文章目录
- 一、Apache Hive概述
- 1.1、什么是Hive
- 1.2、使用Hive原因
- 1.3、Hive和Hadoop关系
- 二、Hive功能思想
- 2.1、映射信息记录
- 2.2、SQL语法解析、编译
- 三、Hive架构、组件
- 3.1、Hive架构图
- 3.2Hive组件
- 四、Hive常用操作
- 4.1、数据类型
- 4.1.1、基本数据类型
- 4.1.2、集合数据类型
- 4.2、数据库
- 4.3、数据表
- 4.3.1、创建表语法
- 4.3.2、external
- 4.3.3、 temporary
- 4.3.4、 在创建表时没有导入数据使用
- 4.3.5、 partitioned by分区表
- 4.3.6、 clustered by ... sorted by ... into ...buckets分桶表
- 4.3.7、CTAS
- 4.3.8、CTE
- 4.3.9、LIKE
- 4.3.10、export(导出)、import(导入)
- 4.3.11、清空表数据
一、Apache Hive概述
1.1、什么是Hive
- Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,成为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop执行。
- Hive官网
1.2、使用Hive原因
- 使用Hadoop MapReduce直接处理数据所面临的问题。
人员学习成本高,需要掌握java语言。
MapReduce实现复杂查询逻辑开发难度太大。
- 使用Hive处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力。(简单、容易上手)
避免直接写MapReduce,减少开发人员的学习成本。
支持自定义函数,功能扩展方便。
背靠Hadoop,擅长存储分析海量数据集。
1.3、Hive和Hadoop关系
- Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop最核心的设计就是hdfs和mapreduce,hdfs提供存储,mapreduce用于计算。
- Hive是Hadoop的延申。hive是一个提供了查询功能的数据仓库核心组件,Hadoop底层的hdfs为hive提供了数据存储,mapreduce为hive提供了分布式运算。
- Hive可以直接通过SQL操作Hadoop,sql简单易写,可读性强,hive将用户提交的SQL解析为MapReduce任务供Hadoop直接运行。
二、Hive功能思想
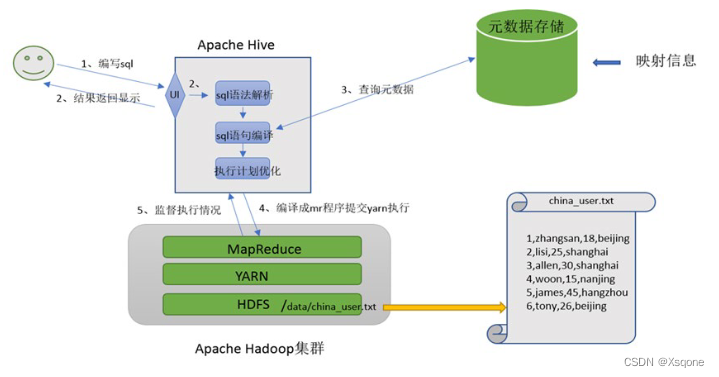
2.1、映射信息记录
- 映射在数学十行称之为一种对应关系,比如y=x+1,对于每一个x的值都有与之对应的y的值。
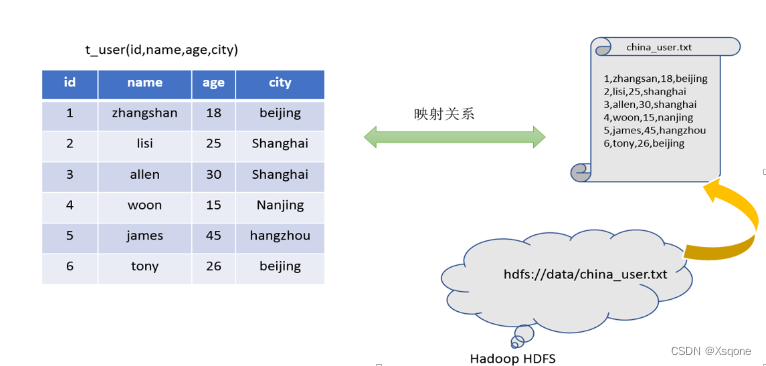
- 在hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。
映射信息专业名称为:元数据信息(元数据是值用来描述数据的数据 metadata) - 具体来看,要记录的元数据信息包括:
表对应着哪个文件(位置信息)、表的列对应着文件哪一个字段(顺序信息)、文件字段之间的分隔符是什么。
2.2、SQL语法解析、编译
- 用户写完SQL之后,Hive会针对SQL进行语法校验,并且根据记录的元数据信息解读sql背后的含义,制定执行计划。
- 并且把执行计划转换成MapReduce程序来具体执行,把执行的结果封装返回给用户。
三、Hive架构、组件
3.1、Hive架构图
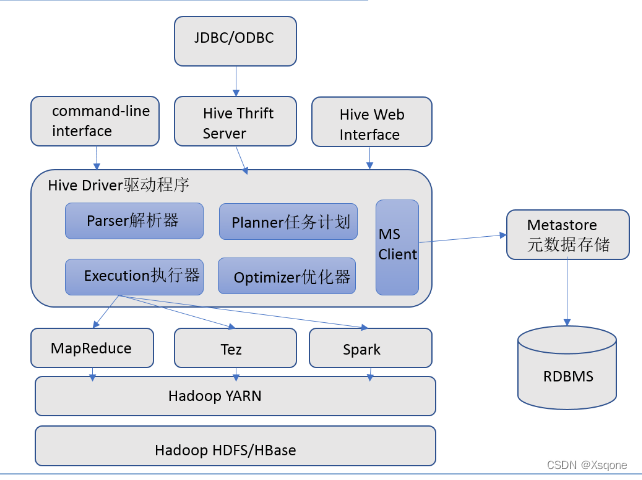
3.2Hive组件
- 用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许
外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
- 元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是
否为外部表等),表的数据所在目录等。
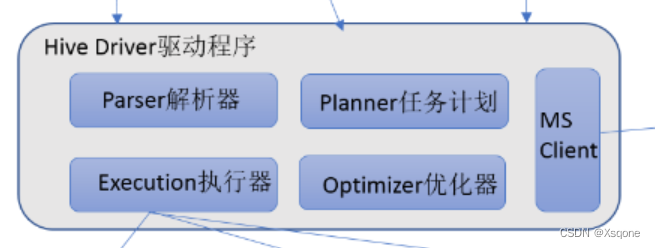
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储咋HDFS中,并在随后又执行引擎调用执行。
- 执行引擎
Hive本身并不是直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark 3种执行引擎。

四、Hive常用操作
4.1、数据类型
4.1.1、基本数据类型
| 类型 | 实例 |
|---|---|
| TINYINT | 10 |
| INT | 10 |
| SMALLINT | 10 |
| BIGINT | 100L |
| FLOAT | 1.342 |
| DOUBLE | 1.234 |
| BINARY | 1010 |
| BOOLEAN | TRUE |
| DECIMAL | 3.14 |
| CHAR | 'book’or"book" |
| STRING | 'book’or"book" |
| VARCHAR | 'book’or"book" |
| DATE | ‘2023-02-27’ |
| TIMESTAMP | ‘2023-02-277 00:00:00’ |
4.1.2、集合数据类型
| 类型 | 格式 | 定义 | 示例 |
|---|---|---|---|
| ARRAY | [‘apple’,‘hive’,‘orange’] | ARRAY< string> | a[0]=‘apple’ |
| MAP | {‘a’:‘apple’,‘o’:‘orange’} | MAP< string,string> | b[‘a’]=‘apple’ |
| STRUCT | {‘apple’,2} | STRUCT< fruit:string,weight:int> | c.weight=2 |
4.2、数据库
数据库在HDFS中表现为一个文件夹,在配置文件中hive.metastore.warehouse.dir属性目录下。
如果没有指定数据库,默认使用default数据库

# 创建数据库
create database if not exists 库名;
# 使用数据库
use 库名;
# 查看数据库
show databases;
# 查看数据库详细信息
describe database 库名;
# 修改数据库的使用者
alter database 库名 set owner user 用户名;
# 强制删除数据库(cascade) 在不使用cascade时若库内有表有数据时,会删除失败。
drop database if exists 库名 cascade;
# 查看当前数据库
select current_database();
4.3、数据表
- 分为内部表和外部表
- 内部表
- HDFS中为所属数据库目录下的子文件夹
- 数据完全由Hive管理,删除表(元数据)会删除数据
- 外部表
- 数据保存在指定位置的HDFS路径下
- Hive不完全管理数据,删除表(元数据)不会删除数据
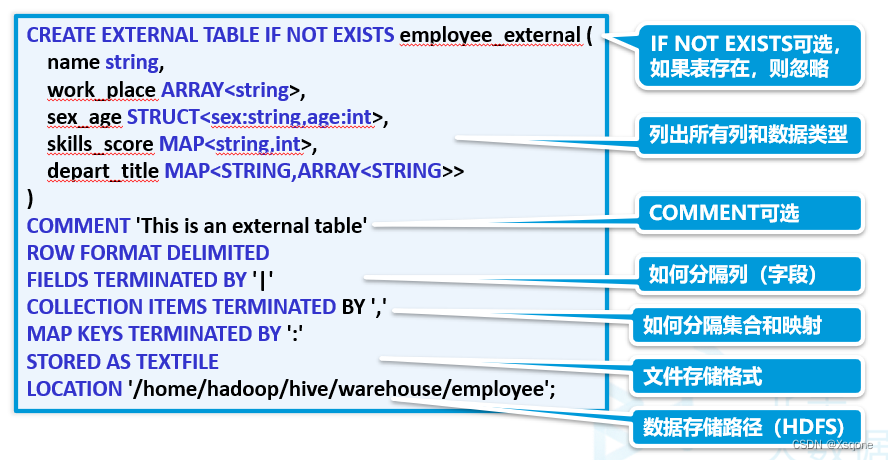
4.3.1、创建表语法
create [ temporary] [ external] table [ if not exists]
[db_name.]table_name
[(col_name data_type [ comment col_comment], ...)]
[ comment table_comment]
[ partitioned by (col_name data_type [ comment col_comment], ...)]
[ clustered by (col_name, col_name, ...)
[ sorted by (col_name, col_name, ...)]
[ row format row_format]
[ stored as file_format]
[ location hdfs_path]
[ tblproperties (proeprty_name=property_value, ...)]
4.3.2、external
外部表,与之对应的时内部表。内部表一位置hive会完全接管该表,包括元数据和HDFS中的数据。而外部表意味着hive只接管元数据,而不完全接管HDFS中的数据。
create external table studentwb1
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
location '/tmp/hivedata/student';
4.3.3、 temporary
临时表,该表只在当前会话可见,会话结束,表会被删除。
create temporary table studentwb1
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
location '/tmp/hivedata/student';
4.3.4、 在创建表时没有导入数据使用
#加载本地数据
load data local inpath '/opt/student.txt' into table 表名;
#加载hdfs数据(内部表时,会将文件移动到表目录下)
load data inpath '/opt/student.txt' into table 表名; (追加)
load data inpath '/opt/student.txt' overwrite into table 表名; (覆盖)
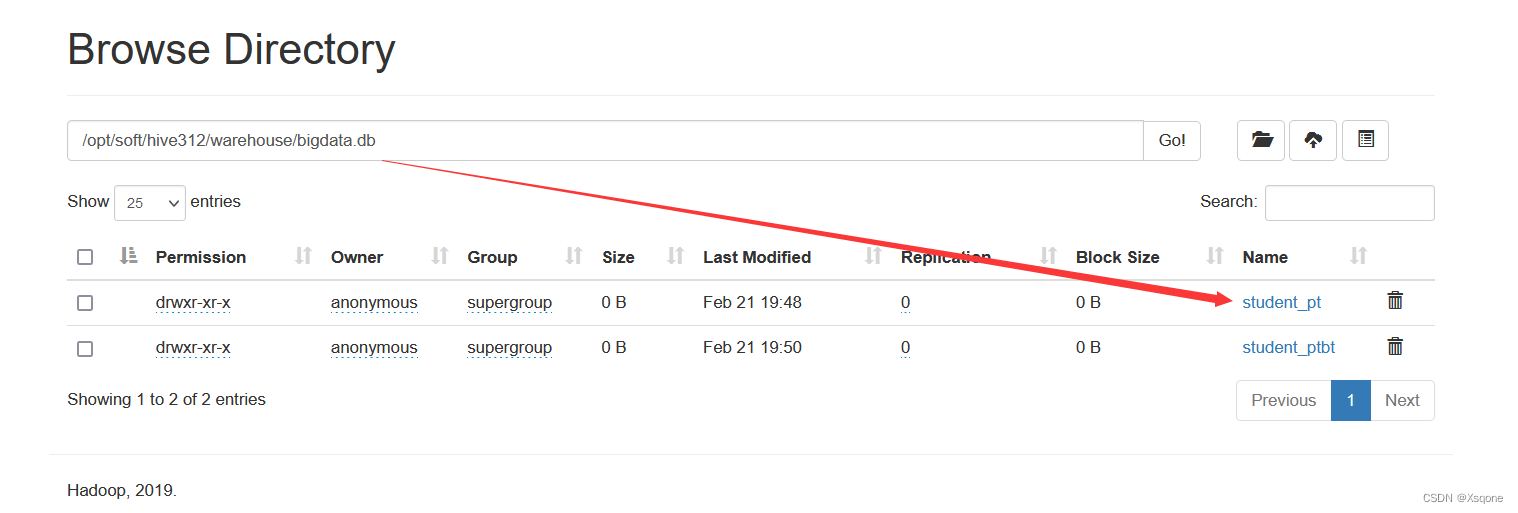
4.3.5、 partitioned by分区表
# 创建分区表
create table student_pt
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by (age int)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n';
# 直接定义分区将文件导入分区表
load data inpath "/tmp/hivedata/student/student2.txt" into table student_pt partition (age = 20);
# 将其他表数据导入分区表
-- 动态分区(可在配置文件中设置)
set hive.exec.dynamic.partition=true; --是否开启动态分区
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table student_pt partition (age)select id,name,likes,address,age from student_pt;
# 查看分区
show partitions 表名;
4.3.6、 clustered by … sorted by … into …buckets分桶表
--------------------------------------分桶表---------------------------
-------------------------原始数据-------------------------------
create table employee_id(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
# 导入数据
load data local inpath '/opt/stufile/employee_id.txt' overwrite into table employee_id;
-------------------------------创建分桶表--------------------------------------
create table employee_id_buckets(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
clustered by (employee_id) into 2 buckets --以employee_id分桶分两桶
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';
-- 设置mapreduce的任务数量为2
set map.reduce.tasks=2;
set hive.enforce.bucketing=true; --启动分桶设置
insert overwrite table employee_id_buckets select * from employee_id;
-- 获取20%的数据
select * from employee_id_buckets tablesample ( 20 percent );
-- 获取前10行数据
select * from employee_id_buckets tablesample ( 10 rows );
--分桶抽样
select * from employee_id_buckets tablesample ( bucket 5 out of 6 on rand());
分桶抽样讲解:
假设当前分桶表,一共分了z桶!(当前示例中分了2桶)
x: 代表从当前的第几桶开始抽样(从第5个开始抽样)
0<x<=y
y: z/y 代表一共抽多少桶!(一共抽2/6桶)
y必须是z的因子或倍数!
怎么抽:将一桶分了z/y,抽总体的第x份(将每一桶分为3份,抽取第5份(就是第一桶的最后部分))
4.3.7、CTAS
create table ctas_student as select * from student;
4.3.8、CTE
create table cte_table as
with
t1 as (select * from student2 where age>25),
t2 as (select * from t1 where name = 'xiaoming9'),
t3 as (select * from student2 where age<25)
select * from t2 union all select * from t3;
# (使用with查询)
with
t1 as (select * from student2 where age>25),
t2 as (select * from t1 where name = 'xiaoming9'),
t3 as (select * from student2 where age<25)
select * from t2 union all select * from t3;
4.3.9、LIKE
创建下的表数据结构一致,无数据
create table student_like like student;
4.3.10、export(导出)、import(导入)
export和import可用于两个hive实例之间的数据迁移。
- export将表的数据和元数据信息一并导出到HDFS路径。
语法:
export table tablename to ‘export_target_path’
- import将export导出的内容导入到hive。
语法:
import [ external ] table new_or_origunal_tablename from ‘source_path’ [ location ‘import_target_path’ ]
示例:
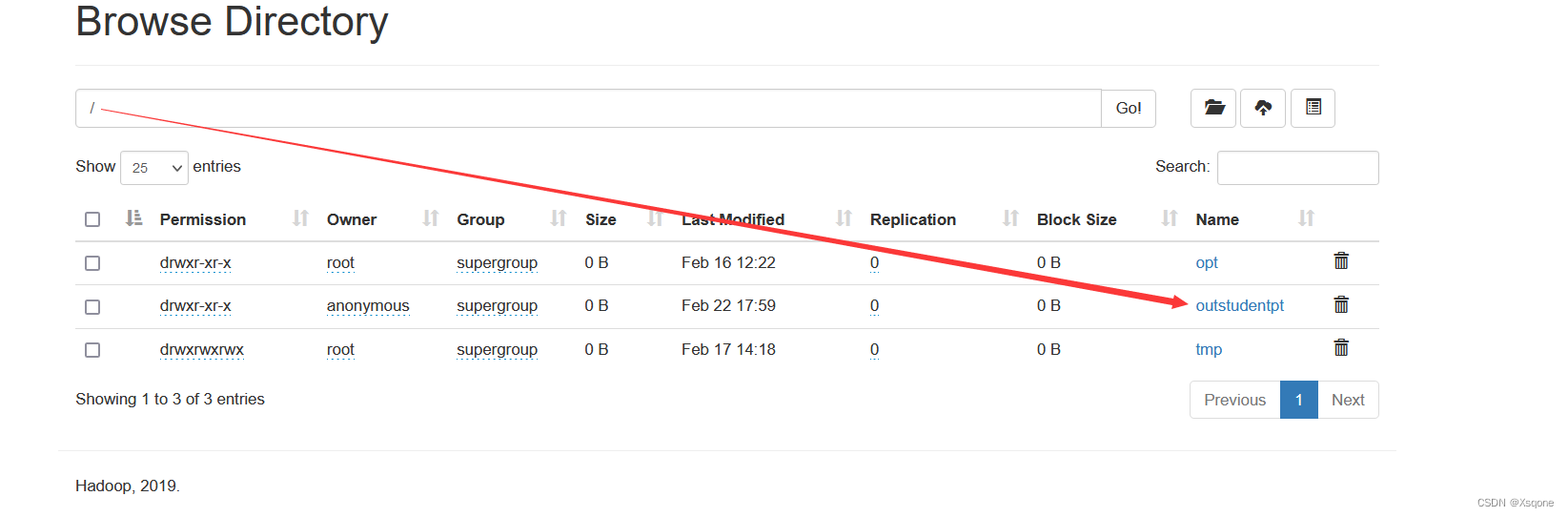
# 导出数据
export table 表名 to '/outstudentpt'; 导出到hdfs文件系统
# 导入(相等于创建一个表)
use bigdata
import table studentpt from '/outstudentpt';
4.3.11、清空表数据
# 清空表数据
truncate table 表名;