作为个人记录,后续再填坑
a对p是1对多 ,p对llup 1对多
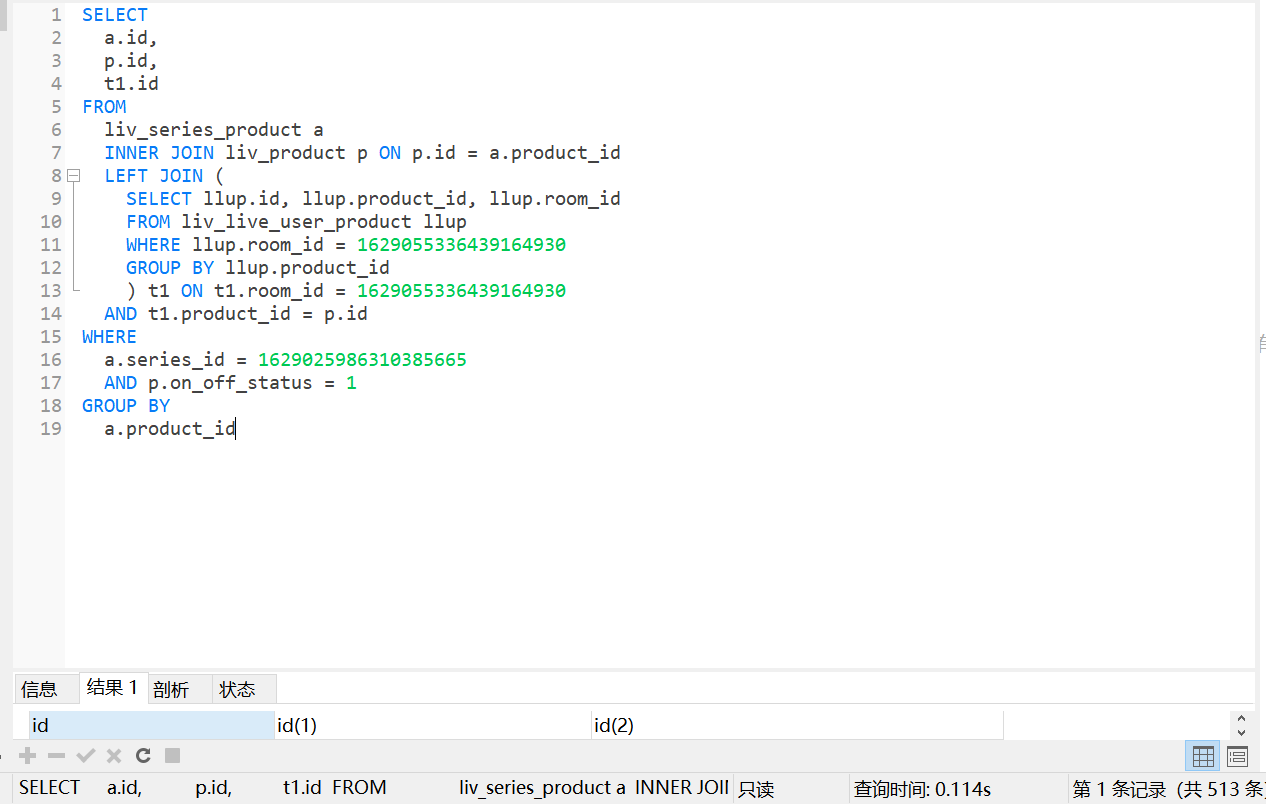
SELECT
a.id,
p.id,
t1.id
FROM
liv_series_product a
INNER JOIN liv_product p ON p.id = a.product_id
LEFT JOIN (
SELECT llup.id, llup.product_id, llup.room_id
FROM liv_live_user_product llup
WHERE llup.room_id = 1629055336439164930
) t1 ON t1.room_id = 1629055336439164930
AND t1.product_id = p.id
WHERE
a.series_id = 1629025986310385665
AND p.on_off_status = 1
GROUP BY
a.product_id0.8秒

加上GROUP BY llup.product_id 后0.1秒
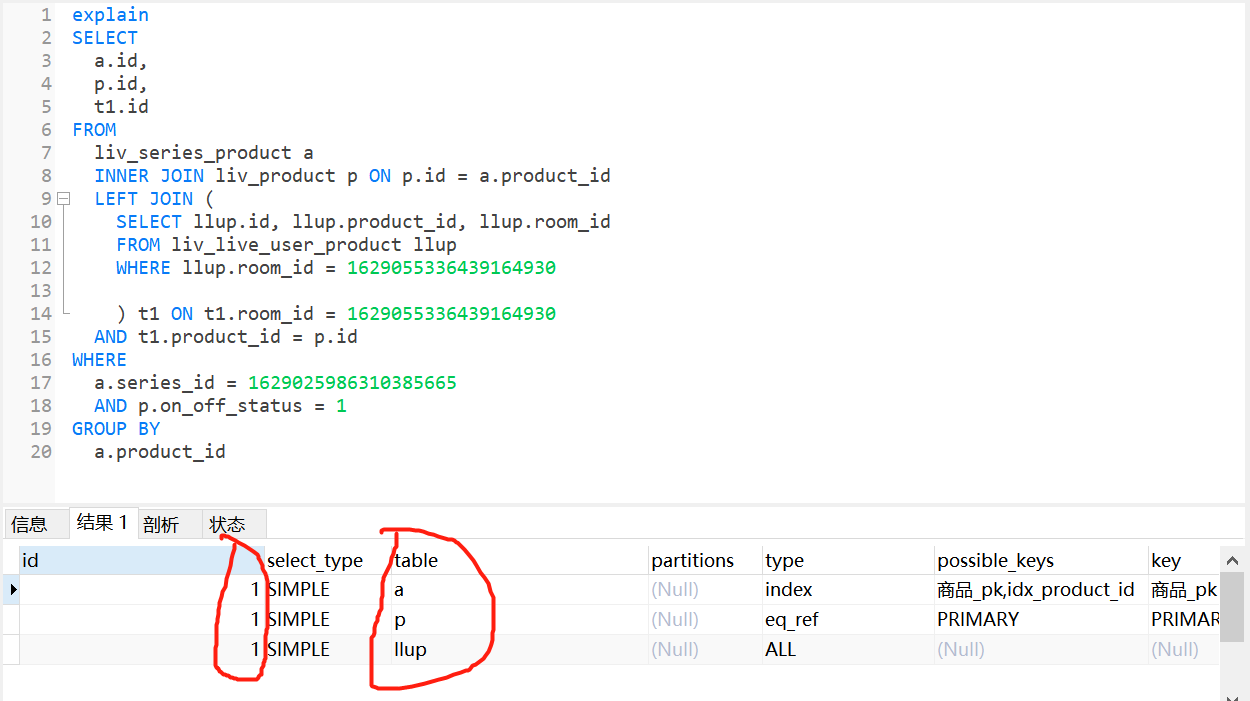
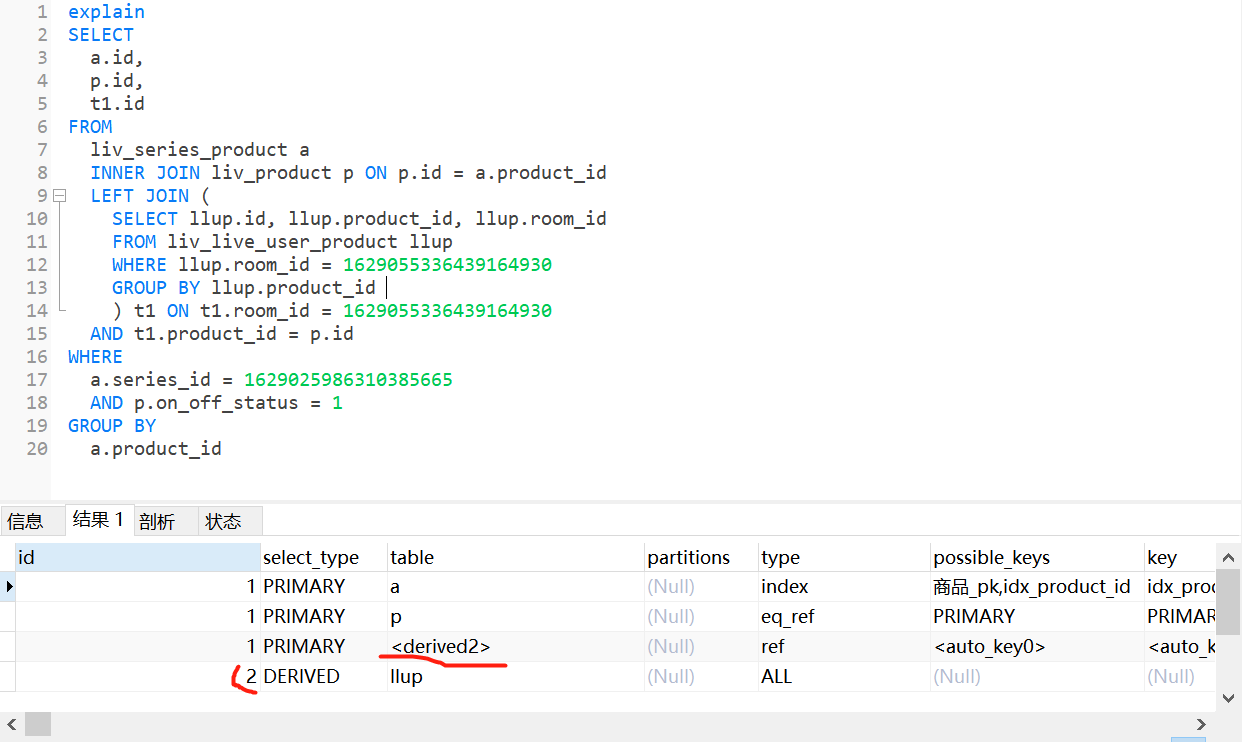
加上grouby 后是生成了一个副表 先执行了llup表。
MySQL8的 Hash Join
explain format = tree 查看,发现加了group by 的没有用上hash join
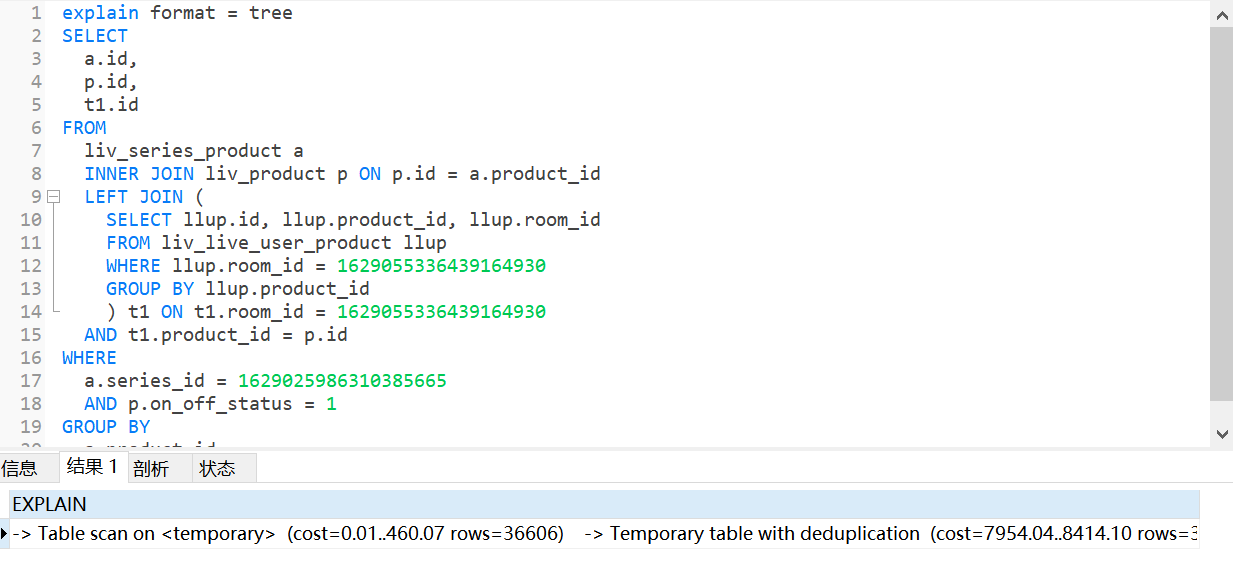
没加group by的 如EXPLAIN下图第三行用上了 hash join,反而sql慢了
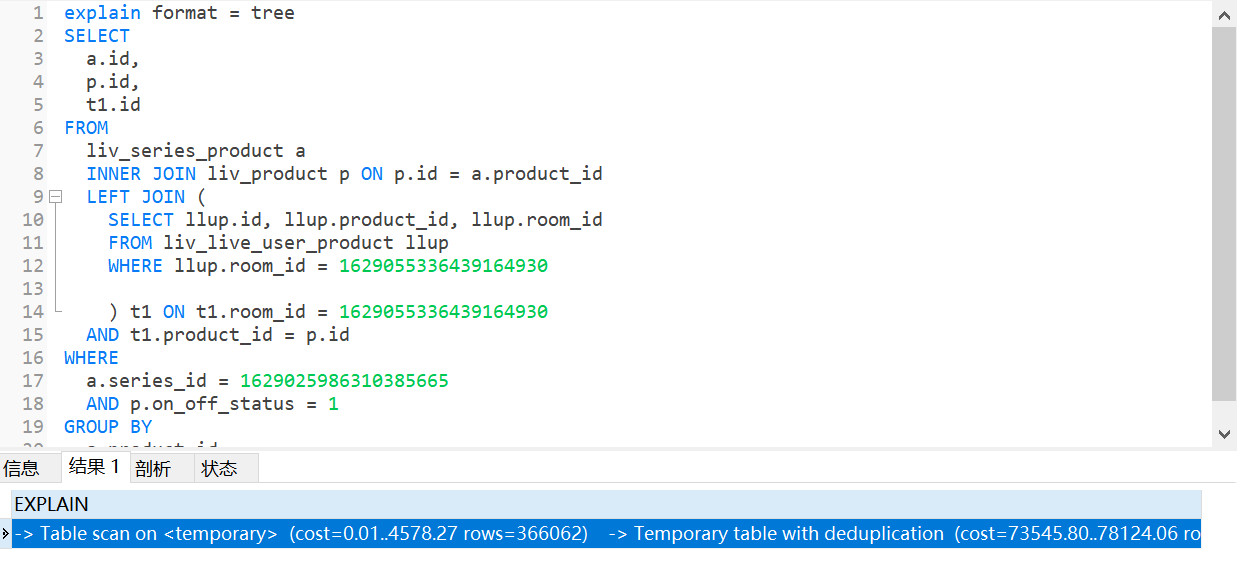
-> Table scan on <temporary> (cost=0.01..4578.27 rows=366062)
-> Temporary table with deduplication (cost=73545.80..78124.06 rows=366062)
-> Left hash join (llup.product_id = a.product_id) (cost=36939.55 rows=366062)
-> Nested loop inner join (cost=551.86 rows=32)
-> Filter: (a.series_id = 1629025986310385665) (cost=327.45 rows=322)
-> Index scan on a using 商品_pk (cost=327.45 rows=3217)
-> Filter: (p.on_off_status = 1) (cost=0.60 rows=0)
-> Single-row index lookup on p using PRIMARY (id=a.product_id) (cost=0.60 rows=1)
-> Hash
-> Filter: (llup.room_id = 1629055336439164930) (cost=44.35 rows=11379)
-> Table scan on llup (cost=44.35 rows=11379)
有索引,不走hash join。
最后的解决办法有两种:
加上group by
llup 以on关联的product_id 加上索引。
参考文章
MySQL 8.0 hash join有重大缺陷?
MySQL8的 Hash Join
MySQL的语句执行顺序
你真的懂使用Group by?