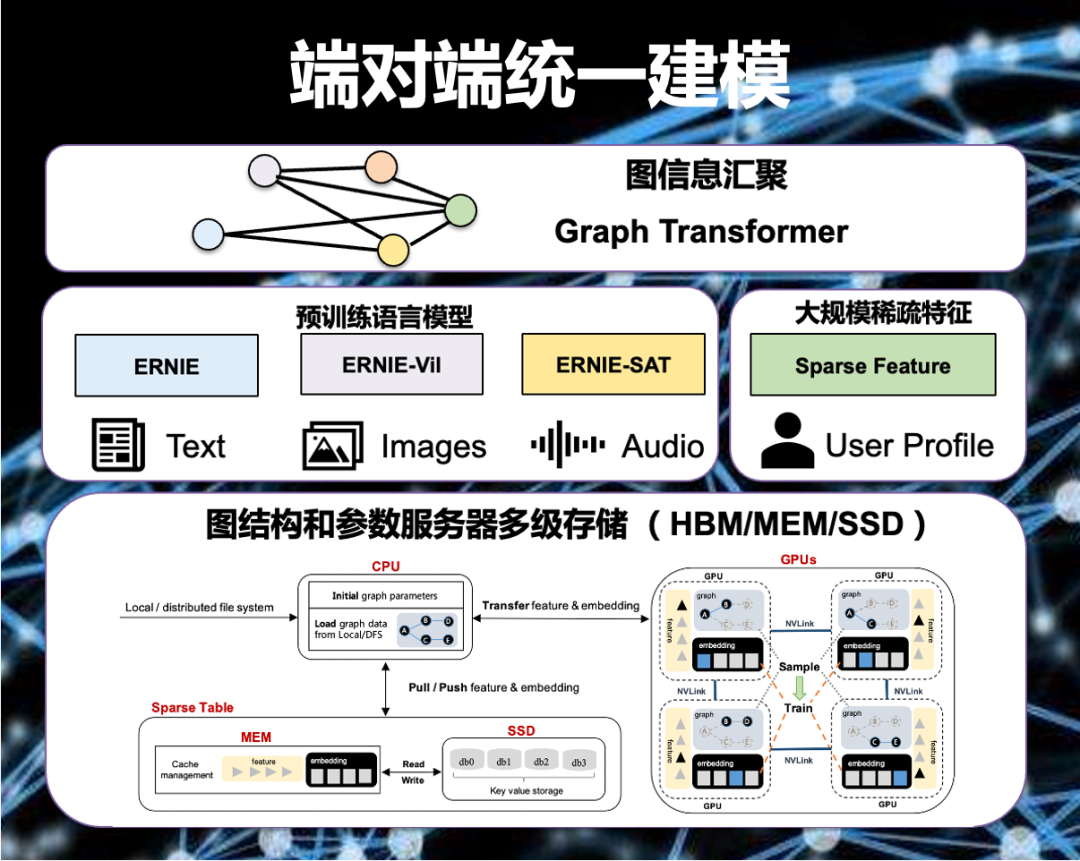
数字化经济时代,IT架构复杂性越来越高,业务连续性成为很多行业或企业最核心的任务。业务连续性管理是一个不断提升的过程,围绕事件“发现-响应-定位处理-降低发生”的事件处理思路,结合平台化运维,助力业务快速提升。
我们将具体事件从监控、调查、上报和响应几个环节来处理。即当平台监控发现异常,进行事件优先级分类,判断事件处理的紧迫性,分析事件影响造成破坏程度,然后进行事故调查与诊断,快速定位识别问题,联系现场工程师最终解决问题,事件流程结束。
围绕事件提升业务连续性的优势在于:主动快速处理使业务恢复正常,将影响降至最低。流程闭环提高用户满意度,最大程度降低事件处理成本。下面我们来看案例的处理过程。
一、问题发现
夜间服务器在飞速运转,主要进行流程审批、数据库备份、报表统计这类定时、耗时的工作。夜间无人值守的机房,加上高速飞转的服务器,很容易触发故障。
2月1日凌晨4:40分,平台接到某服务器ping不通告警,检测到此服务器发生死机现象。这台服务器已经连续发生几次夜间死机故障。
二、问题分析定位
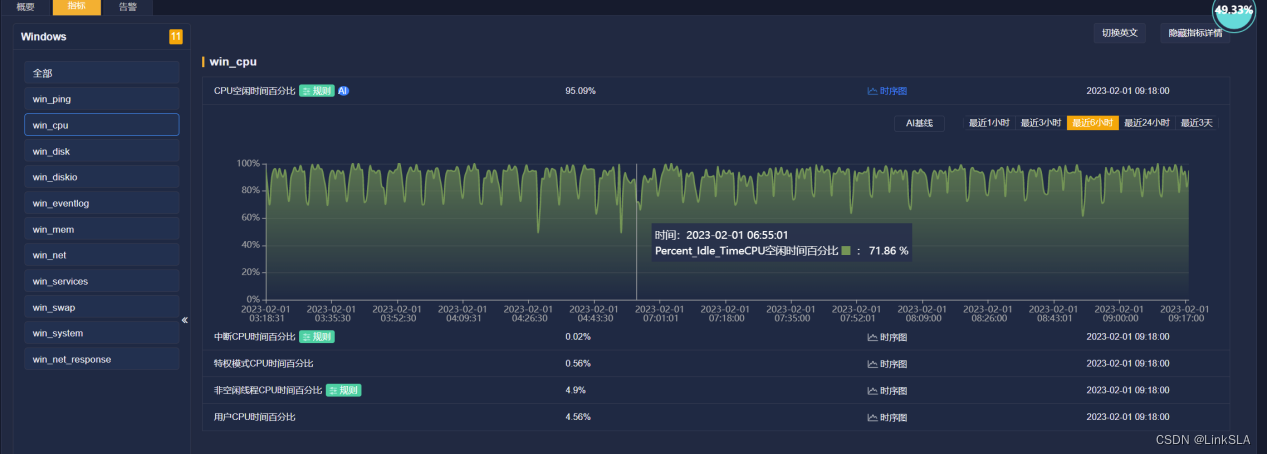
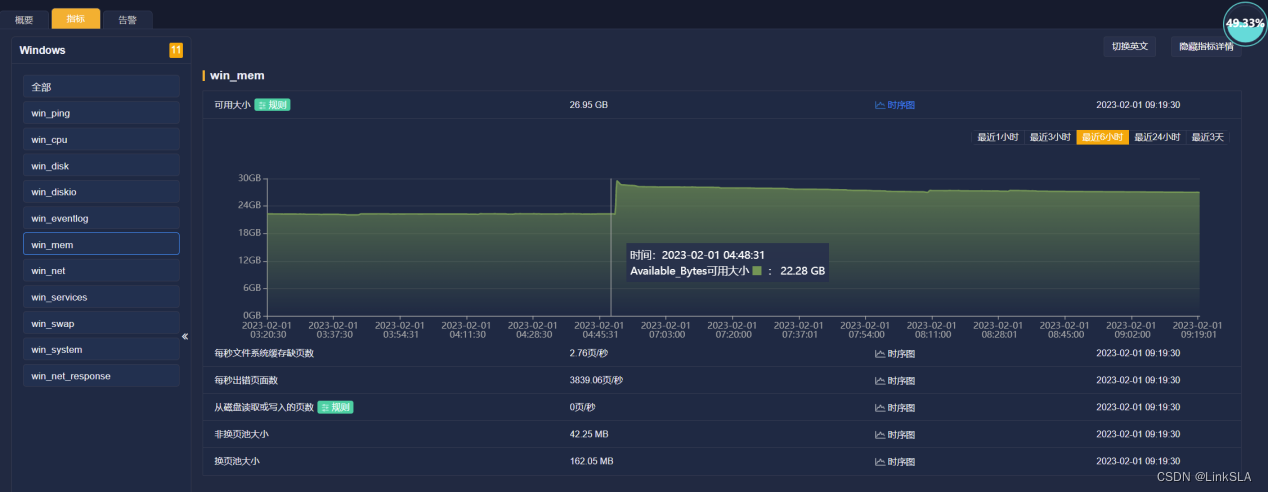
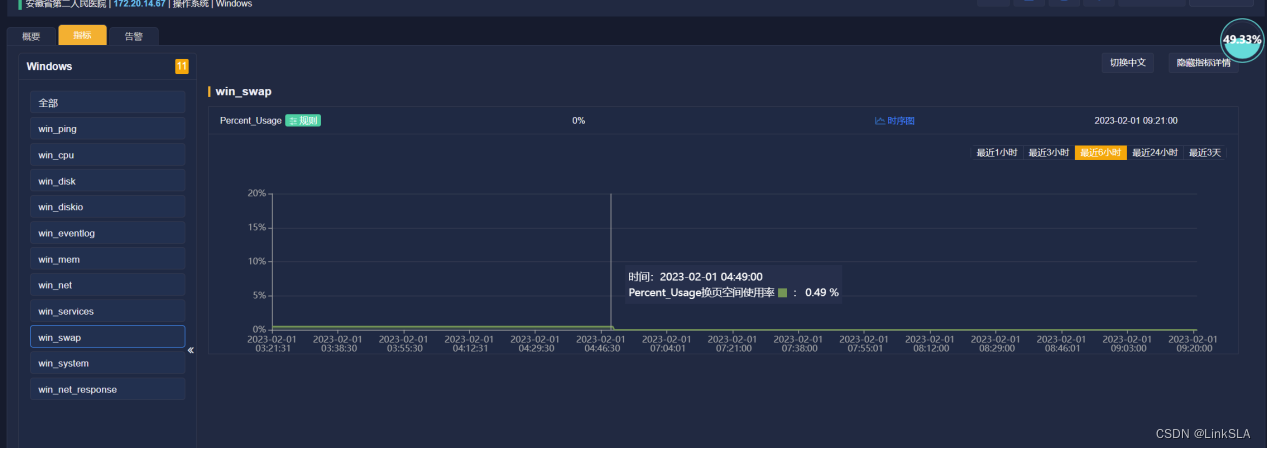
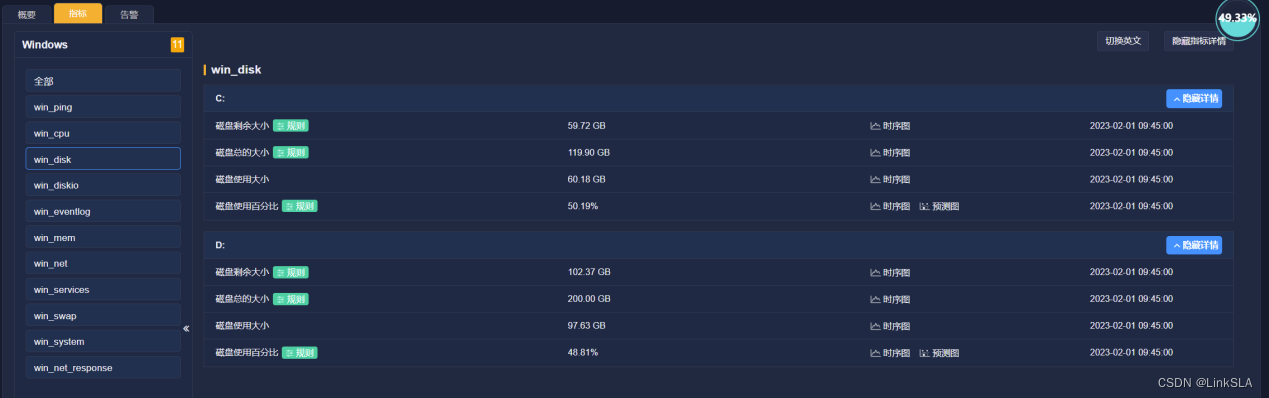
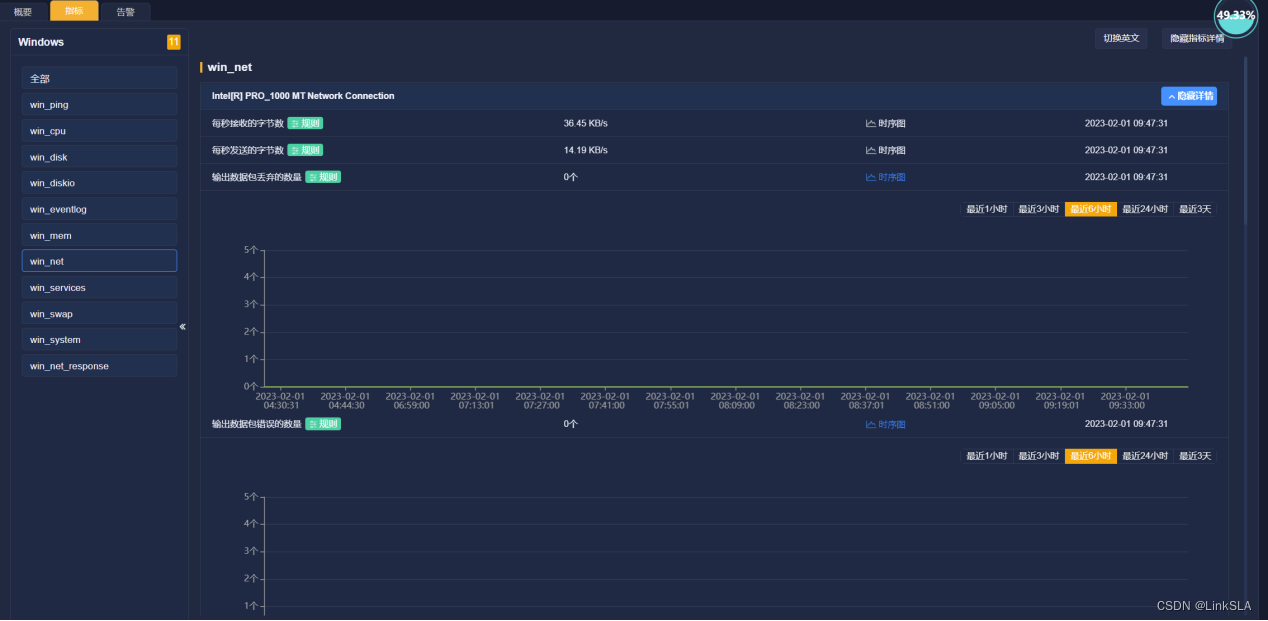
根据时序图,协助服务器管理工程师查找故障发生的具体原因。查看4:40分前后,CPU,内存和虚拟内存,磁盘使用等运维参数如下
1 CPU没有异常,空闲率达到70%以上
2、可用内存22.28G,充足
3、虚拟内存使用率只有0.49%
4、硬盘剩余可用空间充足、
5、网络输出输入数据也是正常
6、在4:40-6:48左右,ping不通,服务器已发生死机。4:40-6:48之间的服务器运行指标参数没有上传
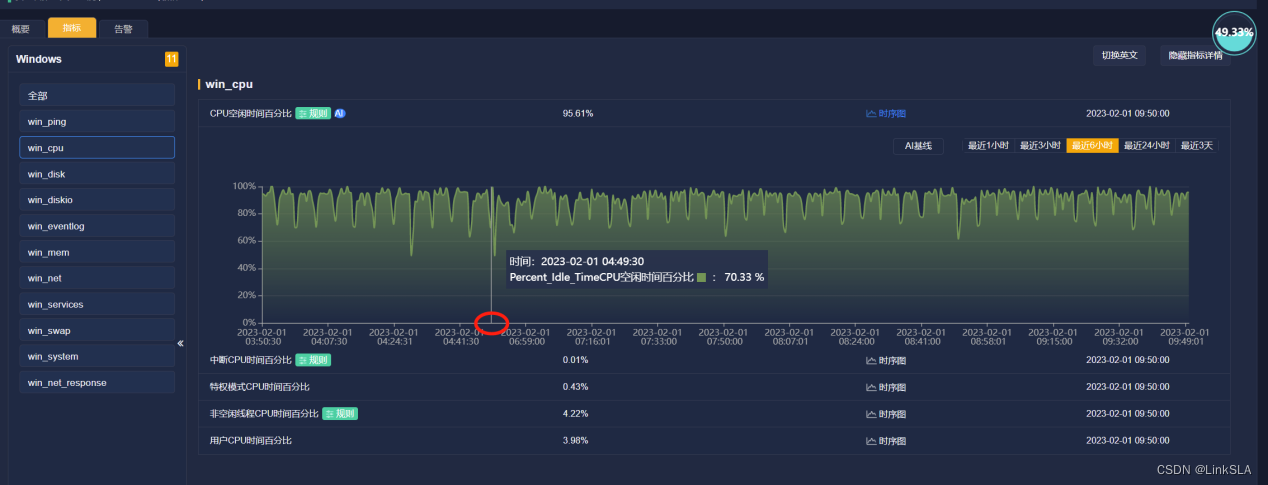
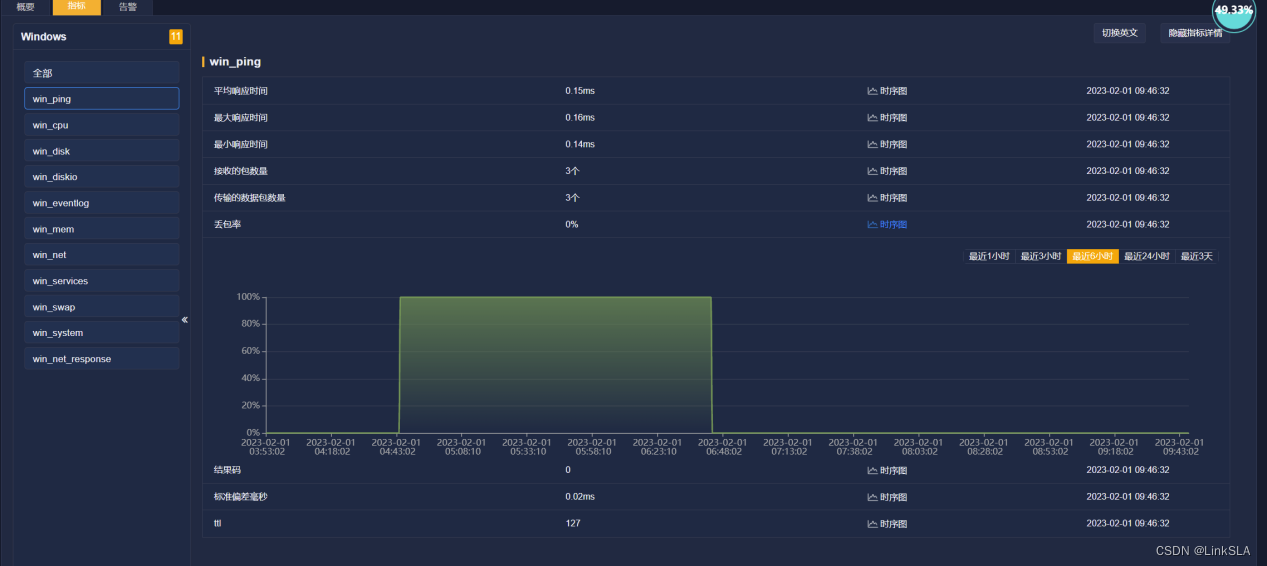
7、从服务器发生死机前和重启后的运维参数看,服务器的资源配置充足,并非是资源争用导致死机。
8、查看服务器运行日志,服务器并没有自动进行打补丁更新,但是组策略配置有告警生成
平台未接到安全攻击告警,也未接收到硬件故障告警,首先排除病毒攻击;硬件故障,服务器资源匮乏,且近期应用软件未升级、变更,其次则排除软件问题。最后锁定操作系统问题。服务器管理工程师对操作系统进行了打补丁升级处理。后期持续对这台服务器进行重点监控,未产生故障,问题得到解决。
服务器宕机,可能导致客户无法访问,业务中断造成巨大的经济损失;也可能影响数据备份,导致数据丢失;夜间无人值守,故障重启等问题不易察觉,LinkSLA智能运维管家不仅能够及时监测到服务器故障,第一时间进行反馈,可以根据历史运维指标数据,进行分析,协助用户查找出故障的根本原因,从根本上解决问题。
四、总结
除了实时发现告警,及时处理,流程闭环外,还需加强问题管理以及自动巡检服务出发,从源头上降低故障事件发生。
基于业务系统的多样性,还可为业务发展提供依据,通过一段时间的监控数据累积,利用监控系统提供的报表功能对数据进行统计处理,帮助用户做系统升级决策,如是否需要采购新硬件、是否需要新增系统节点等。另外,还可以利用系统的监控大屏功能,对系统的整体健康状况做到一目了然,做到资源、业务的可视化。