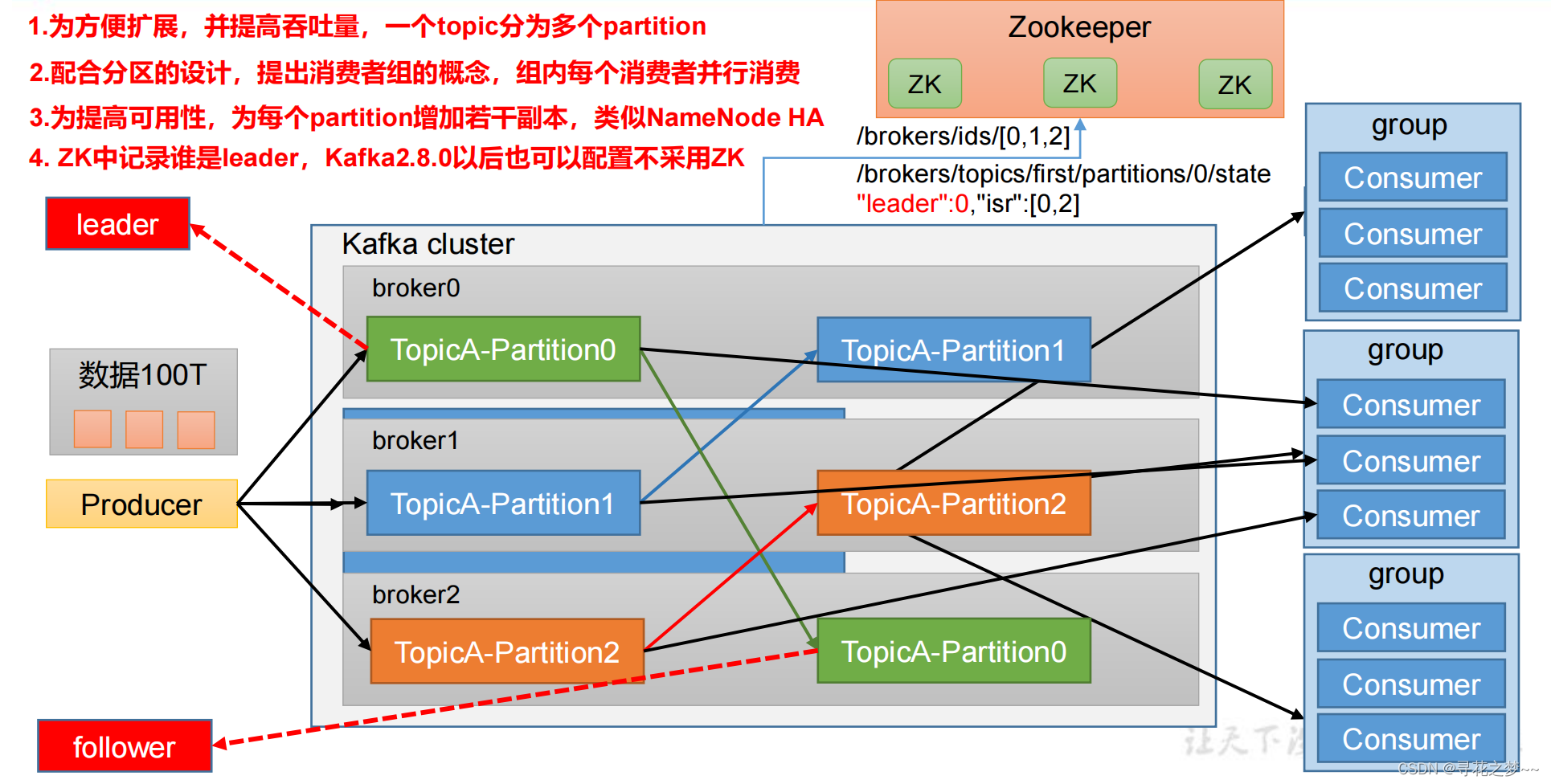
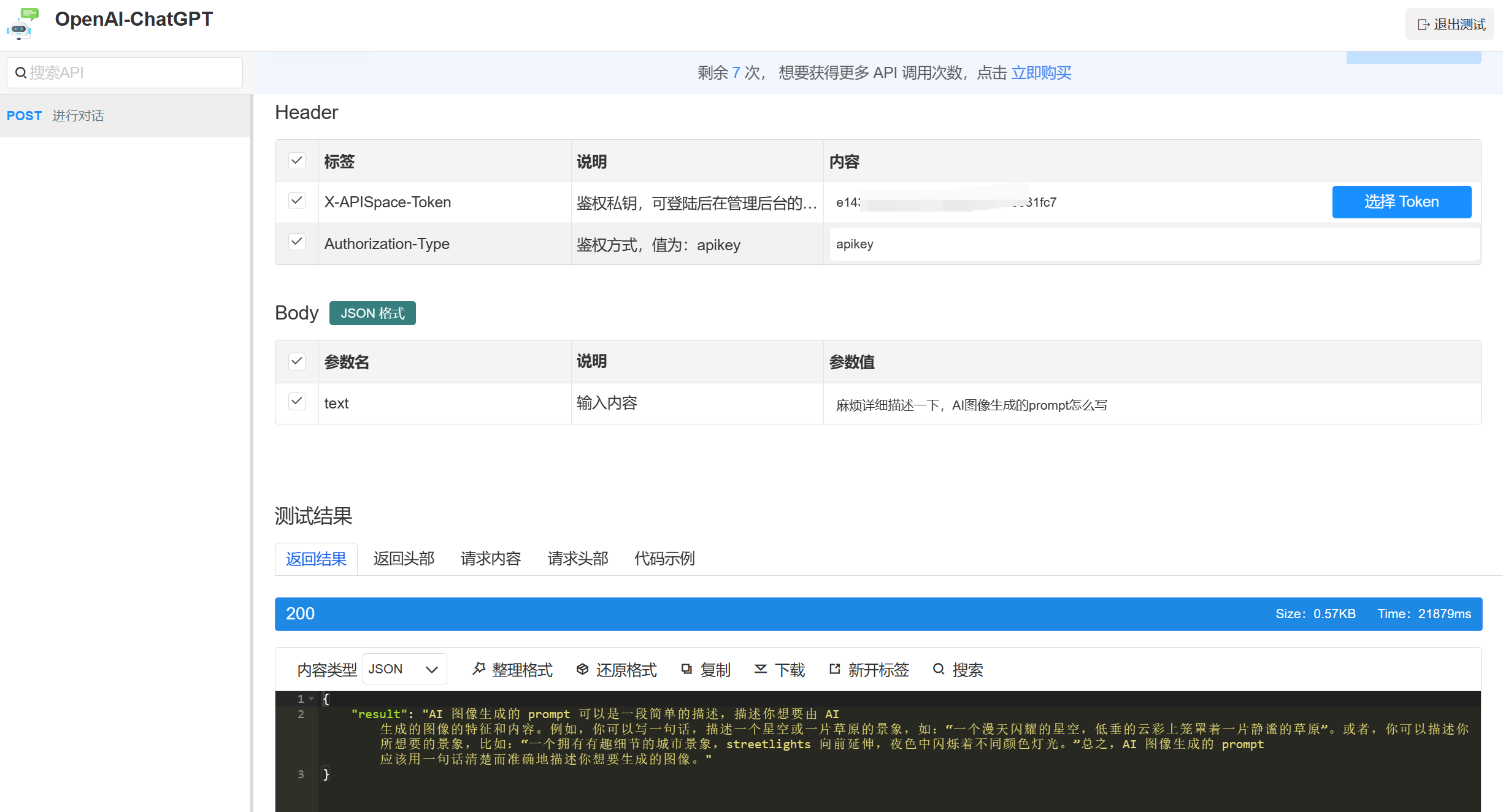
Kafka架构
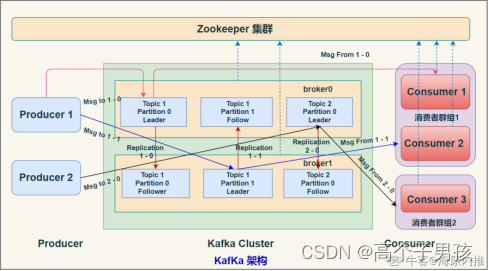
Kafak 总体架构图中包含多个概念:
(1)ZooKeeper:Zookeeper负责保存broker集群元数据,并对控制器进行选举等操作。
(2)Producer: 生产者负责创建消息,将消息发送到 Broker。
(3)Broker: 一个独立的Kafka服务器被称作broker,broker 负责接收来自生产者的消息,为消息设置偏移量,并将消息存储在磁盘。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
(4)Consumer: 消费者负责从Broker订阅并消费消息。
(5)Consumer Group:Consumer Group为消费者组,一个消费者组可以包含一个或多个Consumer。
使用 多分区 + 多消费者 方式可以极大 提高数据下游的处理速度,同一消费者组中的消费者不会重复消费消息,同样的,不同消费组中的消费者消费消息时互不影响。Kafka 就是通过消费者组的方式来实现消息 P2P 模式和广播模式。
(6)Topic: Kafka 中的消息 以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。
(7)Partition: 一个 Topic 可以细分为多个分区,每个分区只属于单个主题。同一个主题下不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的 日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的 偏移量(offset)。
(8)Offset: offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka保证的是分区有序性而不是主题有序性。
(9)Replication: 副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有主副本对外提供读写服务,当主副本所在 broker 崩溃或发生网络异常,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副本对外提供读写服务。
(10)Record: 实际写入 Kafka 中并可以被读取的消息记录。每个 record 包含了key、value和timestamp。
(11)Leader: 每个分区多个副本的 "主" leader,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
(12)follower: 每个分区多个副本中的"从" follower,实时从 Leader 中同步数据,保持和 leader 数据的同步。Leader 发生故障时,某个 follow 会成为新的 leader。