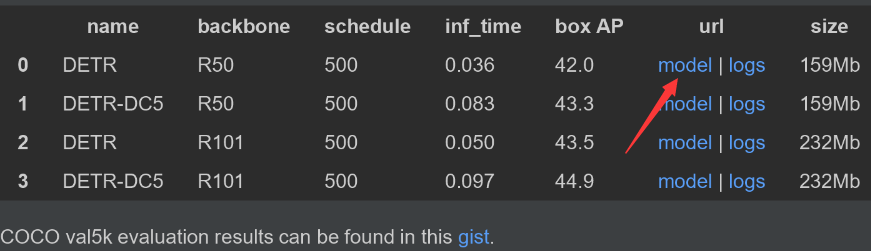
下载地址:
https://github.com/facebookresearch/detr
调试过程开始了
环境配置
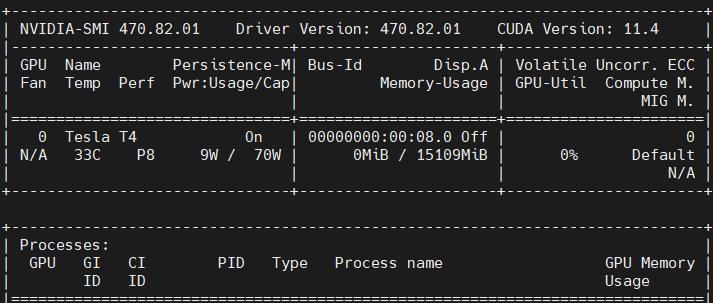
我们依旧使用的是NVIDIA T4 GPU 服务器
创建conda环境
conda create -n detr python=3.8
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
在安装依赖时报错:
WARNING conda.core.path_actions:verify(962): Unable to create
environments file. Path not writable.
采用命令sudo chown -R 1000:1000 /home/×××(yourname)/.conda 给予conda权限
对于博主而言即为:
sudo chown -R 1000:1000 /home/ubuntu/.conda
注意,在给予权限后需要重启一下。
但重启后发现依旧存在问题,如下,我们给了权限后依旧于事无补。
NoWritablePkgsDirError: No writeable pkgs directories configured.
- /usr/local/miniconda3/pkgs
- /home/ubuntu/.conda/pkgs
此时博主通过pip list发现,其实该包早已经安装成功了。
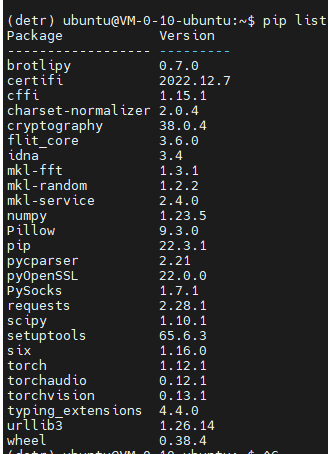
这种情况博主也是第一次遇到,至于原因:
首先,所有的包,不论base环境还是虚拟环境都是放在pkgs文件夹下。如果虚拟环境需要安装的包与pkgs中已有的包版本完全一样,则不会再下载,而是通过硬盘链接直接找到该包,反之当一个包被多个环境使用时,从某一个环境卸载该包也不会将其从pkgs文件夹删除。
随后便是将代码上传到服务器上。
然后我们使用Pycharm的Terminal连接服务器,激活环境并切换至detr代码存放目录

按照要求下载对应依赖包
pip install -r requirements.txt
-i https://mirrors.bfsu.edu.cn/pypi/web/simple/
但在执行这个命令时总是报错:
This error originates from a subprocess, and is likely not a problem
with pip.
而在详细看过错误信息后发现实际上其是由于无法下载coco的相关文件从而无法继续,而我们并不打算使用原始的COCO数据集。那么我可以考虑直接按照我们需要的依赖包即可。也就是下面几个:
pip install scipy
pip install onnx
pip install onnxruntime
pip install submitit 分布式训练可以使用Slurm和submitit,这里我们不需要
安装pycocotools和scipy,用于在COCO数据集上进行evaluation及训练
pip install pycocotools #使用这条命令安装pycocotools
数据集处理
随后我们需要将我们的自定义数据集转换为COCO格式。并顺带完成训练集与验证集的划分:
# coding:utf-8
# pip install lxml
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
path2 = "E:/graduate/datasets/cadcd/VOC2023/VOC2023/COCO"
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
image_id = 20190000001 + index
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
#assert (xmax > xmin), "xmax <= xmin, {}".format(line)
if xmax <= xmin:
continue
if ymax <= ymin:
continue
#assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
classes = ['car', 'truck', 'bus', 'person','sign']
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
# pre_define_categories = {'a1': 1, 'a3': 2, 'a6': 3, 'a9': 4, "a10": 5}
only_care_pre_define_categories = True
# only_care_pre_define_categories = False
train_ratio = 0.9
save_json_train = 'train2023.json'
save_json_val = 'val2023.json'
xml_dir = "E:/graduate/datasets/cadcd/VOC2023/VOC2023/Annotations"
xml_list = glob.glob(xml_dir + "/*.xml")
xml_list = np.sort(xml_list)
np.random.seed(100)
np.random.shuffle(xml_list)
train_num = int(len(xml_list) * train_ratio)
xml_list_train = xml_list[:train_num]
xml_list_val = xml_list[train_num:]
convert(xml_list_train, save_json_train)
convert(xml_list_val, save_json_val)
if os.path.exists(path2 + "/annotations"):
shutil.rmtree(path2 + "/annotations")
os.makedirs(path2 + "/annotations")
if os.path.exists(path2 + "/images/train2023"):
shutil.rmtree(path2 + "/images/train2023")
os.makedirs(path2 + "/images/train2023")
if os.path.exists(path2 + "/images/val2023"):
shutil.rmtree(path2 + "/images/val2023")
os.makedirs(path2 + "/images/val2023")
f1 = open("train.txt", "w")
for xml in xml_list_train:
img = xml[:-4] + ".png"
img=img.replace("Annotations", "JPEGImages")
print(img)
f1.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/images/train2023/" + os.path.basename(img))
f2 = open("test.txt", "w")
for xml in xml_list_val:
img = xml[:-4] + ".png"
img=img.replace("Annotations", "JPEGImages")
f2.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/images/val2023/" + os.path.basename(img))
f1.close()
f2.close()
print("-------------------------------")
print("train number:", len(xml_list_train))
print("val number:", len(xml_list_val))
此外还可通过Annocations来进行划分的,此时不进行训练集,验证集的划分。
关于COCO数据集中的参数解析
{
"info" : info,
"licenses" : [license],
"images" : [image],
"annotations" : [annataton],
"categories" : [category]
}
最终完成标注转换与数据集划分:

代码修改
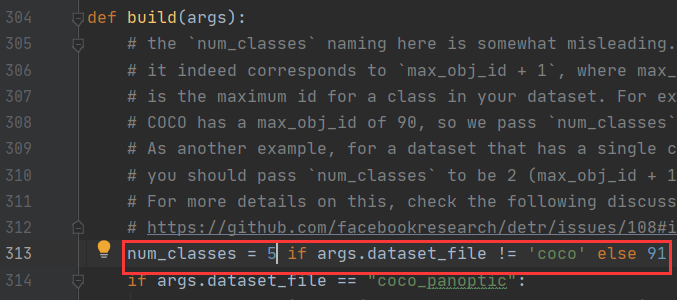
此时我们需要修改model/detr.py中的num_classes改成你的物体种类的数目。
随后为了让我们加快训练我们可以去官网下载预训练模型:
下载完成后执行下面代码来修改一下模型:
import torch
pretrained_weights = torch.load('detr-r50-e632da11.pth')
num_class = 6 #这里是你的物体数+1,因为背景也算一个
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1, 256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights, "detr-r50_%d.pth"%num_class)
随后我们修改下main.py的配置文件中的路径:
parser.add_argument('--coco_path', default='/home/ubuntu/detr/data/',type=str)

修改预训练模型
这里有个疑惑,在本地运行时使用默认的resnet-50正常,但在服务器上却报错。后来考虑大概是有用先前在本地运行时下载了resnet-50模型的原因。这里我们的骨干网络依旧使用resnet-50
parser.add_argument('--backbone', default='resnet-50', type=str,
help="Name of the convolutional backbone to use")
修改resume为自己的预训练权重文件路径
parser.add_argument('--resume', default='detr-r50_6.pth', help='resume from checkpoint')
随后再修改epoch=300与batch-size=32,num_workers=6。
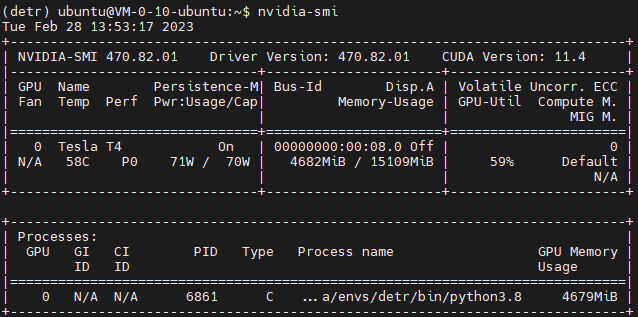
GPU使用情况如下:由此可见,该模型并不是很吃配置。
然后修改datasets/coco.py中的文件路径与标注路径:
PATHS = {
"train": (root / "images/train2023", root / "annotations" / f'train2023.json'),
"val": (root / "images/val2023", root / "annotations" / f'val2023.json'),
}

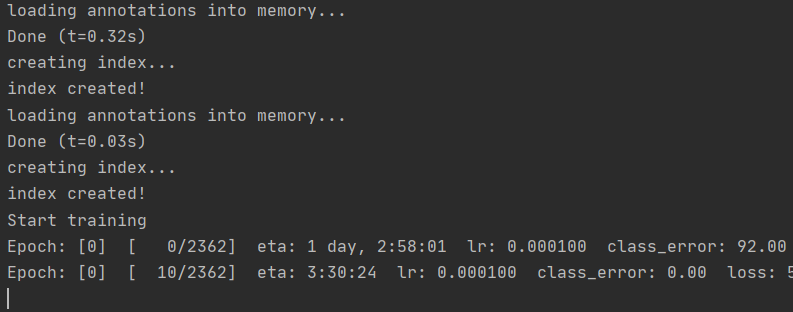
完成后运行main.py即可,运行成功:
结语
个人觉得在训练那块还是改main.py文件比较好,需要改的地方挺多,我觉得需要修改的主要有–epoch(轮次)、–num_workers(主要看你电脑性能怎么样,好点可以调高些)、–output_dir(输出的模型权重,pth文件)、–dataset_file(数据存放位置)、–coco_path(coco数据集的位置)和–resume(预训练权重文件位置)。