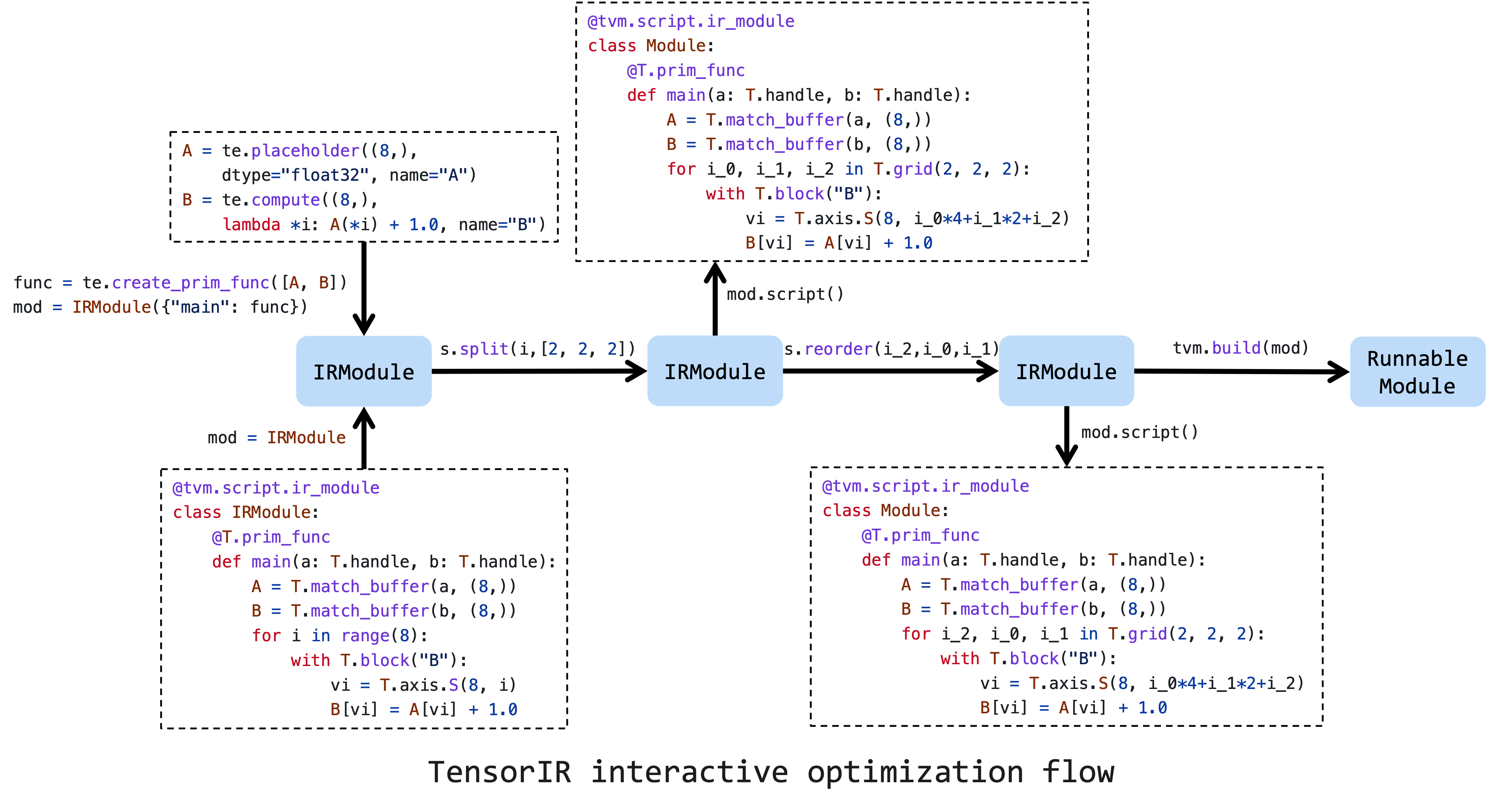
文章目录
- 什么是 ClickHouse,它的特点是什么?
- ClickHouse的数据存储方式是什么,它与传统的行式存储有什么区别?
- ClickHouse 引擎
- ClickHouse的数据模型是什么,它与传统的关系型数据库的数据模型有什么区别?
- ClickHouse的查询语言是什么,它与传统的SQL语言有什么区别?
- ClickHouse支持哪些数据类型,它们的特点是什么?
- ClickHouse的查询性能如何,如何评估查询性能?
- ClickHouse如何处理数据冗余和数据压缩?
- ClickHouse的索引类型是什么,如何使用索引来提高查询性能?
- ClickHouse支持哪些分布式部署方案,如何进行分布式查询?
- ClickHouse的优缺点是什么,它适用于哪些场景?
- ClickHouse的数据写入和数据删除是如何实现的?
- ClickHouse如何处理大数据量和高并发情况下的查询性能问题?
- ClickHouse的内存管理和垃圾回收机制是怎样的?
- ClickHouse如何处理时序数据和实时数据?
- ClickHouse支持哪些数据导入和导出方式?
- ClickHouse的安全机制是怎样的,如何保证数据安全?
- ClickHouse支持分布式计算引擎吗?是如何进行的?
什么是 ClickHouse,它的特点是什么?
ClickHouse是一款用于大数据分析的 OLAP 列式存储数据库管理系统,最初由Yandex公司开发,后来成为了一个开源项目,可以在 GitHub 上进行访问和使用。
ClickHouse特点如下:
-
高性能
-
分布式架构
-
支持 SQL 查询语言,减少开发人员学习成本。
-
支持多种数据类型,拥有灵活的数据模型。
-
支持多种数据压缩算法。
-
开源和免费。
总之,ClickHouse 是一款高性能、分布式、灵活和开源的列式存储数据库,特别适用于大数据分析、数据仓库和时序数据处理等场景。
ClickHouse的数据存储方式是什么,它与传统的行式存储有什么区别?
ClickHouse 是列式存储的数据库。在传统的行式存储中,数据按照行的方式存储,即将每个记录的各个字段按顺序存储在一起,每行数据占用的存储空间相对较大。而列式存储是将每列的数据存储在一起,可以单独进行压缩与解码,占用的存储空间更少,查询效率更高。
ClickHouse 引擎
| 引擎名称 | 说明 |
|---|---|
| MergeTree | 适用于查询性能要求较高的数据表,如:时间序列数据。它有一个优化排序和合并的技术,从而提高数据查询速度。 |
| CollapsingMergeTree | 与 MergeTree 相似,但是在累加数据值方面更有优势。它可以在查询中合并多个数据值。 |
| SummingMergeTree | 与 CollapsingMergeTree 相似,但它专门用于对数值累加。 |
| ReplacingMergeTree | 适用于在数据表中替换某些数据值。如果数据表中存在与新数据重复的键,则它将替换该数据。 |
| GraphiteMergeTree | 适用于操作时间序列数据,如:Graphite 应用。它对时间序列数据查询具有较高的性能。 |
| VersionedCollapsingMergeTree | 适用于数据版本控制,并且可以在多个版本之间查询数据。 |
| Memory | 将数据存储在 RAM 中,因此数据查询速度比磁盘存储快得多。不过,由于它是在内存中存储数据,因此它通常不适用于大数据量的数据表。 |
| Buffer | 缓存引擎,用于存储缓存表。适用于中间结果,可以在内存和磁盘之间快速切换 相对于内存引擎的读写速度较慢,数据不能永久保存。 |
ClickHouse的数据模型是什么,它与传统的关系型数据库的数据模型有什么区别?
ClickHouse的数据模型是基于表的,与创建表时指定的数据存储类型和存储引擎有关,支持多种数据类型。
相较于传统的关系型数据库的数据模型,ClickHouse的数据模型是列式存储的,每个列可以单独进行压缩与解码,存储空间更少,查询效率高。
ClickHouse的查询语言是什么,它与传统的SQL语言有什么区别?
ClickHouse的查询语言是ClickHouse SQL,它与传统的SQL具有很高的兼容性,但也有一些专门为ClickHouse设计的特殊语法和函数,以便更好地支持列式存储和分布式计算。
其特点如下:
- 1.支持多种查询语句
- 2.优化查询性能
- 3.支持高级数据类型
- 4.支持自定义函数和聚合函数
- 5.支持多种存储引擎
ClickHouse支持哪些数据类型,它们的特点是什么?
ClickHouse支持多种数据类型,包括基本数据类型、复合数据类型和几何数据类型。

灵活性高,便于使用,性能也高。
ClickHouse的查询性能如何,如何评估查询性能?
ClickHouse是一种高性能的列式存储数据库,因此它在查询性能方面具有很高的优势。通过基准测试、Query profiling(ClickHouse内置工具)、Explain语句、索引和硬件优化等方法,可以评估和优化ClickHouse的查询性能。
ClickHouse如何处理数据冗余和数据压缩?
ClickHouse使用列式存储、数据压缩、布隆过滤器、稠密索引和数据分区等技术来处理数据冗余和数据压缩,以提高存储效率和查询性能。
ClickHouse的索引类型是什么,如何使用索引来提高查询性能?
ClickHouse支持以下三种索引类型:
-
稠密索引(Dense Index):稠密索引是一种基于跳跃表的索引结构,用于在有序列上进行范围查询。在ClickHouse中,稠密索引使用较少的空间来存储数据,并且可以加快查询速度。
-
稀疏索引(Sparse Index):稀疏索引是一种基于哈希表的索引结构,用于在无序列上进行查询。稀疏索引只在查询时创建,因此可以减少索引的空间占用。
-
索引光标(Index Cursor):索引光标是一种用于加速聚合查询的技术。它允许ClickHouse在数据分片和节点之间进行快速分布式聚合查询。
使用索引来提高查询性能需要注意以下几点:
-
索引字段的选择:选择合适的索引字段是提高查询性能的关键。应该选择那些经常被查询的字段,同时避免选择过多的索引字段,因为索引字段过多会增加索引的存储空间和维护成本。
-
索引覆盖(Covering Index):使用索引覆盖可以避免在查询中使用表格数据,从而提高查询性能。索引覆盖是指索引包含所有查询需要的数据,而不必回到表格数据中获取数据。
-
索引的创建和维护:创建索引时需要考虑索引的类型和大小,以及索引的维护成本。ClickHouse支持在线创建和删除索引,同时还提供了自动化索引维护的功能。
-
查询优化:除了使用索引之外,还可以使用查询优化技术来提高查询性能。例如,使用合适的查询语句、减少不必要的字段、避免使用多余的函数等。
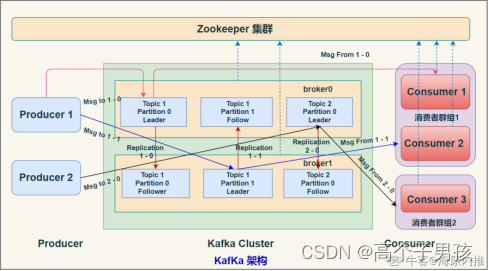
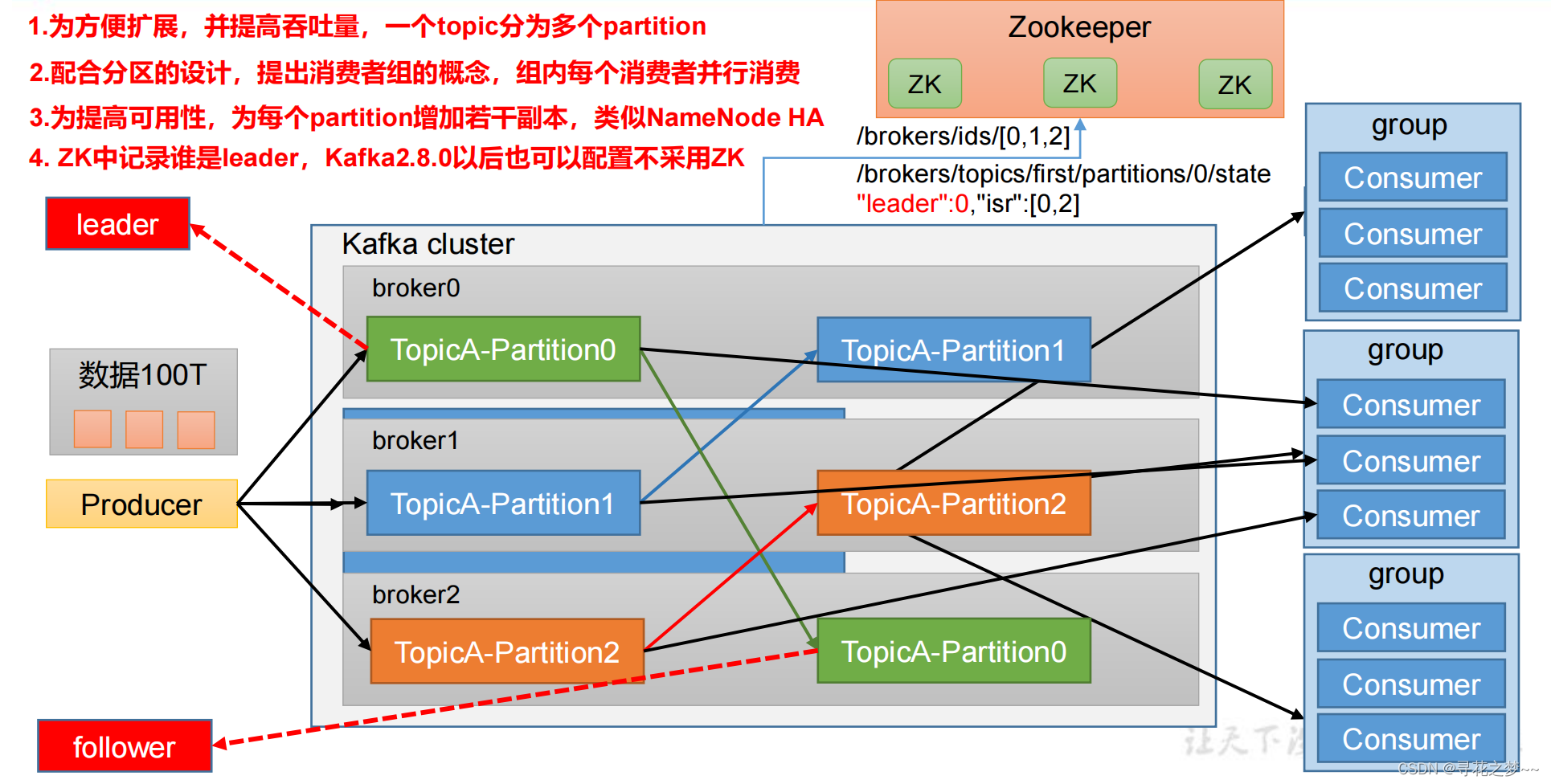
ClickHouse支持哪些分布式部署方案,如何进行分布式查询?
ClickHouse支持以下几种分布式部署方案:
-
分片复制部署:将数据划分为多个分片,每个分片都有多个副本,每个副本都可以读写数据。在这种部署方案中,每个节点都可以执行查询,但只有主副本可以执行写操作。当主副本出现故障时,会自动切换到备副本。
-
分片无复制部署:将数据划分为多个分片,每个分片只有一个副本。在这种部署方案中,每个节点都可以执行查询和写操作。
-
复制无分片部署:所有数据都复制到每个节点上,每个节点都可以执行查询和写操作。这种部署方案适合小型集群和低并发查询。
分布式查询可以通过以下两种方式进行:
-
基于分布式查询引擎:ClickHouse提供了分布式查询引擎,允许用户在多个节点上并行执行查询,并将结果汇总到一个节点上。分布式查询引擎可以处理大量数据,并且可以根据查询的特点自动调整查询计划,提高查询性能。
-
基于分布式存储引擎:ClickHouse支持分布式存储引擎,可以将数据分布到多个节点上,实现数据的并行读取和写入。在这种情况下,查询可以在多个节点上执行,并通过网络传输数据进行计算。这种方法适用于需要在多个节点上分析大量数据的场景。
ClickHouse的优缺点是什么,它适用于哪些场景?
优点:
- 采用列式存储,节省空间成本。
- 支持向量化引擎,查询速度快,适合在线查询,性能高。
- 与 SQL 语言兼容性好,减少开发人员学习成本。
- 支持多核并发处理与分布式处理。
- 灵活的数据模型。
缺点:
- 不支持事务。
- 不适合高频率。
- 不支持复杂的联表查询。
- 硬件配置高。
ClickHouse的数据写入和数据删除是如何实现的?
在往 ClickHouse 中写入数据时,它会先将数据写入的内存表中,当内存表达到一定的大小后,将内存表中的数据写入新的数据块中,根据数据的时间戳确定数据块的位置。当数据块达到一定大小后,会进行归并排序,存储到更大的数据块中,形成一个更大的分区,最终进行长期的存储。
ClickHouse 使用 alter table 关键字进行数据删除,它是一种逻辑删除。通过添加一个标记字段来区分数据是否被删除,并不会删除真正的数据,只有在分片时才会真正的清理。
ClickHouse如何处理大数据量和高并发情况下的查询性能问题?
ClickHouse 通过列式存储、数据分片、原子操作和类事务、预聚合、集成缓存以及异步处理等技术来处理大数据量和高并发情况下的查询性能问题。
ClickHouse的内存管理和垃圾回收机制是怎样的?
ClickHouse 采用自己实现的内存池来管理内存,这样可以快速地进行内存分配和回收。ClickHouse 也可以设置内存限制,以确保查询过程中不会耗尽系统内存,一旦达到内存限制,ClickHouse 将会自动开始垃圾回收,以释放一些内存。
ClickHouse 使用的是一种自适应的垃圾回收机制,当内存使用达到限制时会自动进行回收,选择尽可能少的数据进行回收,同时避免产生大量的垃圾数据。
ClickHouse如何处理时序数据和实时数据?
ClickHouse 支持专门的时序数据库引擎 —— MergeTree 引擎,该引擎是针对时间序列数据设计的,能够快速地处理基于时间的查询和聚合操作。
ClickHouse 提供了 Kafka 引擎,能够直接消费 Kafka 消息队列中的数据,并将其存储到 ClickHouse 中。还支持对实时数据进行预处理和聚合操作,从而实现实时数据分析和监控。
ClickHouse支持哪些数据导入和导出方式?
支持csv、json、orc、parquet、MySQL等关系型数据库、NoSQL,还支持从消息队列和存储系统中导入和导出数据,例如:Kafka、Redis等
ClickHouse的安全机制是怎样的,如何保证数据安全?
- 用户认证和授权
- 数据加密与传输加密
- 防止 SQL 注入
- 安全审计
- 安全更新
通过上述安全机制,ClickHouse 能够保证数据在存储、传输和使用的过程中的安全性和完整性,为用户提供安全可靠的数据存储和分析服务。同时,用户也需要根据实际需求,合理设置用户角色和访问权限,以确保数据的安全性。
ClickHouse支持分布式计算引擎吗?是如何进行的?
ClickHouse 并不直接支持其他分布式计算引擎,例如 Spark、Flink 等。不过,ClickHouse 支持通过多种方式将数据导出到计算引擎中进行处理,例如:JDBC/ODBC接口、数据导出工具等。