前言
一、pandas是什么?
二、使用步骤
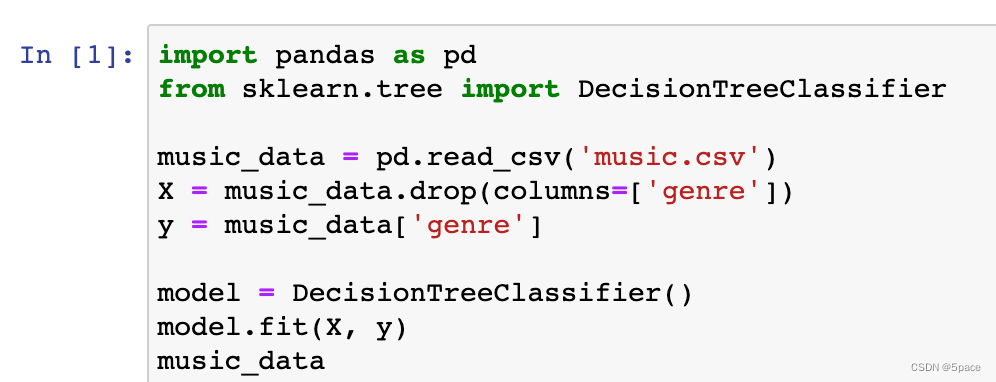
1.引入库
2.处理时间序列数据
3.分组聚合(groupby)
3.1基本方法
3.2具体使用:如图包含三个字段,company、salary、age
总结
Pandas 最最常用函数罗列
Pandas 函数用法示例
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、pandas是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
1.引入库
DataFrame基础操作
df.values # 查看所有元素
df[''].value_counts #统计某列中类的数量,参数:normalize(返回占比)、sort(排序)、
ascending (boolean, default False)(是否升序排列)。。
比如:df['company'].value_counts(normalize=True)
df.head # 查看前五行的数据
df.tail # 查看最后五行的数据
df.index # 查看索引
df.columns # 查看所有列名
df.dtype # 查看字段类型
df.size # 元素总数
df.ndim # 表的维度数
df.shape # 返回表的行数与列数
df.info # DataFrame的详细内容
df.describe # 生成描述性统计汇总,包括均值、max等
df.isna # 判断数据是否为缺失值,是的话返回true
df.isna().any() # 数据量较大时,使用any()查看某一列是否有缺失值
df.dropna # 删掉含有缺失值的数据
df.fillna # 填充数据,主要参数:value(填充的值)、 method(缺失值填充方法)
df.sort_values # 按照某列进行排序,eg.data.sort_values(by='salary') 也可用ascending
DataFrame数据的查看方法
单列数据:df['col1']
单列多行:df['col1'][2:7]
多列多行:df[['col1','col2']][2:7]
多行数据:df[:][2:7] #这里使用df[2:7][:]也能得到同样的效果
loc,iloc的查看方法
# loc[行索引名称或条件,列索引名称]
# iloc[行索引位置,列索引位置]
单列切片:df.loc[:,'col1']
df.iloc[:,3]
多列切片:df.loc[:,['col1','col2']]
df.iloc[:,[1,3]]
按需切片:df.loc[2:5,['col1','col2']]
df.iloc[2:5,[1,3]]
条件切片:df.loc[df['col1']=='245',['col1','col2']]
df.iloc[(df['col1']=='245').values,[1,5]]
删除数据(及时更新)
# 删除某几行数据,inplace为True时在源数据上删除,False时需要新增数据集
df.drop(labels=range(1,11),axis=0,inplace=True)
# 删除某几列数据
df.drop(labels=['col1','col2'],axis=1,inplace=True)
更新
df=df.reset_index(drop=True) #更新索引范围,不更新的话会导致报错keyerror
2.处理时间序列数据
2.1字符串时间转换为标准时间
df['time'] = pd.to_datetime(df['time'])
2.2加减时间
# 使用Timedelta,支持weeks,days,hours,minutes,seconds,但不支持月和年
df['time'] = df['time'] + pd.Timedelta(days=1)
df['time'] = df['time'] - pd.to_datetime('2016-1-1')
# 时间跨度计算:
df['time'].max() - df['time'].min()
3.分组聚合(groupby)
3.1基本方法
df.groupby(by='',axis=0,level=None,as_index=True,sort=True,group_keys=True
,squeeze=False).count()
# by--分组的字段 level--标签所在级别,默认None as_index--聚合标签是否以df形式输出,
默认True,sort--是否对分组依据,分组标签进行排序,默认True group_keys--是否显示分组
标签名称,默认True squeeze--是否对返回数据进行降维,默认False
# 聚合函数有count,head,max,min,median,size,std,sum
3.2具体使用:如图包含三个字段,company、salary、age

group = data.groupby("company")
In [8]: list(group)
Out[8]:
[('A', company salary age
3 A 20 22
6 A 23 33),
('B', company salary age
4 B 10 17
5 B 21 40
8 B 8 30),
('C', company salary age
0 C 43 35
1 C 17 25
2 C 8 30
7 C 49 19)]
总结
Pandas 最最常用函数罗列
## 读写
pd.Series #定义一维标记数组
pd.DataFrame #定义数据框
pd.read_csv #读取逗号分隔符文件
pd.read_excel #读取 excel 表格
pd.to_excel #写入 excel 表格
pd.read_sql #读取 SQL 数据
pd.read_table #读取 table
pd.read_json #读取 json 文件
pd.read_html #读取 html
pd.read_clipboard() #从剪切板读入数据
df.to_csv #写入 csv 文件
df.to_excel #写入 excel 文件
df.to_sql #写入 SQL 表
df.to_json #写入 JSON 文件
df.to_html #写入 HTML 表格
df.to_clipboard() #写入剪切板## 数据展示和统计
df.info() #统计数据信息
df.shape() #统计行数和列数
df.index() #显示索引总数
df.columns() #显示数据框有哪些列
df.count() #显示有多少个记录
df.head(n) #返回前 n 个,默认 5
df.tail(n) #返回后 n 个
df.sample(n) #随机选取 n 行
df.sample(frac = 0.8) #百分比为 0.8 的选取
df.dtypes #查看每一列的数据类型
df.sum() #数据框按列求和
df.cumsum() #数据框累计求和
df.min() #给出每列的最小值
df.max() #给出每列的最大值
df['列名'].idxmin() #获取数据框某一列的最小值
mySeries.idxmin() #获取 Series 的最小值
df['列名'].idxmax() #获取数据框某一列的最大值
mySeries.idxmax() #获取 Series 的最大值
df.describe() #关数据的基本统计信息描述
df.mean() #给出数据框每一列的均值
df.median() #给出数据框每一列的中位数
df.quantile #给出分位数
df.var() #统计每一列的方差
df.std() #统计每一列的标准差
df.cummax() #寻找累计最大值,即已出现中最大的一个
df.cummin() #累计最小值
df['列名'].cumproad() #计算累积连乘
len(df) #统计数据框长度
df.isnull #返回数据框是否包含 null 值
df.corr() #返回列之间的相关系数,以矩阵形式展示
df['列名'].value_counts() #列去重后给每个值计数## 数据选择
mySeries['列名'] #用中括号获取列
df['列名'] #选取指定列
df.列名 #同上
df[n0:n1] #返回 n0 到 n1 行之间的数据框
df.iloc[[m],[n]] #iloc按行号来索引,两层中括号,取第 m 行第 n 列
df.loc[m:n] #loc 按标签来索引,返回索引 m 到 n 的数据框,loc、iloc 主要针对行来说的
df.loc[:,"列1":"列2"] #返回连续列的所有行
df.loc[m:n,"列1":"列2"] #返回连续列的固定行
df['列名'][n] #选取指定列的第 n 行
df[['列1','列2']] #返回多个指定的列## 数据筛选和排序
df[df.列名 < n] #筛选,单中括号用于 bool 值筛选
df.filter(regex = 'code') #过滤器,按正则表达式筛选
df.sort_values #按某一列进行排序
df.sort_index() #按照索引升序排列
df['列名'].unique() #列去重
df['列名'].nunique() #列去重后的计数
df.nlargest(n,'列名') #返回 n 个最大值构成的数据框
df.nsmallest(n,'列名') #返回 n 个最小的数据框
df.rank #给出排名,即为第几名## 数据增加删除修改
df["新列"] = xxx #定义新列
df.rename #给列重命名
df.index.name = "index_name" #设定或者修改索引名称
df.drop #删除行或者列
df.列名 = df.列名.astype('category') #列类型强制转化
df.append #在末尾追加一行
del df['删除的列'] #直接删除一列## 特别的
df.列名.apply #按列的函数操作
pd.melt #将宽数据转化为长数据(拆分拉长),run 一下下面例子就知道什么意思了
pd.merge #两个数据表间的横向连接(内连接,外连接等)
pd.concat #横向或者纵向拼接
Pandas 函数用法示例
mySeries = pd.Series([1,2,3,4], index=['a','b','c','d'])
data = {'Country' : ['Belgium', 'India', 'Brazil' ],
'Capital': ['Brussels', 'New Delhi', 'Brassilia'],
'Population': [1234,1234,1234]}
df = pd.DataFrame(data, columns=['Country','Capital','Population'])pd.DataFrame(np.random.rand(20,5))
df = pd.read_csv('data.csv')
pd.read_excel('filename')
pd.to_excel('filename.xlsx', sheet_name='Sheet1')df.quantile([0.25, 0.75]) # 给出每一列中的25%和75%的分位数
filters = df.Date > '2021-06-1'
df[filters] #选出日期在某个日期之后的所有行df.filter(regex='^L') #选出 L 开头的列
df.sort_values('列名', ascending= False) #按指定列的值大小升序排列
df.rename(columns= {'老列名' : '新列名'}) #修改某个列名
df["新列"] = df.a- df.b #定义一个新的列表示为两个的差
df.columns = map(str.lower(), df.columns) #所有列名变为小写字母
df.columns = map(str.upper(), df.columns) #所有列名变为大写字母
df.drop(columns=['列名']) #删除某一列
df.drop(['列1', '列2'], axis=1) #含义同上,删除两列
mySeries.drop(['a']) #删除 Series 指定值
df.drop([0, 1]) #根据索引删除,双闭区间def fun(x):
return x*3
df.列名.apply(fun) #把某一列乘 3 倍df.列名.apply(lambda x: x*3) #匿名表达式的写法
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},'B': {0: 1, 1: 3, 2: 5}, 'C': {0: 2, 1: 4, 2: 6}})
pd.melt(df, id_vars=['A'], value_vars=['B','C']) #melt的使用new=pd.DataFrame({'name':'lisa', 'gender':'F', 'city':'北京'},index=[1])
df = new
df=df.append(new) #增加一行数据frame = pd.DataFrame({'a':[2.3,-1.7,5,3],'b':[6,2.9,-3.1,8]},index=['one','two','three','four'])
frame.rank(method="min",ascending=False)#对每一列的数据,根据大小给个排名
#merge 表示横向连接
df3 = pd.merge(df1,df2,how='inner',on='股票简称') #on表示连接列,how选择连接方式
pd.merge(df1,df2,left_on='lkey',right_on='rkey',how='left') #当连接列名不同分别指定
#concat 拼接
pd.concat([df1,df1]) #纵向连接,当s1和s2索引不重叠时,可以直接拼接
pd.concat([df1,df1],axis = 1) #横向连接,默认外连接,以行索引为连接字段
Pandas 函数用法示例
mySeries = pd.Series([1,2,3,4], index=['a','b','c','d']) data = {'Country' : ['Belgium', 'India', 'Brazil' ], 'Capital': ['Brussels', 'New Delhi', 'Brassilia'], 'Population': [1234,1234,1234]} df = pd.DataFrame(data, columns=['Country','Capital','Population']) pd.DataFrame(np.random.rand(20,5)) df = pd.read_csv('data.csv') pd.read_excel('filename') pd.to_excel('filename.xlsx', sheet_name='Sheet1') df.quantile([0.25, 0.75]) # 给出每一列中的25%和75%的分位数 filters = df.Date > '2021-06-1' df[filters] #选出日期在某个日期之后的所有行 df.filter(regex='^L') #选出 L 开头的列 df.sort_values('列名', ascending= False) #按指定列的值大小升序排列 df.rename(columns= {'老列名' : '新列名'}) #修改某个列名 df["新列"] = df.a- df.b #定义一个新的列表示为两个的差 df.columns = map(str.lower(), df.columns) #所有列名变为小写字母 df.columns = map(str.upper(), df.columns) #所有列名变为大写字母 df.drop(columns=['列名']) #删除某一列 df.drop(['列1', '列2'], axis=1) #含义同上,删除两列 mySeries.drop(['a']) #删除 Series 指定值 df.drop([0, 1]) #根据索引删除,双闭区间 def fun(x): return x*3 df.列名.apply(fun) #把某一列乘 3 倍 df.列名.apply(lambda x: x*3) #匿名表达式的写法 #melt的使用 df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},'B': {0: 1, 1: 3, 2: 5}, 'C': {0: 2, 1: 4, 2: 6}}) pd.melt(df, id_vars=['A'], value_vars=['B','C']) #增加一行数据 new=pd.DataFrame({'name':'lisa', 'gender':'F', 'city':'北京'},index=[1]) df = new df=df.append(new) #对每一列的数据,根据大小给个排名 frame = pd.DataFrame({'a':[2.3,-1.7,5,3],'b':[6,2.9,-3.1,8]},index=['one','two','three','four']) frame.rank(method="min",ascending=False) #merge 表示横向连接 df3 = pd.merge(df1,df2,how='inner',on='股票简称') #on表示连接列,how选择连接方式 #当连接列名不同分别指定 pd.merge(df1,df2,left_on='lkey',right_on='rkey',how='left') #concat 拼接 #纵向连接,当s1和s2索引不重叠时,可以直接拼接 pd.concat([df1,df1]) #横向连接,默认外连接,以行索引为连接字段 pd.concat([df1,df1],axis = 1)
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
Pandas教程 | 超好用的Groupby用法详解 - 知乎
Python笔记--Pandas常用函数汇总 - 知乎
pandas常用方法_胖大xian的博客-CSDN博客_pandas常用方法