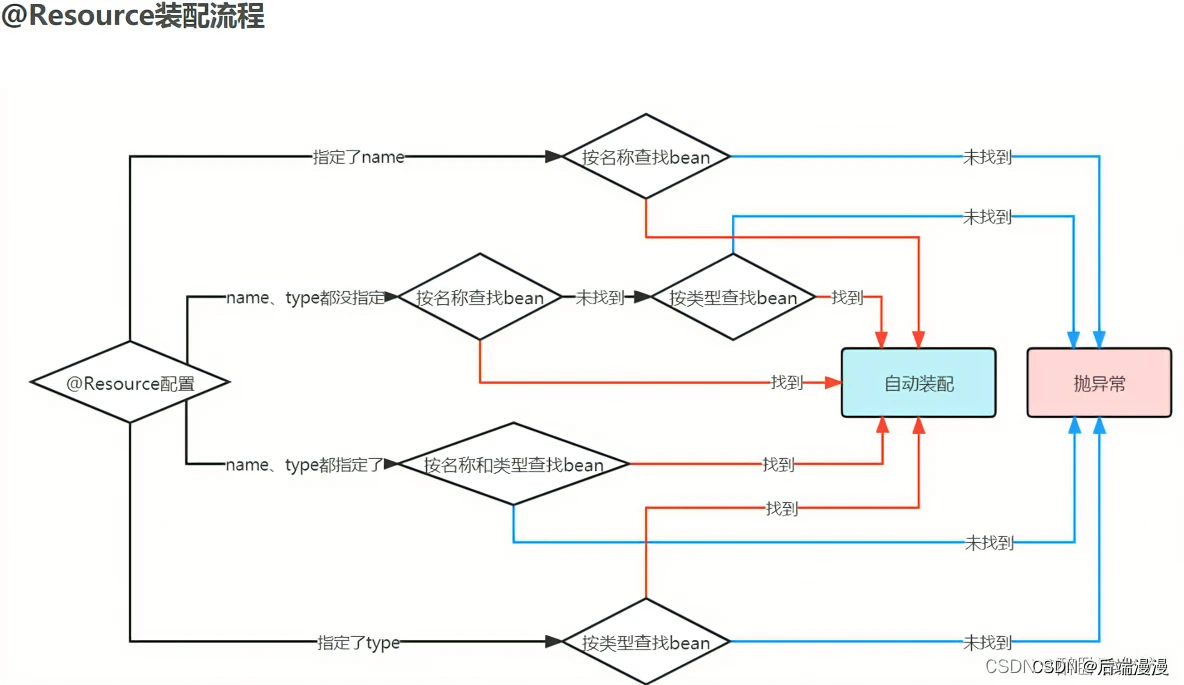
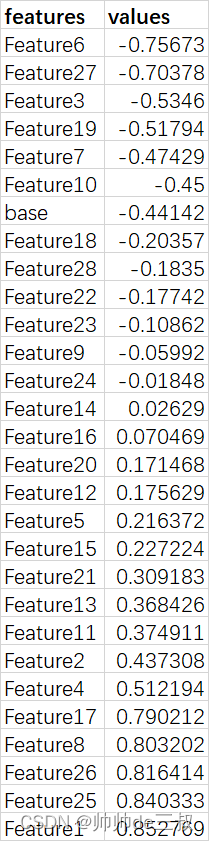
1. 什么是RNN
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。
2.RNN的优势
2-1 RNN
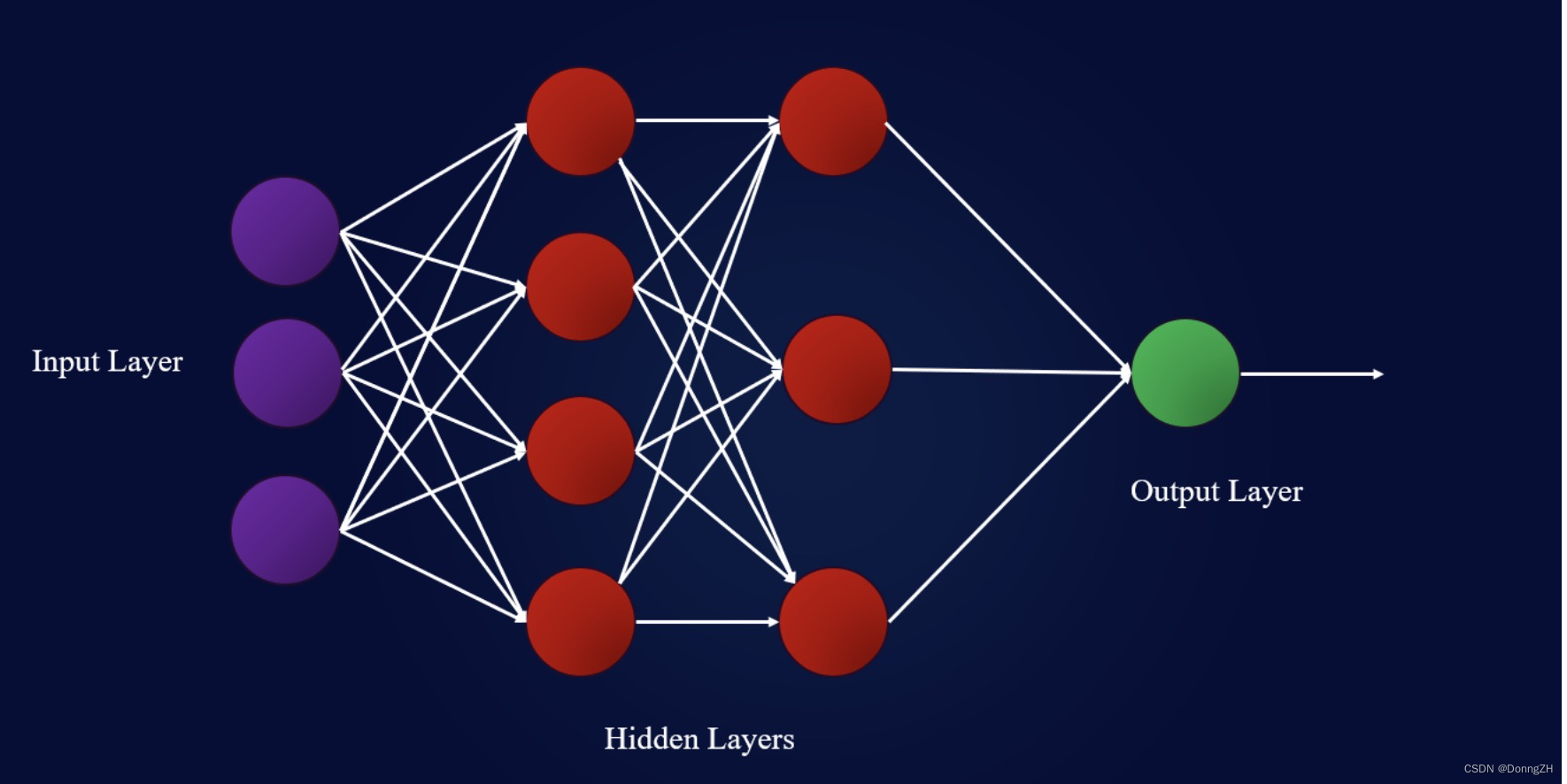
在传统的全连接神经网络中,模型结构是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。前提假设都是:元素之间是相互独立的,输入与输出也是独立的。这样就造成了在训练时,全连接神经网络学习不到上下文之间的联系。例如,要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。如下图为全链接神经网络。
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。如下图为循环神经网络。
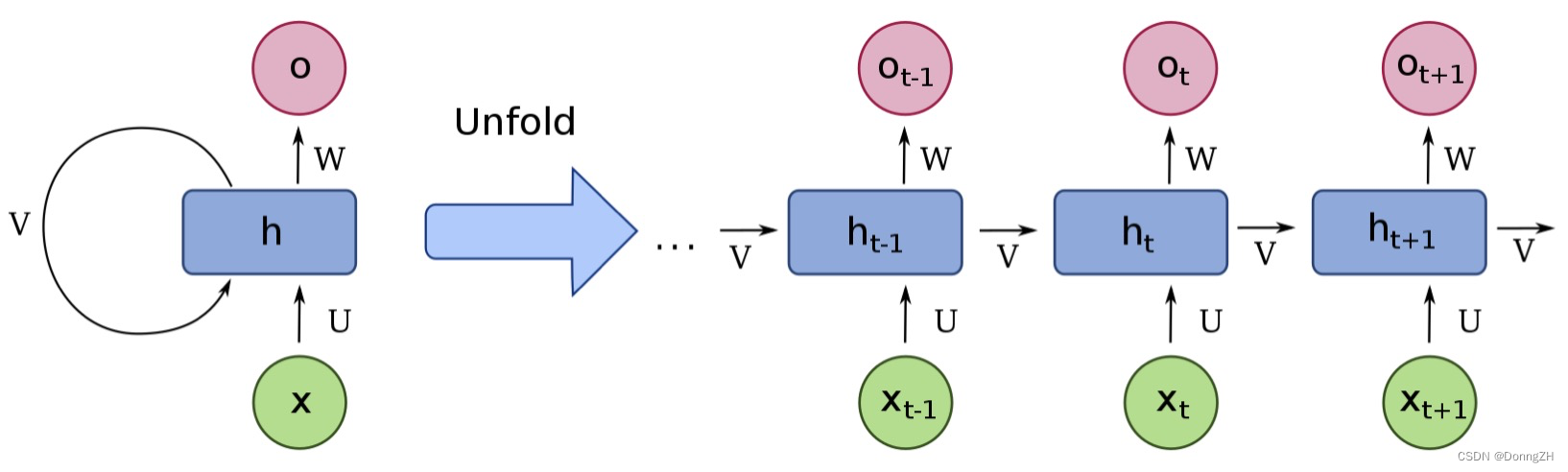
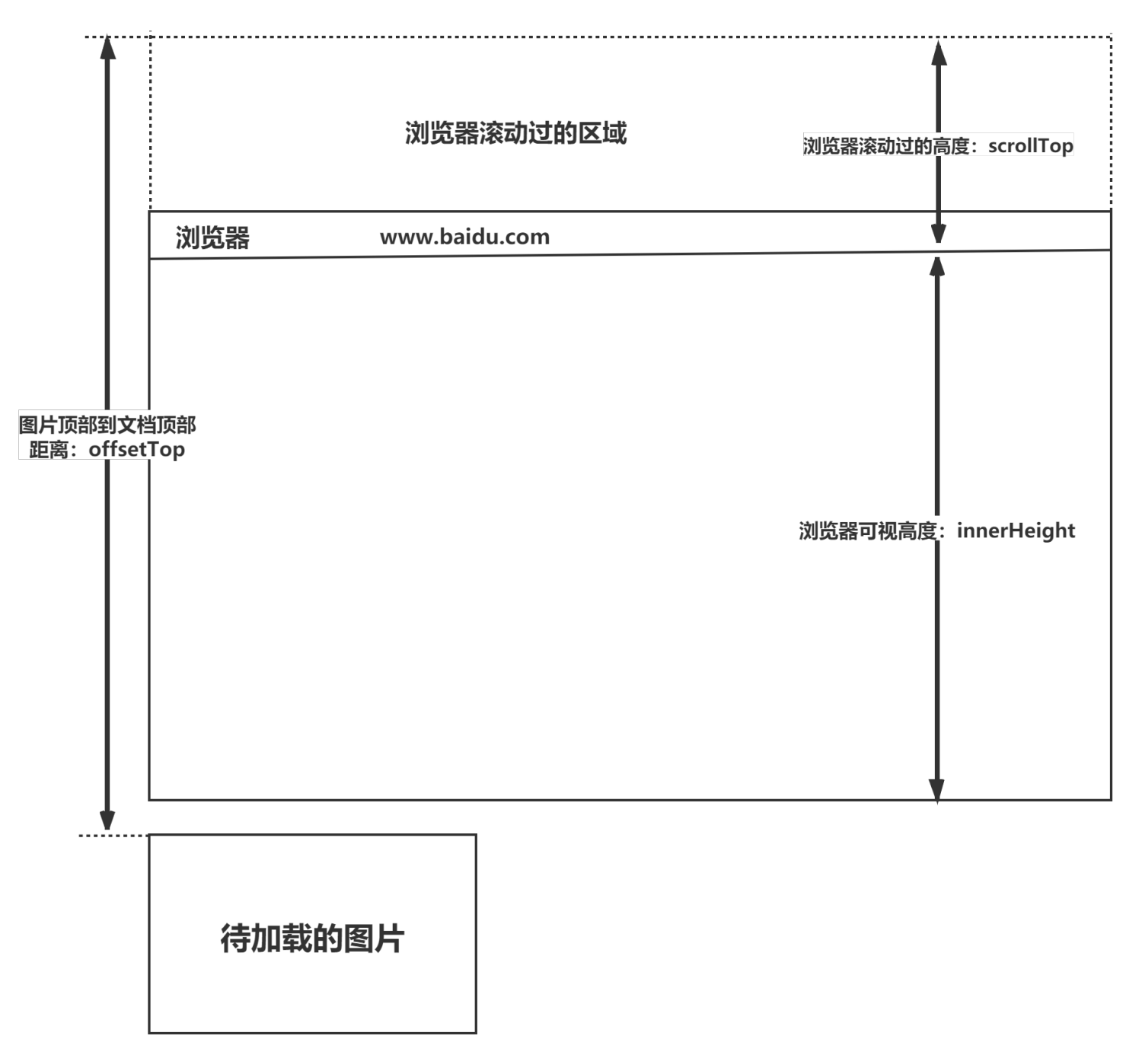
循环神经网络的本质是:像人一样拥有记忆的能力。因为我们当前时刻的输出是由记忆和当前时刻的输入决定的,就像你现在大四,你的知识是由大四学到的知识(当前输入)和大三以及大三以前学到的东西的(记忆)的结合,RNN在这点上也类似,神经网络最擅长做的就是通过一系列参数把很多内容整合到一起,然后学习这个参数,因此,他的输出就依赖于当前的输入和记忆。简要的介绍RNN就是一个简要的结构在重复使用。RNN的基础定义如下, 其中Xt:表示t时刻的输入,ot:表示t时刻的输出,ht:表示t时刻的记忆。
![]()
其中使用f()作为激活函数,一般使用tanh,做非线性映射,过滤信息。在预测的时候带着当前时刻的记忆ht去预测。假如要预测“我是中国“的下一个词出现的概率,这里已经很显然了,运用softmax来预测每个词出现的概率,但预测不能直接带用一个矩阵来预测,所有预测的时候还要带一个权重矩阵W,用公式表示为:
![]()
U、V、W作为参数是被所有的cell是共享的。
2-2 RNN的向前传播流程
RNN 一个非常重要的概念就是时刻。首先,它进行前向传递并进行预测。其次,它使用损失函数将预测与基础事实进行比较。损失函数输出一个错误值,该错误值是对网络执行得有多糟糕的估计。最后,它使用该误差值进行反向传播,计算网络中每个节点的梯度。

时刻的循环神经网络的输入包括t和从t_0时刻传递来的隐藏状态h_0。
循环神经网络在时刻接收到输入
之后,隐藏层的值是
,输出值是
。
的值不仅仅取决于
,还取决于
。为了将当前时刻的隐含状态
转化为最终的输出
,循环神经网络还需要另一个全连接层来完成这个过程。这和卷积神经网络中最后的全连接层意义是一样的。(如果不考虑 RNN 的输出还需要一个全连接层的情况,那么
和
的值是一样的)。
3.RNN梯度消失
3-1 梯度消失的定义
网络层之间的梯度(值小于 1.0)重复相乘导致的指数级减小会产生梯度消失,主要是因为网络层数太多,太深,导致梯度无法传播,如果导数小于1,那么随着网络层数的增加梯度更新信息会朝着指数衰减的方式减少,从而导致层数比较浅的权重没有更新,这就是梯度消失。
3-2 梯度消失本质原因
梯度传递的链式法则所导致的,神经网络的反向传播是逐层对激活函数求偏导数并相乘。梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足。
3-3 链式法则
假的时间序列只有三段, [公式] 为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下:

损失函数为:

对t=3时刻的 U、V、W求损失函数 L3的偏导

化简之后的公式如下:


tanh激活函数可以将实数映射到(-1,1)区间,当tanh的输出极值接近-1和1时,也面临梯度饱和的问题。 tanh和tanh导数的图像如下:

可以看出 tanh‘ 1 ,训练过程中几乎都是小于1的,而W 的值一般会处于0~1之间,当时间序列足够长,即t足够大时,足够多<=1的值累乘,就会造成
趋近于0,这就造成了梯度消失;而当W值很大(一般为初始化不当引起)时,就会趋近于无穷,这就造成了梯度爆炸。
特别说明
Q:为什么梯度消失使RNN的长时记忆失效,会忘记很久之前的信息?
A: 因为RNN的特殊性在于,它的权重是共享的。参数在任何时刻的梯度不会出现问题(因为不依赖于前面的时刻),但是参数
和
每一时刻都由前面所有时刻共同决定,是一个相加的过程。这样会存在一个问题,如果文本很长,计算了若干步之后,计算最前面的导数时,最前面的导数就会消失或爆炸,但当前时刻整体的梯度并不会消失,因为它是求和的过程,当下的梯度总会在,只是前面的梯度没了,但是更新时,由于权值共享,所以整体的梯度还是会更新,通常人们所说的梯度消失就是指的这个,指的是当下梯度更新时,用不到前面的信息了,因为距离长了,前面的梯度就会消失,也就是没有前面的信息了,但要知道,整体的梯度并不会消失因为当下的梯度还在,并没有消失。这样整体的梯度还是会更新,只是将前面的信息给遗忘了。