership = []
for localMean in arrBr:
atas = 0
bawah = 0
for r in (closestPoint):
if(localMean[1] == self.y_train[r]):
atas += np.power((1/localMean[0]), (2/(m-1)))
else:
atas += np.power((0/localMean[0]), (2/(m-1)))
bawah += np.power((1/localMean[0]), (2/(m-1)))
arrMembership.append([atas/bawah, localMean[1]])
return arrMembership
def predict(self, X_test, p, q, m):
final_output = []
for i in range(len(X_test)):
localMean = []
closestPoint, anothersPoint = self.kncn(X_test[i])
classes = np.unique(self.y_train[closestPoint])
if(len(classes) == 1):
final_output.append(classes[0])
else:
arrBr = []
for j in classes:
Br = self.bonferroniMean(j, closestPoint, p, q)
distBr = self.getDistance(X_test[i], Br)
arrBr.append([distBr, j])
membership = self.fuzzy(arrBr, closestPoint, m ) #Membership Degree
predicted_class = sorted(membership, key=itemgetter(0), reverse=True)
final_output.append(predicted_class[0][1])
return final_output
def score(self, X_test, y_test, p, q, m):
predictions = self.predict(X_test, p, q, m)
value = 0
for i in range(len(y_test)):
if(predictions[i] == y_test[i]):
value += 1
return value / len(y_test)2.2数据预处理
乳房X光检查数据集
train_path = r'drive/MyDrive/BM-FKNCN-main/Dataset/mammographic_masses.xlsx'
data_train = pd.read_excel(train_path)
data_train.head()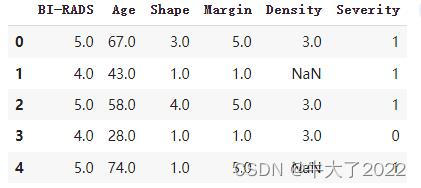
输出数据集详细信息
data_train.info()
输出一个比重,我不太清楚是什么,应该是丢失数据集率?
for col in data_train.columns:
print(col, str(round(100* data_train[col].isnull().sum() / len(data_train), 2)) + '%')
data_train.loc[(data_train['BI-RADS'].isnull()==True), 'BI-RADS'] = data_train['BI-RADS'].mean()
data_train.loc[(data_train['Age'].isnull()==True), 'Age'] = data_train['Age'].mean()
data_train.loc[(data_train['Shape'].isnull()==True), 'Shape'] = data_train['Shape'].mean()
data_train.loc[(data_train['Margin'].isnull()==True), 'Margin'] = data_train['Margin'].mean()
data_train.loc[(data_train['Density'].isnull()==True), 'Density'] = data_train['Density'].mean()
for col in data_train.columns:
print(col, str(round(100* data_train[col].isnull().sum() / len(data_train), 2)) + '%')
2.3输出视图
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
from matplotlib.colors import LinearSegmentedColormap
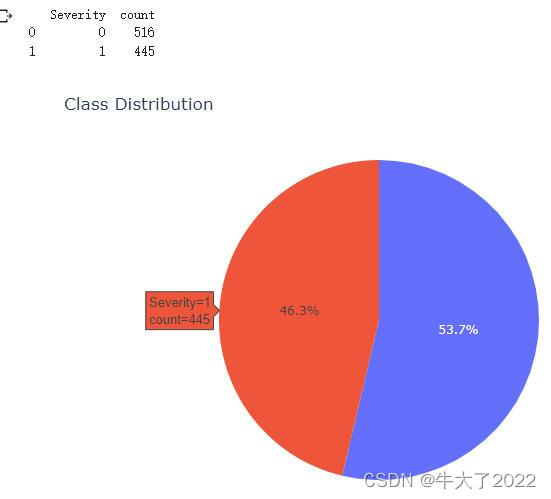
countClass = data_train['Severity'].value_counts().reset_index()
countClass.columns = ['Severity', 'count']
print(countClass)
fig = px.pie(
countClass,
values='count',
names="Severity",
title='Class Distribution',
width=700,
height=500
)
fig.show()统计了患病人数和比例
np.unique(np.array(data_train['Severity']))症状这个变量矩阵,肯定是0-1,得与没得的差别
array([0, 1])
输出患者和未患者的受每种影响因素及是否患病的两两关系图
features = data_train.iloc[:,:5].columns.tolist()
plt.figure(figsize=(18, 27))
for i, col in enumerate(features):
plt.subplot(6, 4, i*2+1)
plt.subplots_adjust(hspace =.25, wspace=.3)
plt.grid(True)
plt.title(col)
sns.kdeplot(data_train.loc[data_train["Severity"]==0, col], label="alive", color = "blue", shade=True, cut=0)
sns.kdeplot(data_train.loc[data_train["Severity"]==1, col], label="dead", color = "yellow", shade=True, cut=0)
plt.subplot(6, 4, i*2+2)
sns.boxplot(y = col, data = data_train, x="Severity", palette = ["blue", "yellow"]) 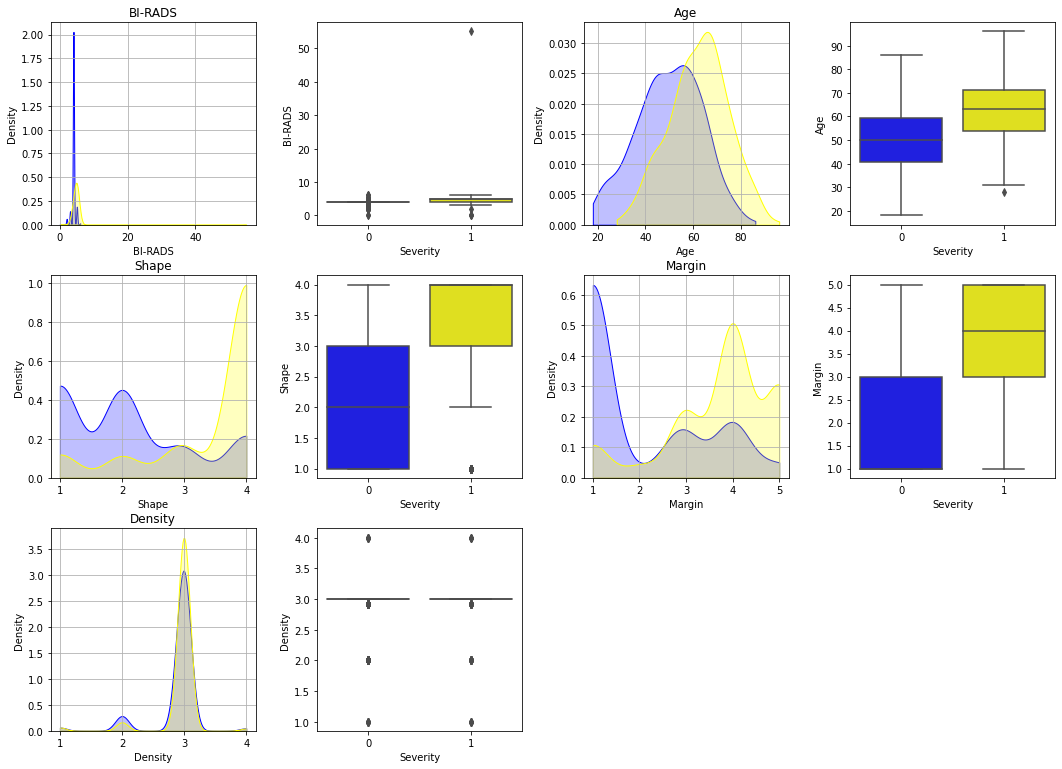
数据处理:
label_train = data_train.iloc[:,-1].to_numpy()
fitur_train = data_train.iloc[:,:5].to_numpy()
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(fitur_train)
fitur_train_normalize = scaler.transform(fitur_train)2.4调用各种方法看准确率
2.4.1BM-FKNCN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
rataBMFKNCN=[]
for train_index, test_index in kf.split(fitur_train_normalize):
X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]
y_train, y_test = label_train[train_index], label_train[test_index]
bmfkncn = BM_FKNCN(9)
bmfkncn.fit(X_train, y_train)
prediction = bmfkncn.score(X_test, y_test, 1, 1, 2)
rataBMFKNCN.append(prediction)
print('Mean Accuracy: ', np.mean(rataBMFKNCN))Mean Accuracy: 0.7960481099656358
(不知道为啥跑了8分钟……几个数为按理说不应该那么长)
2.4.2BM-FKNN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
rataBMFKNN = []
for train_index, test_index in kf.split(fitur_train_normalize):
X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]
y_train, y_test = label_train[train_index], label_train[test_index]
bmfknn = BM_FKNN(9)
bmfknn.fit(X_train, y_train)
prediction = bmfknn.score(X_test, y_test, 1, 1, 2)
rataBMFKNN.append(prediction)
print('Mean Accuracy: ', np.mean(rataBMFKNN))Mean Accuracy: 0.7981421821305843
2.4.3FKNCN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
rataFKNCN = []
for train_index, test_index in kf.split(fitur_train_normalize):
X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]
y_train, y_test = label_train[train_index], label_train[test_index]
fkncn = FKNCN(9)
fkncn.fit(X_train, y_train)
prediction = fkncn.score(X_test, y_test)
rataFKNCN.append(prediction)
print('Mean Accuracy: ', np.mean(rataFKNCN))Mean Accuracy: 0.7783290378006873
这也跑了8分钟……看了FKNCN确实慢
2.4.4FKNN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
accuracyFKNN = []
for train_index, test_index in kf.split(fitur_train_normalize):
X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]
y_train, y_test = label_train[train_index], label_train[test_index]
fknn = FKNN(9)
fknn.fit(X_train, y_train)
prediction = fknn.score(X_test, y_test)
accuracyFKNN.append(prediction)
print('Mean Accuracy: ', np.mean(accuracyFKNN))Mean Accuracy: 0.7783290378006873
2.4.5KNN
from sklearn.neighbors import KNeighborsClassifier
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
rata = []
for train_index, test_index in kf.split(fitur_train_normalize):
X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]
y_train, y_test = label_train[train_index], label_train[test_index]
neigh = KNeighborsClassifier(n_neighbors=9)
neigh.fit(X_train, y_train)
prediction = neigh.score(X_test, y_test)
rata.append(prediction)
print('Mean Accuracy: ', np.mean(rata))Mean Accuracy: 0.7981421821305843
柱状图看一下
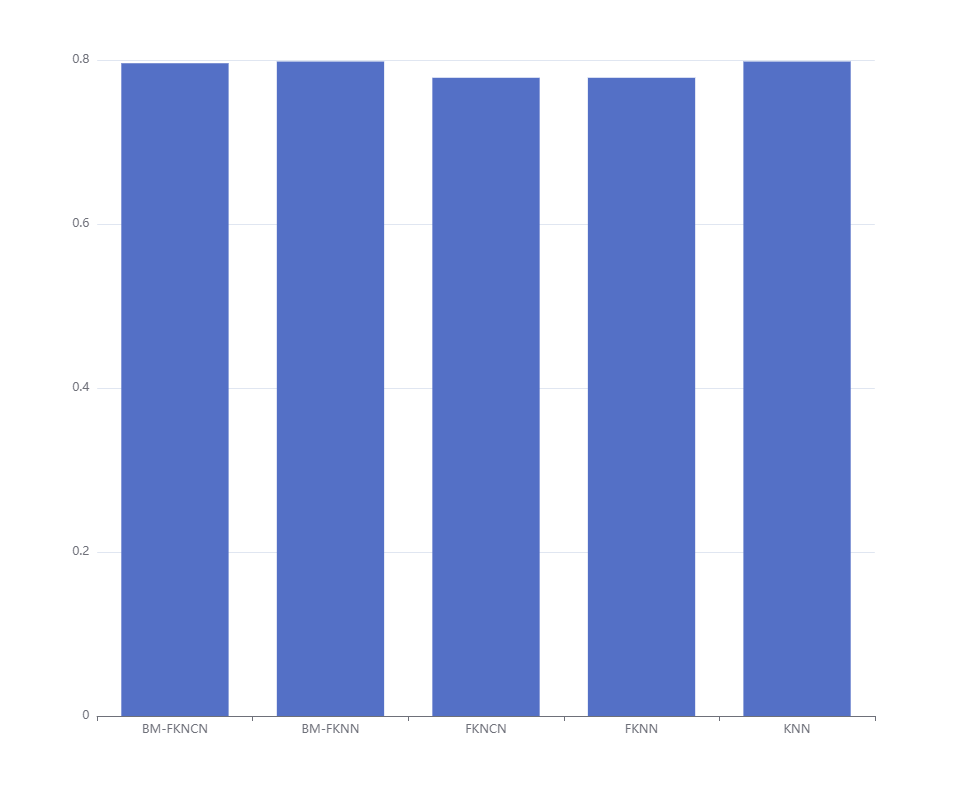
简单看,对于这组数据,BM-FKNN和KNN表现最好。
来源有更多数据集供分析,这里不再列举。
多组实验最后平均准确率:
Average of Accuracy
KNN = 0,8630
FKNN = 0,8666
FKNCN = 0,8637
BM-FKNN = 0,8634
BM-FKNCN = 0,8986
实验结果表明,与其他四个分类器相比,BM-FKNCN实现了89.86%的最高总体平均分类精度。
来源:GitHub - baguspurnama98/BM-FKNCN: A Bonferroni Mean Based Fuzzy K-Nearest Centroid Neighbor (BM-FKNCN), BM-FKNN, FKNCN, FKNN, KNN Classifier