我菜就爱学

文章目录
- 目标检测实战
- 1 目标检测简介
- 1.1 目标检测分类
- 1.2 检测的任务
- 1.3 目标定位实现的思路
- 1.4 两种bbox名称解释
- 2 R-CNN
- 2.1 目标检测-Overfeat模型
- 2.2 目标检测-R-CNN模型
- 2.2.1 候选区域(ROI)
- 2.2.2 CNN网络提取特征
- 2.2.3 特征向量训练分类器SVM
- 2.2.4 非极大抑制(NMS)
- 2.2.5 修正候选区域
- 2.3 检测的评价指标
- 2.3.1 平均精确率-map :类别考虑
- 总结
- 3 改进 - SPPNet
- 3.1 提出SPP层,减少卷积计算
- 3.2 映射
- 3.3 spatial pyramid pooling(SSP)
- 4 Fast R-CNN
- 4.1 RoI pooling
- 4.2 多任务损失 - Multi-task loss
- 4.3 R-CNN 、SPPNet、Fast R-CNN 效果对比
- 5 Faster R-CNN
- 5.1 整体架构
- 5.2 RPN
- 5.3 anchosr生成的数目
- 5.4 经过Proposal层
- 5.5 ROI Pooling
- 5.6 全连接层
- 6 YOLO
- 6.1 结构
- 6.2 流程处理
- 我想说:
目标检测实战
1 目标检测简介
1.1 目标检测分类
-
两步走的目标检测:先进行区域推荐,而后再进行目标分类。R-CNN、SPP-net、
说明:先对图像里面是物体的对象进行画框,然后对框内的对象进行目标检测
-
端到端的目标检测:采用一个网络一步到位。YOLO、SSD
1.2 检测的任务
分类:
- N个类别
- 输入:图片
- 输出:类别标签、物体的位置坐标
- 评估指标:IOU
预测返回得出物体位置:bounding box(bbox):
- x,y,w,h :x,y物体的中心点坐标,已经中心的距离物体两边的长宽
- xmin,ymain,xmax,ymax:物体位置的左上角、右下角坐标
1.3 目标定位实现的思路
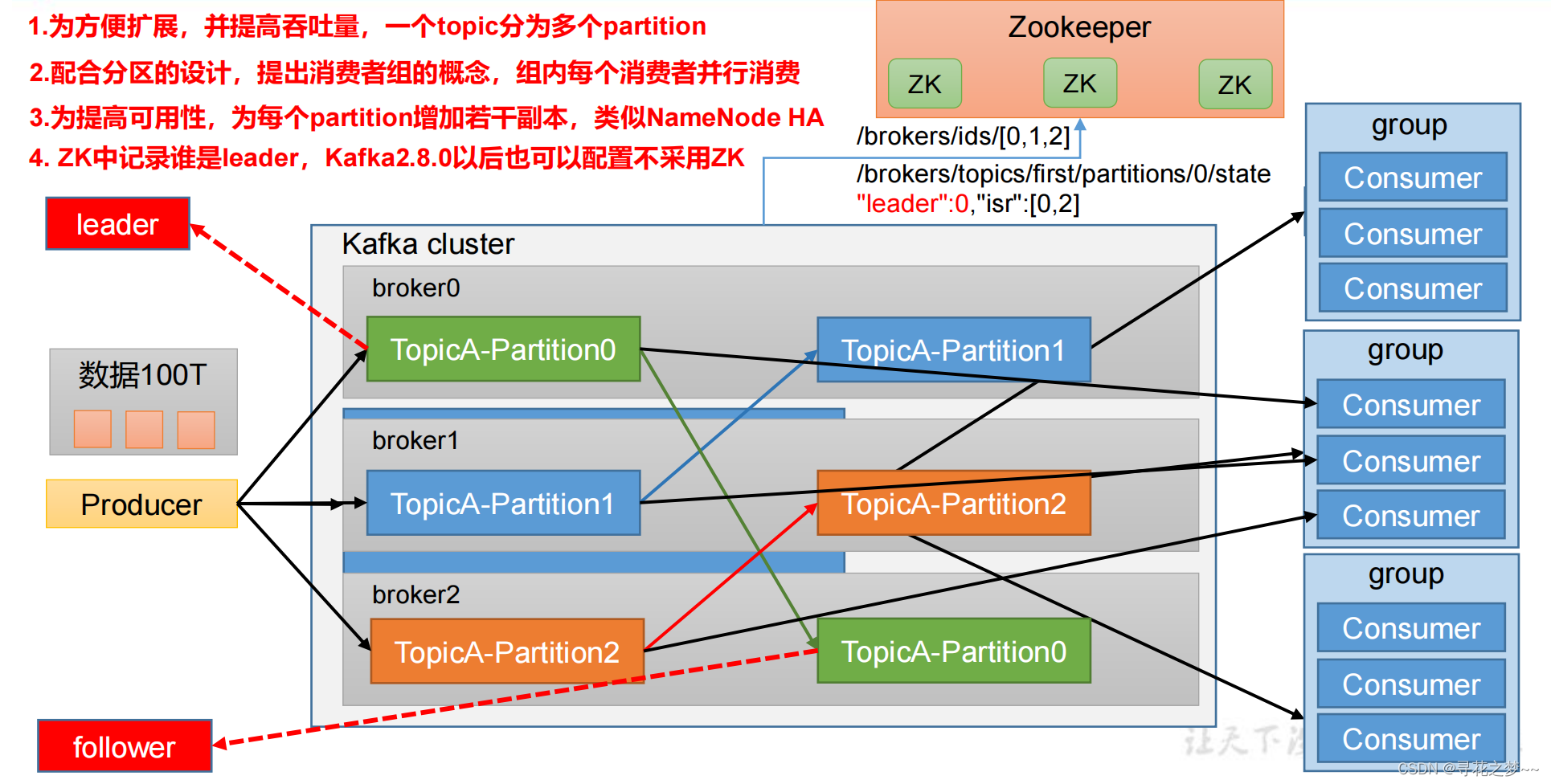
说明:分类的时候直接输出各个类别的概率,如果再加上定位,就在网络的最后输出层加上位置信息。如下:增加一个全连接层,即为FC1、FC2。FC1:作为类别的输出。FC2:作为这物体位置数值的输出。预测位置和目标值位置都是坐标,可以用MSE均方误差计算损失值。
1.4 两种bbox名称解释
- GTbbox:图片真实目标位置
- Predicted boundingh box :预测的时候标记的框位置
- 分类定位:图片只有一个物体需要检测
- 目标检测:图片中多个物体检测
2 R-CNN
说明:对于多个目标情况,不能以固定个数输出物体的位置值。如上FC1、FC2
2.1 目标检测-Overfeat模型
1)原始目标检测的暴力算法是从左到右,从上到下滑动窗口,利用分类识别目标。
说明:为了在不同观察距离处检测不同的目标类型,使用若干个不同大小和宽高比的窗口。这样就变成每张子图片输出类别以及位置,变成分类的问题。但是,滑动窗户需要初始设定一个固定大小的窗口。即需要提前设定k个窗口,每个窗口滑动提取M个,总共K * M个图片,直接将图像变形转换成固定大小的图像,变形图像块被输入CNN分类器中。

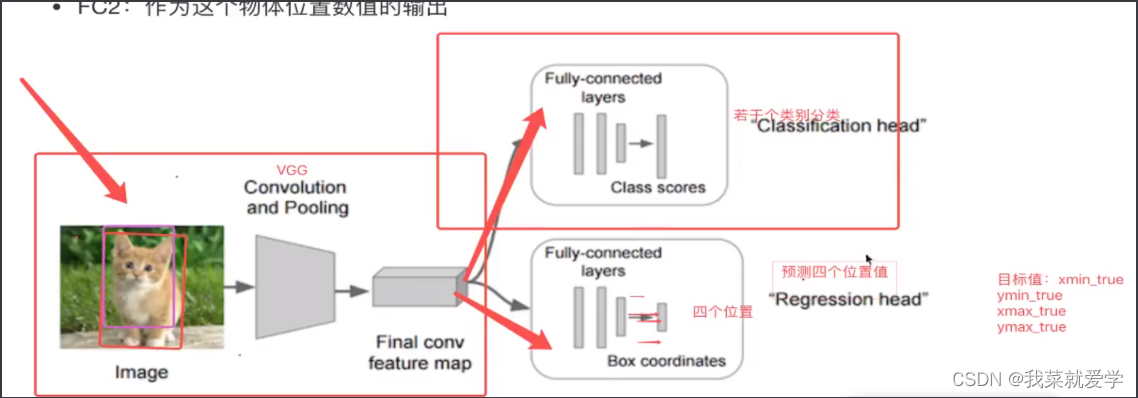
2.2 目标检测-R-CNN模型
说明:不使用暴力的方法,而是选用候选区域方法。
步骤(以AlexNet网络为准):
- 对于一张图片,找出默认2000个候选区域,每个候选区域都resize成固定大小
- 2000个候选区域做大小变换,输入AlexNet当中,得到特征向量。[2000,4096]->4096全连接层
- 经过20个类别的SVM分类器,对于2000个候选区域做判断,预测出候选区域中所含物体的属于每个类的概率值,得到[2000,20]得分矩阵。
- 对于2000个候选区域做NMS,取出不好的、重叠度高的一些候选区域,得到剩下分数高,结果好的框
- 训练了一个边界框回归模型,修正候选框bbox(bbox的回顾微调)
2.2.1 候选区域(ROI)
选择性搜索:首先将每个像素作为一组。然后计算每一组的纹理,并将两个最接近的组结合起来。如下图所示:
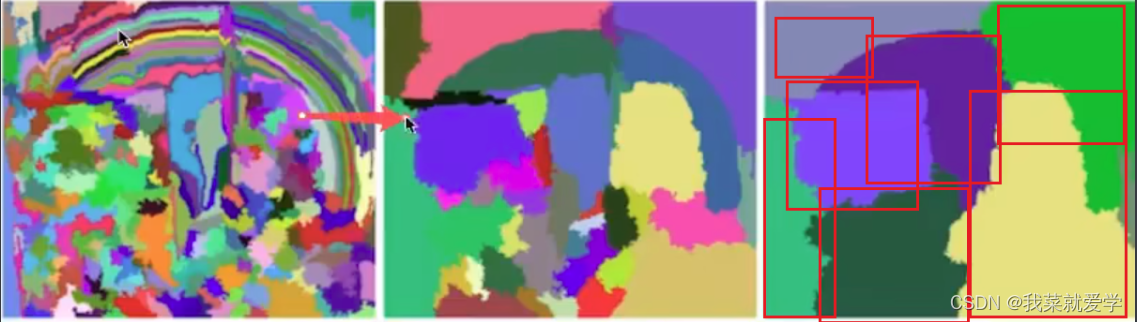
得出的每一个候选框再做图像识别处理。selectiveSearch 在一张图片上提取约2000个候选区域,但是长宽不固定,不能直接输入alexNet。需要对这些候选区域做大小变换。
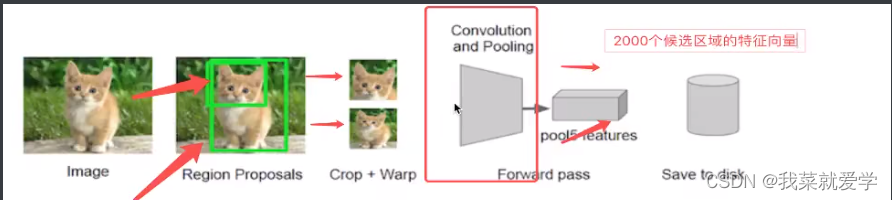
2.2.2 CNN网络提取特征
在候选区域的基础上提取更高级、更抽象的特征,这些高级特征是作为下一步的分类器、回归的输入数据。提取的特征会保存在磁盘(保存磁盘会处理比较慢)上,便于SVM分类。
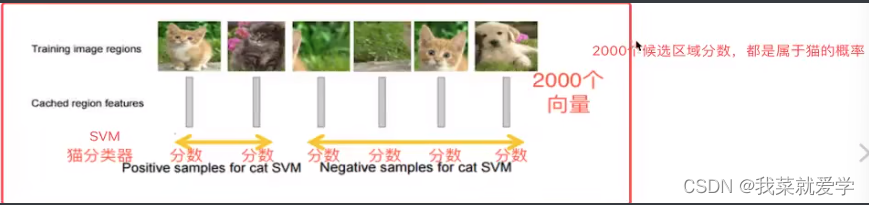
2.2.3 特征向量训练分类器SVM
- 假设一张图片的2000候选区域,提取出来就是2000 x 4098特征向量。
- R-CNN选用SVM进行分类,假设检测20个类别,就会提供20个不同分类的SVM分类器。每个分类器都会对2000个候选区域的特征向量 分别判断一次,得出[2000,20]个得分矩阵。

2.2.4 非极大抑制(NMS)
1)目的
筛选候选区域,目标是一个物体只保留一个最优的框,来抑制哪些冗余的候选框。思想是搜素局部最大值。
2)迭代过程
-
对于所有的2000个候选区域得分进行概率筛选,假设小于0.5的抛出
-
剩余的候选框
-
假设图片真实物体的个数为2(N)个,筛选之后候选框为5 (p ),这样计算N中每个物体位置与所有P的交并比IoU计算,得到P中每个候选框对应IoU最高的一个。
-
如下图所示:每个边框都有他的概率,我们选出概率最高的边框进行高亮显示,然后NMS对剩下的矩形进行逐一扫描对比,所有跟这个高亮边框有很高的的交并比(下面解释),高度重叠的其他预测框都会被抑制。比如右边那个车辆,我们得到0.9的高亮框,因为0.6和0.7的两个高亮框跟0.9的这个IOU最高,因此我们要一直0.6和0.7的这两个高亮框使其变暗。左边汽车的处理方法同。然后经过NMS的处理,我们可以得到如下图所示的效果,即每个车辆身上只有一个预测框。

-
3)IoU的理解
说明:两个区域的重叠程度overlap:候选区域和标定区域的IoU值。值区间[0,1]。然后设定阈值,阈值用来删除重叠较大的边界框

4)非极大值抑制的流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积,计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
2.2.5 修正候选区域
让候选框标注更准确,修正原理的位置。回归操作 用于修正筛选后的候选区域,使之回归ground-truth,默认认为这两个框是线性关系。根据下图:得到的候选区域跟参数重新计算一个预测值,然后和真实值计算得到损失函数,不断训练优化。

2.3 检测的评价指标
2.3.1 平均精确率-map :类别考虑
训练样本标记:候选框标记
- 每个ground-truth box有着最高的IoU的anchor标记为正样本
- 剩下的anchors与任何ground-truth box的IoU大于0.7为正样本,IoU小于0.3为负样本
定义:
mAP = 所有类别的AP之和/类别的总个数:AP1+AP2+…+AP20=mAP
方法步骤:(对于每个类别计算AP[AUC]的值)
- 对于猫类别:候选框预测是猫类别的概率做一个排序,得到候选框排序列表(8个)
- 对于猫当中候选排序列表(8个)进行AUC计算
- 最终得到20个类别,20个AP相加求平均
总结
缺点:
- 训练阶段多:步骤繁琐:微调网络+训练SVM+训练边框回归器
- 训练耗时:占用磁盘空间大:5000张图片产生几百G的特征文件
- 处理速度慢:vgg16模型处理一张图片花费17 s
- 图像形状变化:候选区域要经过crop/warp进行固定大小,无法保证图片不变形
3 改进 - SPPNet
说明:SPP-Net是一种可以不用考虑图像大小,输出图像固定长度网络结构,并且可以做到在图像变形情况下表现稳定。
3.1 提出SPP层,减少卷积计算
说明:SPPNet把全图塞给CNN得到全图的feature map;让SS(选择性搜索)得到候选区域直接映射特征向量中对应的位置;映射过来的特征向量,经过SPP层(空间金字塔变换层),输出固定大小的候选区域特征向量。

3.2 映射
说明:原始图片经过CNN变成feature map,原始图片通过选择性搜索(SS)得到候选区域。映射过程如下:假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,转换关系如下:
- 左上角的点:x’=[x/S]+1
- 左上角的点:x’=[x/S]-1
- S就是CNN中所有的strides的乘积,包含池化、卷积的步长。

3.3 spatial pyramid pooling(SSP)
说明:通过spatial pyramid pooling将特征图转换成固定大小的特征向量。补充:卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系,只是对不同大小的图片卷积出不同大小的特征图,但是全连接层的参数就和输入图像大小有关,因为它要把输入的所有像素点连接起来,需要指定输入层神经元个数和输出层神经元个数,所以需要规定输入的feature的大小。
示例:假设输入是224 x 224的图像,对于conv出来之后输出是13 x 13 x 256,其中某个映射的候选框假设为12 * 10 *256.
- SPP网络层会把每一个候选区域(相近像素结合的区域)分成 1*1 、2 * 2、4 * 4三张子图。对于每个子图的每个区域分别做最大池化,得出的特征再连接到一起就是(16+4+1) x 256 = 5376结果。接着给全连接层做进一步处理。也就是说如下黑色图片代表卷积之后的特征图,然后利用上面的分块把图片分成16+4+1=21种不同的块。对于这21种不同的块,每块用最大池化提取一个特征,也就是取每个块的最大值,最后得到21维的向量。

缺点:
- 训练依旧很慢,特征需要写入磁盘
- 依旧分阶段训练网络,网络之间不统一训练。
- 接下来,Fast R-CNN ,提出RoI pooling,然后整合整个模型,把CNN、Rolpooing、分类器、bbox回归几个模块整合在一起
Fast R-CNN 作为端到端网络的开始,整体优化目标函数。因为之前特征提取CNN的训练和SVM分类器的训练在时间上是先后顺序,两者的训练方式独立。
4 Fast R-CNN
步骤:
- 首先:将整个图片输入到一个基础卷积网络,得到整张图的feature map
- 将选择性搜索算法的结果RoI映射到feature map中
- RoI pooling layer提取一个固定长度的特征向量,每个特征会输入到一系列全连接层,得到一个RoI特征向量(每一个候选区域做同样操作)
- 传统softmax层进行分类,输出类别有k个类别加上背景类(不使用SVM了,不需要磁盘)
- bounding box regressor

4.1 RoI pooling
说明:为了减少计算时间并且得出固定长度的向量,使用一种4 x 4 =16空间的盒子。其他的跟上面SPP差不多。
4.2 多任务损失 - Multi-task loss
两个loss损失函数相加做反向梯度运算:
- 对于分类loss:是一个N+1路的softmax输出,其中N是类别的个数,1是背景,使用交叉熵损失。
- 对于回归loss:候选区域的位置,是一个4 * N路输出的regressor,也就是说对于每个类别都会训练一个单独的regressor,使用平均绝对误差(MAE)损失即L1损失。
4.3 R-CNN 、SPPNet、Fast R-CNN 效果对比

5 Faster R-CNN
参考大佬链接
5.1 整体架构
- conv layers:即特征提取网络,用于提取特征。通过一组conv+relu+pooling层来提取图像的feature maps,用于后续的RPN层和取proposal。
- RPN(Region Proposal Network):即区域候选网络,该网络替代了之前RCNN版本的Selective Search(SS选择性搜索区域),用于生成候选框。这里任务有两部分,一个是分类:判断所有预设anchor是属于positive还是negative(anchor内是否有目标,二分类,也就是上面提到的跟IoU的阈值对比,大于阈值为正样本,否则为负样本);还有一个bounding box regression:修正anchors得到较为准确的proposals。因此,RPN网络相当于提前做了一部分检测,即判断是否有目标(具体什么类别这里不判),以及修正anchor使框的更准一些。
- RoI Pooling:即兴趣域池化(SPP net中的空间金字塔池化),用于收集RPN生成的proposals(每个框的坐标),并从(1)中的feature maps中提取出来(从对应位置扣出来),生成proposals feature maps送入后续全连接层继续做分类(具体是哪一类别)和回归。
- Classification and Regression:利用proposals feature maps计算出具体类别,同时再做一次bounding box regression获得检测框最终的精确位置。

5.2 RPN
相对于Fast-R-CNN,该网络模型多了一个RPN层。

上层:主要是用于网络检测,一共18维(作者给的默认anchors=9,然后上层网络判断目标是否是背景,置信度多少即29=18),也就是anchors获得positive和negative分类。
下层:主要用于回归分析,调节参数,也是中心坐标(x,y)还有到边缘的宽和高的偏移量,也就是49=36维。
Proposal:负责综合positive anchors和对应的bbox偏移量获取的proposals。同时剔除太小和超出边界的proposal
5.3 anchosr生成的数目
论文中介绍,base_anchors=[0,0,15,15]生成9个anchors坐标如下:负数坐标会被舍弃
[[-84.,-40.,99.,55.]
[-176.,-88.,191,103.]
[-360.,-184.,375.,199.]
[-56.,-56.,77.,77.]
[-120.,-120.,135.,135.]
[-120.,-120.,135.,135.]
[-120.,-120.,135.,135.]
[-120.,-120.,135.,135.]
[-120.,-120.,135.,135.]]
那么原图输入是800 x 600,VGG下采样是16倍,feature map每个点 设置9个anchors,则一共有(800/16)x (600/16) x 9=17100

5.4 经过Proposal层
- 生成anchors,对所有的anchors做bbox层回归
- 按照输入的positive softmax scores 由大到小排序anchors,提取前N个anchors,即提取修正位置之后的positive anchors
- 限定超出图像边界的positive anchors,防止下一层的roi pooling时超出图像边界
- 剔除尺寸非常小的positive anchors
- 对剩下的positive anchors进行NMS
- 最后留下大约2000个anchors,然后提取前N个box进行下一层
5.5 ROI Pooling
- 输入的是上一层产生的特征图(300个region proposal box)
- 遍历每一个region proposal,将其坐标值缩小16倍,这样原图(1000600)基础上产生的region proposal映射到6040的特征图上,在feature map上确定一个区域。
- 在feature map上确定的区域,然后将这个区域划分77,即49个相同大小的区域,对于每个区域使用maxpooling方式从中选取最大的像素点作为输出,这样就生成77的feature map
- 300个遍历完之后,会生成很多feature map作为下一层全连接层的输入。
5.6 全连接层
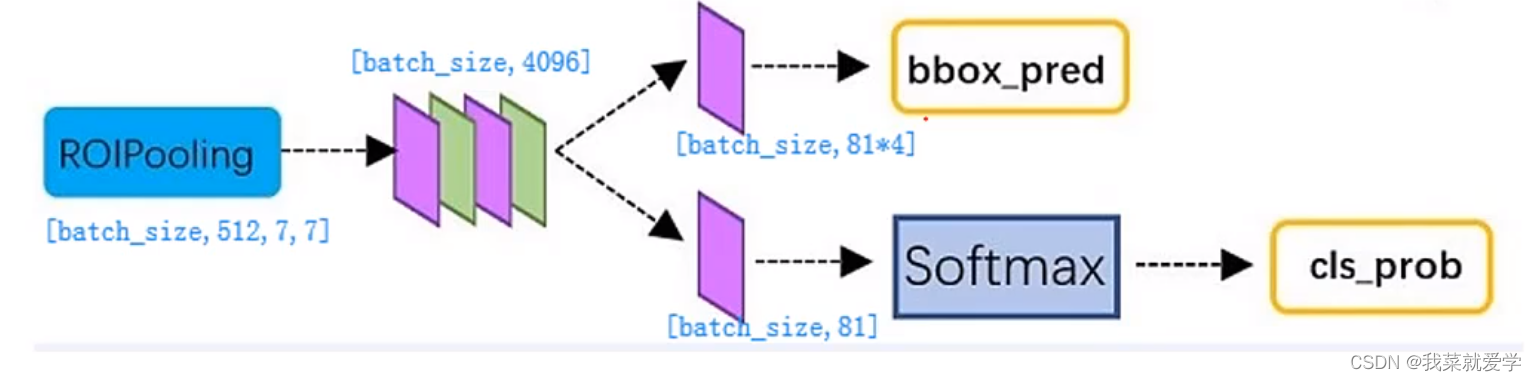
- 通过全连接和softmax对region proposal进行具体类别的分类
- 再次对region proposal 进行bbox,获取高精度的box,也是最终的坐标。
6 YOLO
6.1 结构
说明:一个网络搞定一切,GooglNet + 4个卷积 +2个全连接层
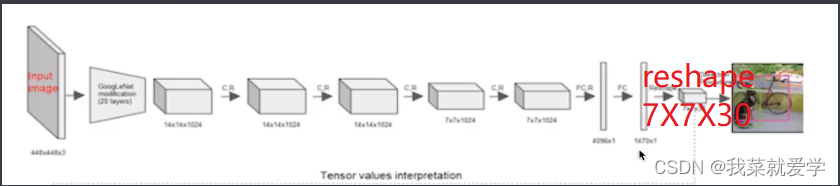
6.2 流程处理
1)原始图片resize到448 x 448的大小,经过前面卷积网络之后,将图片输出成一个7 x 7 x 30结构
2)将图片分成7 x 7 的单元格,这里Up主用3 x 3 的图代替
7*7=49个像素值,看成49个单元格。
- 每个单元格负者一个 预测物体类别,并且直接预测物体的概率值
- 每个单元格预测两个(默认)bbox位置,两个bbox置信度 772=98.30=(4+1+4+1+20)表示4个坐标信息,1个置信度
- 一个bbox : xmin ,ymin,xmax,ymax,confidence 4+1 共两个bbox
- 20:代表20个类别
- confidence score:如果grid cell类名木有object,confidence就是0;如果有,则confidence score 就等于预测的box和ground truth的IoU乘积。

3)然后对于每一个网格预测两个bbox

4)进行NMS筛选,筛选概率以及IoU

我想说:
上面可能介绍的许多技术或者算法都已经过时了,当时也是为了搞清楚一张图片是如何做到多目标的检测的。博客中可能也有很多错误或者我理解错误的地方,感谢指正。博客后面部分都是大论文,我只是过一遍处理流程,具体了解想通过代码复现应该理解更深刻吧。创造不易,一键三连~~