文章目录
- Redis 常见的数据类型及命令
- 一、常见的NoSQL
- 二、Redis 简介
- 三、key 键的一些操作命令
- 四、Redis的五种基本数据结构
- 1、String(字符串)
- 介绍
- 常用命令
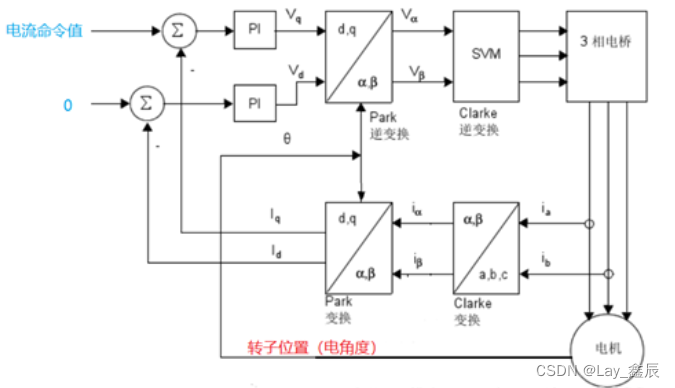
- 1.1 set/get
- 1.2 append
- 1.3 strlen
- 1.4 setex
- 1.5 mset/mget
- 1.6 setrange/getrange
- 1.7 setnx
- 1.8 incr/decr
- 1.9 incrby/decrby
- 1.10 getset
- 应用场景
- 2、List(列表)
- 介绍
- 常用命令
- 2.1 lpush/rpush
- 2.2 lrange
- 2.3 lpop/rpop
- 2.4 lindex
- 2.5 llen
- 2.6 lrem
- 2.7 lset
- 2.8 linsert
- 应用场景
- 3、Set(集合)
- 介绍
- 常用命令
- 3.1 sadd
- 3.2 smembers
- 3.3 sismember
- 3.4 scard
- 3.5 srem
- 3.6 spop
- 3.7 srandmember
- 3.8 smove
- 3.9 sinter
- 3.10 sunion
- 3.11 sdiff
- 应用场景
- 4、Hash(哈希)
- 介绍
- 常用命令
- 4.1 hset/hget
- 4.2 hmset/hmget
- 4.3 hexists
- 4.4 hkeys
- 4.5 hincrby
- 4.6 hdel
- 4.7 hsetnx
- 应用场景
- 5、Zset(有序集合)
- 介绍
- 常用命令
- 5.1 zadd
- 5.2 zrange
- 5.3 zrangebyscore
- 5.4 zrem
- 5.5 zincrby
- 5.6 zcount
- 5.7 zrank
- 应用场景
- 五、Redis的三种特殊数据结构
- 1、Bitmaps
- 介绍
- 常用命令
- 应用场景
- 2、Geospatial
- 介绍
- 常用命令
- 应用场景
- 3、Hyperloglog
- 介绍
- 常用命令
- 应用场景
Redis 常见的数据类型及命令
一、常见的NoSQL
NoSQL(Not Only SQL ),即“不仅仅是SQL”,泛指非关系型的数据库,主要针对的是键值、文档以及图形类型数据存储。并且,NoSQL 数据库天生支持分布式,数据冗余和数据分片等特性,旨在提供可扩展的高可用高性能数据存储解决方案。
1、KV型NoSQL(Redis)
键值数据库是一种较简单的数据库,其中每个项目都包含键和值。这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制。Redis 和 DynanoDB 是两款非常流行的键值数据库
- 数据基于内存,读写效率高
- KV型数据,时间复杂度为O(1),查询速度快
2、列式NoSQL(HBase)
按照列进行数据存储,该类型便于存储结构化和半结构化的数据,可以方便做数据压缩和针对某一列或者某几列的数据查询。 HBase 和 Cassandra 是两款非常流行的宽列存储数据库
3、文档型NoSQL(MongDB)
文档型NoSql指的是将半结构化数据存储为文档的一种NoSql,文档型NoSql通常以 JSON 或者 XML 格式存储数据。MongoDB 就是一款非常流行的文档数据库
4、搜索性NoSQL(ElasticSearch)
搜索型NoSql的诞生正是为了解决关系型数据库全文搜索能力较弱的问题,ElasticSearch 是搜索型 NoSql 的代表产品。ES的全文搜索特性使它成为构建搜索引擎的利器。除此之外,ES很好的支持了复杂聚合查询这一特点还使得ES非常适合拿来作数据分析使用
严格的说,ES 不是一个数据库,而是一个搜索引擎,ES的方方面面也都是围绕搜索设计的
关系型数据库(SQL)和非关系型数据库(NoSQL)的区别:
1)关系型数据库(SQL数据库):关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
优点:
- 易于维护:都是使用表结构,格式一致;
- 使用方便:SQL 语言通用,可用于复杂查询;
- 复杂操作:支持 SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
- 读写性能比较差,尤其是海量数据的高效率读写;
- 固定的表结构,灵活度稍欠;
2)非关系型数据库(NoSQL数据库)
优点:
- 格式灵活:存储数据的格式可以是 key-value 形式、文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快:NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
- 高扩展性;
- 成本低:NoSQL 数据库部署简单,基本都是开源软件。
缺点:
- 不提供 SQL 支持,学习和使用成本较高;
- 无事务处理;
- 数据结构相对复杂,复杂查询方面稍欠。
二、Redis 简介
Redis 是一个基于 C 语言开发的开源数据库(BSD 许可)。与传统数据库不同的是 Redis 的数据是存在内存中的(内存数据库),读写速度非常快,被广泛应用于缓存方向。并且,Redis 存储的是 KV 键值对数据。它的特点如下:
- 基于内存运行,性能高效
- 支持分布式,理论上可以无限扩展
- key-value 存储系统
- 开源的使用 ANSIC 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、KeyValue数据库,并提供多种语言的API
Redis 默认支持16个数据库,可以通过调整Redis的配置文件 redis/redis.conf 中的 databases 来修改这一个值,设置完毕后重启Redis便完成配置。
Redis 的默认端口号是 6379
可以通过 select 命令来切换数据库,例如:select 1;select 0;
三、key 键的一些操作命令

1、keys 查看当前库所有key
1)命令:keys
2)作用:查看当前库中所有的 key。
3)语法:keys *
有3个通配符:*,?,[]
- *:通配任意多个字符
- ?:通配单个字符
- []:通配括号内的某1个字符
> keys *
> keys ?ame
name
> keys [a,g,e]ge
ege
age
2、exists 查看key是否存在
1)命令:exists
2)作用:判断某个 key 是否存在,返回1表示存在,0不存在。当后面跟多个 key 时,只返回存在的个数,但不返回哪一个存在/不存在。
3)语法:exists key [key …]
> exists name
1
#id name age存在,a不存在
> exists id name age a
3
注意:关键字(exists等)都可以通过tab键来补全,而且命令行或者第三方工具都会有命令语法提示。
3、type 查看key的类型
1)命令:type
2)作用:查看当前 key 所储存的值的类型。返回当前 key 所储存的值的类型,如string 、list等。
3)语法:type key
> type name
string
4、del 删除已存在的key
1)命令:del
2)作用:删除已存在的key,不存在的 key 会被忽略。当后面跟多个 key 时,则返回删除成功的个数。
3)语法:del key [key …]
> del ege
1
#删除不存在的key
> del kkkkkk
0
> del v1 v2 v3
3
5、expire 设置 key 的过期时间
1)命令:expire
2)作用:给 key 设置过期时间,单位为秒。设置成功返回 1 。 当 key 不存在返回 0。
3)语法:expire key seconds
> expire id 300
(integer) 1
#查看剩余时间
> ttl id
(integer) 298
#当设置已经有过期时间的key时,会覆盖原来的过期时间
> expire id 600
(integer) 1
> ttl id
(integer) 597
当设置已经有过期时间的 key 时,会覆盖原来的过期时间。
6、ttl 查看key的剩余过期时间
1)命令:ttl
2)作用:以秒为单位返回 key 的剩余过期时间。当 key 不存在时,返回 -2 。 当 key 存在但没有设置剩余生存时间时,返回 -1 。 否则,以秒为单位,返回 key 的剩余生存时间。
3)语法:ttl key
> ttl id
-1
> ttl ids
-2
7、persist 移除key的过期时间
1)命令:persist
2)作用:移除给定 key 的过期时间,使得 key 永不过期。当过期时间移除成功时,返回 1 。 如果 key 不存在或 key 没有设置过期时间,返回 0 。
3)语法:expire key
> persist id
0
四、Redis的五种基本数据结构
1、String(字符串)

介绍
String 是 Redis 最基本的类型,一个 key 对应一个 value。String 是二进制安全的,意味着 String 可以包含任何数据,比如序列化对象或者一张图片。String 最多可以放 512M 的数据(但是大字符串非常不建议)。
常用命令
1.1 set/get
1)命令:
- set
- get
2)作用:
- 用于设置给定 key 的值。如果 key 已经存储其他值, set 就重写旧值,且无视类型。
- 用于获取指定 key 的值。如果 key 不存在,返回 nil 。
3)语法:
- set key value
- get key
> get name
"zhangsan"
> set name xiaobai
OK
> get name
"xiaobai"
> get namem
(nil)
1.2 append
1)命令:append
2)作用:将给定的 value 追加到 key 原值末尾,并返回 key 的长度
3)语法:append key value
> append name hello
12
> get name
xiaobaihello
注意:
- 如果 key 已经存在并且是一个字符串, append 命令将 value 追加到 key 原来的值的末尾。
- 如果 key 不存在, append 就简单地将给定 key 设为 value ,就像执行 set key value 一样。
1.3 strlen
1)命令:strlen
2)作用:获取指定 key 所储存的字符串值的长度。当 key 储存的不是字符串值时,返回一个错误。
3)语法:strlen key
> strlen name
12
#list1为list类型
> strlen list1
WRONGTYPE Operation against a key holding the wrong kind of value
1.4 setex
1)命令:setex
2)作用:给指定的 key 设置 value 值及秒级的过期时间。如果 key 已经存在, setex 命令将会替换旧的值,并设置过期时间。
3)语法:setex key seconds value
> setex num 300 v1
OK
> get num
v1
> ttl num
231
> setex num 300 v2
OK
> ttl num
296
> get num
v2
setex 和 expire 的区别在于,前者是在创建的 key 时设置过期时间,后者则是设置已经存在的 key。
1.5 mset/mget
1)命令:
- mset
- mget
2)作用:
- 同时设置一个或多个 key-value 。
- 返回所有(一个或多个)给定 key 的值。
3)语法:
- mset key value [key value …]
- mget key [key …]
> mset v1 123 v2 456 v3 789
OK
> mget v1 v3 v2
123
789
456
1.6 setrange/getrange
1)命令:
- setrange
- getrange
2)作用:
- 设置指定区间范围内的值,从 offset 位置开始依次往后设置(包含offset位置),返回字符串的长度
- 获取指定区间范围内的值,从 start 位置到 end 位置(包含两端)
3)语法:
- setrange key offset value
- getrange key start end
> set data abcdefg
OK
> setrange data 2 xxx
7
> get data
abxxxfg
> getrange data 2 5
xxxf
#end超过字符串的长度,即超过下标
> getrange data 2 9
xxxfg
注意:
- setrange 命令也可以直接创建 key 和 value。
- getrange 的 end 可以超过字符串长度,超过则为查看 offset 位置到字符串的末尾。
1.7 setnx
1)命令:setnx
2)作用:只有在 key 不存在时设置 key 的 value 值。成功则返回1,key 存在则返回 0。
3)语法:setnx key value
> setnx data a
(integer) 0
> setnx v5 123
(integer) 1
1.8 incr/decr
1)命令:
- incr
- decr
2)作用:
- 将 key 中储存的数字值增一,并返回 key 增一后的值
- 将 key 中储存的数字值减一,并返回 key 减一后的值
3)语法:
- incr key
- decr key
注意:
- 如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 incr/decr 操作。
- 如字符串类型的值不能表示为数字、或者是其他类型,那么返回一个错误。
> incr v1
1
> incr v1
2
> incr data
ERR value is not an integer or out of range
> decr v2
-1
> decr v2
-2
1.9 incrby/decrby
1)命令:
- incrby
- decrby
2)作用:
- 将 key 存储的数字值按照 increment 进行增加,并返回增加后的值。
- 将 key 存储的数字值按照 decrement 进行减小,并返回减小后的值。
3)语法:
- incrby key increment
- decrby key decrement
注意:
- 如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 incrby/decrby 操作。
- 如字符串类型的值不能表示为数字、或者是其他类型,那么返回一个错误。
> exists v1
0
> incrby v1 10
10
> get v1
10
> decrby v1 5
5
> incrby data 10
ERR value is not an integer or out of range
1.10 getset
1)命令:getset
2)作用:将给定 key 值设为 value,并返回 key 的旧值(old value),即先 get 然后立即 set
3)语法:getset key value
注意:
- 当 key 不存在时,getset 等同于 set;当 key 存在时,getset 等同于重命名
- getset 重命名与 get 重命名的区别在于,前者会返回旧值,而后者不会
> exists v1
0
> getset v1 123
null
> get v1
123
> getset v1 456
123
> get v1
456
应用场景
- 计数器:例如统计网站的访问量等
- 分布式锁
- 需要存储常规数据的场景:session、token、图片地址、序列化后的对象等
2、List(列表)

介绍
List 是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。底层是一个双向链表,对两端操作性能极高,通过索引操作中间的节点性能较差。
一个List最多可以包含 2^32 - 1个元素 ( 每个列表超过40亿个元素)。
常用命令
2.1 lpush/rpush
1)命令:
- lpush
- rpush
2)作用:
- 从左边(头部)插入一个或多个值,并返回列表的长度
- 从右边(尾部)插入一个或多个值,并返回列表的长度
3)语法:
- lpush key value [value …]
- rpush key value [value …]
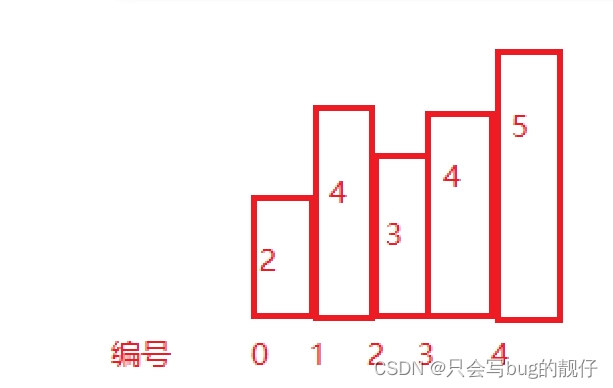
> lpush data v1 v2 v3
3
> lrange data 0 -1
v3
v2
v1
> rpush data v4 v5 v6
6
> lrange data 0 -1
v3
v2
v1
v4
v5
v6
上述的插入元素的过程具体如下图示(下面涉及到 data 列表的都可以参考这张图):

2.2 lrange
1)命令:lrange
2)作用:返回 key 列表中的 start 和 end 之间的元素(包含 start 和 end)。 其中 0 表示列表的第一个元素,-1表示最后一个元素。
3)语法:lrange key start end
注意:end 值是可以超过列表的长度的,即为查询从 start 位置开始到列表末尾的值。
> lrange data 1 3
v2
v1
v4
> lrange data 4 10
v5
v6
2.3 lpop/rpop
1)命令:
- lpop
- rpop
2)作用:
- 从列表中移除第一个值,并返回移除的值
- 从列表中移除最后一个值,并返回移除的值
3)语法:
- lpop key
- rpop key
注意:当列表中的元素全部被移除完,这个列表也就不存在了(值在键在,值光键亡)。
> lpop data
v3
> lpop data
v2
> rpop data
v6
> rpop data
v5
> rpop data
v4
> rpop data
v1
> exists data
0
2.4 lindex
1)命令:lindex
2)作用:获取列表 index 位置的值(从左边开始)。
3)语法:lindex key index
注意:
- index 的值是可以大于列表的长度的,不过查询到的值会为 null。
- index 的值也可以为负数,负数为从右边开始(例如上面 data 列表的 -1 的值 v6)
> llen data
6
> lindex data 4
v5
> lindex data 10
null
> lindex data -1
v6
> lindex data -5
v2
> lindex data -7
null
2.5 llen
1)命令:llen
2)作用:获取列表长度,不存在的 key 会返回 0。
3)语法:llen key
> llen data
6
# l 不存在
> llen l
0
2.6 lrem
1)命令:lrem
2)作用:从左边开始删除与 value 相同的 count 个元素,并返回成功删除的个数。
3)语法:lrem key count value
> lrem data 2 v1
1
> lrange data 0 -1
v3
v2
v4
v5
v6
> lrem data 2 v
0
2.7 lset
1)命令:lset
2)作用:将索引为 index 的值设置为 value,若 index 超过列表长度则会报错。
3)语法:lset key index value
> lset data 0 v0
OK
> lrange data 0 1
v0
v2
> llen data
5
> lset data 5 v0
ERR index out of range
> lset data 8 v0
ERR index out of range
2.8 linsert
1)命令:linsert
2)作用:在列表中 value 值的 前边/后边 插入一个 new value 值(从左开始),并返回列表的长度
3)语法:
- linsert key before value newvalue
- linsert key after value newvalue
> lrange data 0 -1
#列表此时为:v0 v2 v4 v5 v6
> linsert data before v2 v1
6
> linsert data after v2 v3
7
> lrange data 0 -1
#列表此时为:v0 v1 v2 v3 v4 v5 v6
应用场景
- 消息队列
- 信息流展示:如最新列表、关注的人列表、粉丝列表、排行榜等等
3、Set(集合)

介绍
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,当需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择。Set 是 String 类型的无序集合,它底层其实是一个 value 为 null 的 hash 表,所以添加、删除、查找的时间复杂度都是 O(1)。
常用命令
3.1 sadd
1)命令:sadd
2)作用:将一个或多个元素添加到集合 key 中,已经存在的元素将被忽略,并返回实际插入的个数。
3)语法:sadd key member [member …]
> sadd data v1 v2 v2 v3 v4 v5 v5 v6
6
> sadd data v7
1
> smembers data
v7
v6
v3
v4
v1
v5
v2
3.2 smembers
1)命令:smembers
2)作用:获取该集合的所有元素。
3)语法:smembers key
3.3 sismember
1)命令:sismembers
2)作用:判断集合 key 中是否含有 member 元素,如有返回1,否则返回0。
3)语法:sismember key member
> sismember data v4
1
> sismember data v9
0
3.4 scard
1)命令:scard
2)作用:返回该集合的元素个数。
3)语法:scard key
> scard data
7
> scard data1
0
3.5 srem
1)命令:srem
2)作用:删除集合中的一个或多个成员元素,不存在的成员元素会被忽略,并返回成功删除的个数
3)语法:srem key member [member …]
#v8 v9不存在
> srem data v5 v7 v8 v9
2
3.6 spop
1)命令:spop
2)作用:随机删除集合中一个元素并返回该元素。
3)语法:spop key
> spop data
v4 #删除的元素为v4
3.7 srandmember
1)命令:srandmember
2)作用:随机获取集合中 count 个元素,但不会删除。
3)语法:srandmember key [count]
count 不填则随机获取一个元素。
> srandmember data
v6
> srandmember data 1
v3
> srandmember data 2
v6
v1
> srandmember data 2
v2
v1
> srandmember data 4
v6
v3
v1
v2
3.8 smove
1)命令:smove
2)作用:将 member 元素从 source 集合移动到 destination 集合中,成功移动返回1,否则返回0
3)语法:smove source destination member
注意:
- destination 集合可以不存在。
- 如果 source 集合不存在或不包含指定的 member 元素,则 smove 命令不执行任何操作,仅返回0 。
> smove data data2 v3
1
> smembers data2
v3
> smove data data2 v9
0
> smembers data
v6
v1
v2
3.9 sinter
1)命令:sinter
2)作用:返回两个集合的交集元素。
3)语法:sinter key [key …]
> sadd data1 v2 v4 v5 v6 v1
5
> sadd data2 v4 v6 v8 v9 v0
5
#交集
> sinter data1 data2
v6
v4
#自己的话则全部
> sinter data1
v6
v5
v4
v2
v1
3.10 sunion
1)命令:sunion
2)作用:返回两个集合的并集元素。
3)语法:sunion key [key …]
> sunion data1
v6
v4
v5
v2
v1
#并集
> sunion data1 data2
v6
v4
v9
v8
v1
v5
v2
v0
3.11 sdiff
1)命令:sdiff
2)作用:返回两个集合的差集元素(要求:在前者集合中的元素,后者集合没有的元素)
3)语法:sdiff key [key …]
> sdiff data1
v6
v4
v5
v2
v1
> sdiff data1 data2
v5
v1
v2
应用场景
- 需要存放的数据不能重复的场景:例如文章点赞、动态点赞,签到打卡等
- 需要获取多个数据源交集、并集、差集的场景:例如共同好友、共同粉丝、关注的人等
- 需要随机获取数据源中的元素的场景:例如抽奖系统、随机等
4、Hash(哈希)

介绍
Hash是一个键值对的集合。Hash 是一个 String 类型的 field(字段) 和 value(值) 的映射表,hash特别适合用于存储对象。可以当做 Java 中的 Map<String, String> 对待。每一个 hash 可以存储 2^32-1 个键值对。
常用命令
4.1 hset/hget
1)命令:
- hset
- hget
2)作用:
- 给 key 集合中的 field 赋值 value,并返回成功设置的 field 个数
- 返回 key 哈希中取出 field 字段的值。
3)语法:
- hset key field value [field value …]
- hget key field
注意:
- 如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。
- 如果字段已经存在于哈希表中,旧值将被重写。
> hset data id 9 name xiaobai age 22 sex nan
4
> hset data email 123@.com
1
> hget data name
xiaobai
4.2 hmset/hmget
1)命令:
- hmset
- hmget
2)作用:
- 批量设置 key 中 field 字段的值
- 批量获取 key 中 field 字段的值
3)语法:
- hmset key field value [field value …]
- hmget key field [field …]
> hmget data id name age
9
xiaobai
22
4.3 hexists
1)命令:hexists
2)作用:判断指定 key 中是否存在 field,存在则返回 1,不存在则返回 0
3)语法:
> hexists data id
(integer) 1
> hexists data ids
(integer) 0
4.4 hkeys
1)命令:hkeys
2)作用:获取该哈希 key 中所有的 field
3)语法:hkeys key
> hkeys data
id
name
age
sex
email
4.5 hincrby
1)命令:hincrby
2)作用:为哈希表 key 中的 field 字段的值加上增量 increment,并返回操作后的值
3)语法:hincrby key field increment
注意:
- 增量也可以为负数,相当于对指定字段进行减法操作。
- 如果哈希表的 key 不存在,一个新的哈希表被创建并执行 hincrby 命令。
- 如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。
- 对一个储存字符串值的字段执行 hincrby 命令将造成一个错误。
> hincrby data age 1
23
> hget data age
23
> hincrby data age -2
21
> hincrby data2 age 1
1
> hincrby data2 age2 5
5
> hkeys data2
age
age2
4.6 hdel
1)命令:hdel
2)作用:删除哈希表 key 中的一个或多个指定字段,不存在的字段将被忽略,并返回成功删除的个数
3)语法: hdel key field [field …]
> hdel data2 age age2 age3
2
4.7 hsetnx
1)命令:hsetnx
2)作用:给key哈希表中不存在的的字段赋值 (即不覆盖原来的值),设置成功返回 1,设置失败返回 0
3)语法: hsetnx key field value
#data中存在id字段
> hsetnx data id 99
0
> hset data ids 99
1
应用场景
- 存储对象信息:例如购物车中的商品信息
- 存储表的信息
5、Zset(有序集合)

介绍
Zset与Set非常相似,是一个没有重复元素的String集合。不同之处是Zset的每个元素都关联了一个分数(score),这个分数被用来按照从低分到高分的方式排序集合中的元素。集合的元素是唯一的,但分数可以重复。
因为元素是有序的,所以可以根据分数(score)或者次序(position)来获取一个范围内的元素。
常用命令
5.1 zadd
1)命令:zadd
2)作用:将一个或多个元素(member)及分数(score)加入到有序集 key 中
3)语法:zadd key score member [score member …]
注意:
- 如果某个元素已经是有序集的元素,那么更新这个元素的分数值,并通过重新插入这个元素,来保证该元素在正确的位置上。
- 分数值可以是整数值或双精度浮点数。
- 如果有序集合 key 不存在,则创建一个空的有序集并执行 zadd 操作。
> zadd data 100 java 300 python 500 c++
3
> zadd key 200 java
1
> zadd data 600.00 php
1
> zrange data 0 -1
java
python
c++
php
5.2 zrange
1)命令:zrange
2)作用:返回 key 集合中的索引 start 和索引 end 之间的元素(包含 start 和 end)
3)语法:zrange key start end [withscores]
注意:
- 其中元素的位置按分数值递增(从小到大)来排序。 其中 0 表示列表的第一个元素,-1表示最后一个元素。
- withscores 是可选参数,是否返回分数。
> zrange data 0 1
java
python
> zrange data 0 1 withscores
java
100
python
300
5.3 zrangebyscore
1)命令:zrangebyscore
2)作用:返回key集合中的分数minscore 和分数maxscore 之间的元素(包含minscore 和maxscore )。其中元素的位置按分数值递增(从小到大)来排序。
3)语法: zrangebyscore key minscore maxscore [withscores]
> zrangebyscore data 300 500 withscores
python
300
c++
500
5.4 zrem
1)命令:zrem
2)作用:删除 key 集合下的 member 元素,并返回成功删除的个数
3)语法:zrem key member [member …]
> zrem data php
1
5.5 zincrby
1)命令:zincrby
2)作用:为元素 member 的 score 加上 increment 的值,并返回处理后的值
3)语法: zincrby key increment member
> zincrby data 100 java
200
> zincrby data -100 c++
400
5.6 zcount
1)命令:zcount
2)作用:统计该集合在minscore 到maxscore分数区间中元素的个数
3)语法: zcount key minscore maxscore
> zcount data 100 300
2
5.7 zrank
1)命令:zrank
2)作用:返回 member 元素在集合中的排名,从 0 开始。没有该元素则返回 null
3)语法: zrank key member
> zrank data java
0
> zrank data java1
null
应用场景
- 需要根据某个权重进行排序的场景:例如微信步数排行榜、直播间送礼物排行榜、游戏中的段位排行榜
- 需要存储的数据有优先级或重要程度的场景:例如优先级任务队列
五、Redis的三种特殊数据结构
1、Bitmaps
介绍
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
常用命令
| 命令 | 语法 | 作用 |
|---|---|---|
| setbit | setbit key offset value | 设置Bitmaps中某个偏移量的值。 |
| getbit | getbit key offset | 获取Bitmaps中某个偏移量的值 |
| bitcount | bitcount key [start end] | 统计字符串被设置为1的bit数量 |
| bitop | bitop operation destkey key [key …] | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
应用场景
- 需要保存状态信息的场景:例如打卡天数、活跃用户情况、统计用户是否在线、登录天数等
2、Geospatial
介绍
GEO,地理信息的缩写。该类型就是元素的二维坐标,在地图上就是经纬度。Redis基于该类型,提供了经纬度设置、查询、范围查询、距离查询、经纬度 Hash 等常见操作。
常用命令
| 命令 | 语法 | 作用 |
|---|---|---|
| geoadd | geoadd key longitude latitude member [longitude latitude member …] | 用于存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。 |
| geopos | geopos key member [member ……] | 从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。 |
| geodist | geodist key member1 member2 [m|km|ft|mi] | 用于返回两个给定位置之间的距离。m :米,默认单位。km :千米。mi :英里。ft :英尺。 |
| georadius | georadius key longitude latitude radius m|km|ft|mi | 以给定的经纬度(longitude latitude)为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离(radius )的所有位置元素。 |
应用场景
- 需要管理使用地理空间数据的场景:附近的好友、两地之间的距离、附近的商场等
3、Hyperloglog
介绍
HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting(LLC) 优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近 2 * 64 个不同元素。并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
- 稀疏矩阵 :计数较少的时候,占用空间很小。
- 稠密矩阵 :计数达到某个阈值的时候,占用 12k 的空间。
常用命令
| 命令 | 语法 | 作用 |
|---|---|---|
| pfadd | pfadd key element [element] | 将所有元素参数添加到 Hyperloglog 数据结构中。如果内部有变动返回1,没有返回0 |
| pfcount | pfcount key [key] | 计算Hyperloglog 近似基数,可以计算多个Hyperloglog ,统计基数总数。 |
| pfmerge | pfmerge destkey sourcekey [sourcekey …] | 将一个或多个Hyperloglog(sourcekey) 合并成一个Hyperloglog (destkey ) |
应用场景
- 数据量巨大(百万、千万级别以上)的计数场景:例如热门网站每日/每周/每月访问 ip 数统计
- 基数统计




![[Android Studio] Android Studio使用keytool工具读取Debug 调试版数字证书以及release 发布版数字证书](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)