💗wei_shuo的个人主页
💫wei_shuo的学习社区
🌐Hello World !
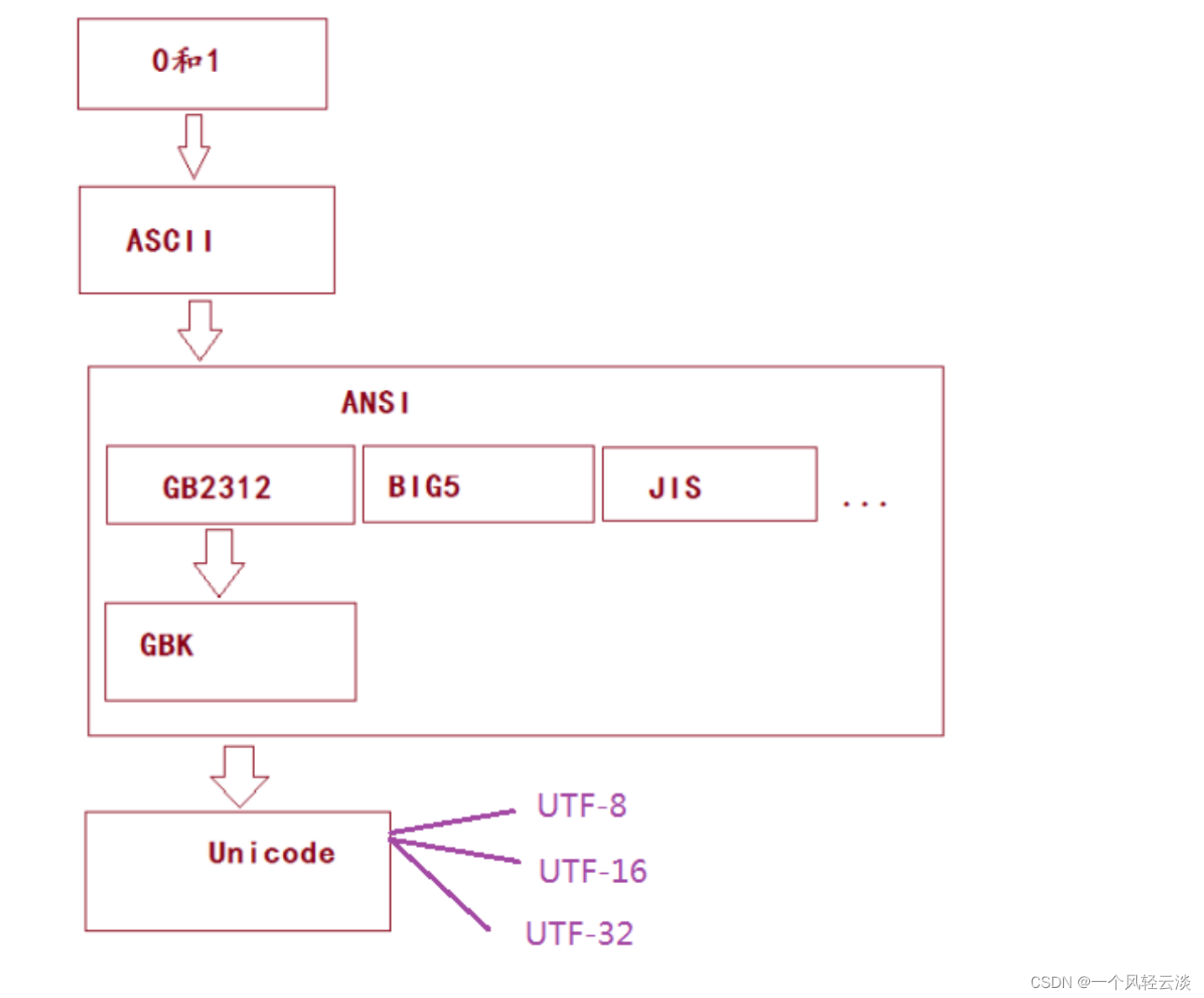
动态SQL

动态SQL就是指根据不同条件生成不同的sql语句,本质还是SQL语句,知识可以在SQL层面,执行逻辑代码
搭建环境
- 创建数据库
create database mybatis;
- 创建表
CREATE TABLE `blog`( `id` VARCHAR(50) NOT NULL COMMENT '博客id', `title` VARCHAR(100) NOT NULL COMMENT '博客标题', `author` VARCHAR(30) NOT NULL COMMENT '博客作者', `create_time` DATETIME NOT NULL COMMENT '创建时间', `views` INT(30) NOT NULL COMMENT '浏览量' )ENGINE=INNODB DEFAULT CHARSET=utf8;
创建基础工程
- 导包
<dependencies> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.24</version> </dependency> </dependencies>
- 编写配置文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <!--configuration核心配置文件--> <configuration> <!-- 引入外部配置文件--> <properties resource="db.properties"/> <settings> <!--标准日志工厂实现--> <setting name="logImpl" value="STDOUT_LOGGING"/> <!--开启驼峰命名自动映射--> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> <!--实体类起别名--> <typeAliases> <package name="com.wei.pojo"/> </typeAliases> <!-- 环境配置--> <environments default="development"> <environment id="development"> <!--事物管理--> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${driver}"/> <property name="url" value="${url}"/> <property name="username" value="${username}"/> <property name="password" value="${password}"/> </dataSource> </environment> </environments> <!--绑定接口--> <mappers> <mapper class="com.wei.dao.BlogMapper"/> </mappers> </configuration>
- 编写实体类
package com.wei.pojo; import lombok.Data; import java.util.Date; @Data public class Blog { private int id; private String title; private String author; private Date createTime; private int views; }
- 编写实体列Mapper接口
package com.wei.dao; import com.wei.pojo.Blog; public interface BlogMapper { //插入数据 int addBlog(Blog blog); }
- 编写实体列对应的映射文件Mapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.wei.dao.BlogMapper"> <insert id="addBlog" parameterType="blog"> insert into mybatis.blog (id, title, author, create_time, views) VALUES (#{id}, #{title}, #{author}, #{createTime}, #{views}) </insert> </mapper>
- 测试
import com.wei.dao.BlogMapper; import com.wei.pojo.Blog; import com.wei.utils.IDutils; import com.wei.utils.MybatisUtils; import org.apache.ibatis.session.SqlSession; import org.junit.Test; import java.util.Date; public class MyTest { @Test public void test(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); BlogMapper mapper = sqlSession.getMapper(BlogMapper.class); Blog blog = new Blog(); blog.setId(IDutils.getId()); blog.setTitle("Mybatis如此简单"); blog.setAuthor("kuangshen"); blog.setCreateTime(new Date()); blog.setViews(9999); mapper.addBlog(blog); blog.setId(IDutils.getId()); blog.setTitle("Java如此简单"); mapper.addBlog(blog); blog.setId(IDutils.getId()); blog.setTitle("Spring如此简单"); mapper.addBlog(blog); blog.setId(IDutils.getId()); blog.setTitle("微服务如此简单"); mapper.addBlog(blog); sqlSession.close(); } }
if语句
- BlogMapper接口类
//查询博客 List<Blog> queryBlogIF(Map map);
- BlogMapper.xml映射文件
<mapper namespace="com.wei.dao.BlogMapper"> <select id="queryBlogIF" parameterType="map" resultType="blog"> select * from mybatis.blog where 1=1 <if test="title!=null"> and title=#{title} </if> <if test="author!=null"> and author=#{author} </if> </select> </mapper>
- MyTest测试类
@Test public void queryBlogIF(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); BlogMapper mapper = sqlSession.getMapper(BlogMapper.class); HashMap hashMap = new HashMap(); hashMap.put("title","Java如此简单"); hashMap.put("author","kuangshen"); List<Blog> blogs = mapper.queryBlogIF(hashMap); for (Blog blog : blogs) { System.out.println(blog); } sqlSession.close(); }
where语句
<mapper namespace="com.wei.dao.BlogMapper"> <select id="queryBlogIF" parameterType="map" resultType="blog"> select * from mybatis.blog <where> <if test="title!=null"> and title=#{title} </if> <if test="author!=null"> and author=#{author} </if> </where> </select> </mapper>
choose语句
<mapper namespace="com.wei.dao.BlogMapper"> <select id="queryBlogChoose" parameterType="map" resultType="blog"> select * from mybatis.blog <where> <choose> <when test="title!=null"> title=#{title} </when> <when test="author!=null"> and author=#{author} </when> <otherwise> and views =#{views} </otherwise> </choose> </where> </select> </mapper>
update语句
<mapper namespace="com.wei.dao.BlogMapper"> <update id="updateBlog" parameterType="map"> update mybatis.blog <set> <if test="title!=null"> title=#{title}, </if> <if test="author!=null"> author=#{author} </if> </set> where id = #{id}; </update> </mapper>
trim(where,set)
- prefix:trim标签内
sql语句加上前缀- prefixOverrides:忽略通过管道分隔的文本序列,移除所有指定在prefixOverrides属性中的内容,插入prefix属性中的内容[指定去除多余的前缀内容]
- suffix:trim标签内
sql语句加上后缀- suffixOverrides:忽略通过管道分隔的文本序列,移除所有指定在suffixOverrides属性中的内容,插入suffix属性中的内容[指定去除多余的后缀内容]
<trim prefix="WHERE" prefixOverrides=","> …… </trim> <trim prefix="SET" suffixOverrides=","> …… </trim>
SQL片段
将一些功能提出出来,方便复用,避免重复书写
- 使用SQL标签提取出公共的部分
<!--id:自定义id--> <sql id="if-title-author"> <if test="title!=null"> and title=#{title} </if> <if test="author!=null"> and author=#{author} </if> </sql>
- 需要使用的地方使用include标签引用即可
<select id="queryBlogIF" parameterType="map" resultType="blog"> select * from mybatis.blog <where> <!--refid:取上面自定义的id--> <include refid="if-title-author"></include> </where> </select>
foreach
foreach对集合进行遍历,通常构建在IN条件的时候
select * from mybatis.blog where 1=1 and (id=1 or id=2 or id=3);
- BlogMapper接口类
//查询第1,2,3号记录的博客 List<Blog> queryBlogForeach(Map map);
- BlogMapper.xml映射文件
<!-- select * from mybatis.blog where 1=1 and (id=1 or id=2 or id=3); 传递map,map可以存在一个集合 --> <select id="queryBlogForeach" parameterType="map" resultType="blog"> select * from mybatis.blog <where> <foreach collection="ids" item="id" open="and (" separator="or" close=")"> id=#{id} </foreach> </where> </select>
- 测试类
@Test public void queryBlogForeach(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); BlogMapper mapper = sqlSession.getMapper(BlogMapper.class); HashMap map = new HashMap(); ArrayList<Integer> ids = new ArrayList<>(); ids.add(1); ids.add(2); map.put("ids",ids); List<Blog> blogs = mapper.queryBlogForeach(map); for (Blog blog : blogs) { System.out.println(blog); } sqlSession.close(); }
Mybatis缓存
- Mybatis包含非常强大的查询缓存特性,它可以非常方便地定制和配置缓存,缓存可以极大的查询效率
- Mybatis系统中默认定义了两极缓存:
一级缓存/二级缓存
缓存失效情况:
- 查询不同数据
- 增删改操作,改变原来数据,必定刷新缓存
- 查询不同Mapper.xml
- 手动清理缓存
一级缓存(默认开启)
一级缓存也称为本地缓存
- 与数据库同一次会话期间查询到的数据会放到本地缓存中
- 以后如果需要获取相同的数据,直接从缓存中拿,不需要查询数据库
- User类
@Data @AllArgsConstructor @NoArgsConstructor public class User { private int id; private String name; private String pwd; }
- UserMapper接口类
public interface UserMapper { //根据ID查询用户 User queryUsersByID(@Param("id") int id); //更新用户 int updateUser(User user); }
- UserMapper.xml映射文件
<mapper namespace="com.wei.dao.UserMapper"> <!-- 实体类起别名: <typeAliases> <package name="com.wei.pojo"/> </typeAliases> --> <select id="queryUsersByID" parameterType="_int" resultType="user"> select * from mybatis.user where id=#{id}; </select> <update id="updateUser" parameterType="user"> update mybatis.user set name=#{name},pwd=#{pwd} where id=#{id}; </update> </mapper>
- MyTest测试类
@Test public void test(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.queryUsersByID(1); System.out.println(user); //更新数据 mapper.updateUser(new User(2,"aaa","bbb")); //手动清理缓存 sqlSession.clearCache(); System.out.println("==============================="); User user1 = mapper.queryUsersByID(1); System.out.println(user1); System.out.println(user==user1); sqlSession.close(); }
二级缓存

二级缓存也称为全局缓存
- 解决一级缓存作用域低的问题
- 基于namespace级别的缓存,一个命名空间对应一个二级缓存
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行
<cache/>
清除策略 作用 LRU(默认) 最近最少使用:移除最长时间不被使用的对象 FIFO 先进先出:按对象进入缓存的顺序来移除它们 SOFT 软引用:基于垃圾回收器状态和软引用规则移除对象 WEAK 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象
- eviction:清除策略
- flushInterval:刷新间隔属性,可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新
- size:引用数目属性,可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024
- readOnly:只读属性,可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false
二级缓存工作机制:
- 一个会话查询一条数据,这条数据会被放在当前会话的一级缓存中
- 如果当前会话关闭,这个会话对应的以及缓存就没有了;但需求是,会话关闭,一级缓存中的数据保存到二级缓存中
- 新的会话查询信息,就可以从二级缓存中获取内容
- 不同的mapper查出的数据会放在自己对应的缓存(map)
- 开启全局缓存
<settings> <!--显示开启全局缓存--> <setting name="cacheEnabled" value="true"/> </settings>
Mapper.xml中使用二级缓存
useCache=“true” 表示会将本条语句的结果进行开启二级缓存
useCache=“false” 示会将本条语句的结果进行关闭二级缓存
<!--在当前Mapper.xml中使用二级缓存--> <cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/> <select id="queryUsersByID" parameterType="_int" resultType="user" useCache="true"> select * from mybatis.user where id=#{id}; </select>
- MyTest测试类
@Test public void test(){ SqlSession sqlSession = MybatisUtils.getSqlSession(); SqlSession sqlSession2 = MybatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.queryUsersByID(1); System.out.println(user); sqlSession.close(); UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class); User user2 = mapper2.queryUsersByID(1); System.out.println(user2); sqlSession2.close(); System.out.println(user == user2); }总结:
- 开启二级缓存,同Mapper下有效
- 所有数据存放在一级缓存中
- 会话提交、关闭的时候,才会提交到二级缓存中
缓存原理
缓存顺序(
二级缓存——一级缓存——数据库)
- 第一次查询,首先查看二级缓存是否存在数据
- 然后查询以及缓存中是否存在数据
- 最后查询数据库
自定义缓存-ehcache
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider,主要面向通用缓存
- 导包
<dependency> <groupId>org.mybatis.caches</groupId> <artifactId>mybatis-ehcache</artifactId> <version>1.2.2</version> </dependency>
- resoures资源包下创建ehcache.xml
<?xml version="1.0" encoding="UTF-8"?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd" updateCheck="false"> <diskStore path="./tmpdir/Tmp_EhCache"/> <defaultCache eternal="false" maxElementsInMemory="10000" overflowToDisk="false" diskPersistent="false" timeToIdleSeconds="1800" timeToLiveSeconds="259200" memoryStoreEvictionPolicy="LRU"/> <cache name="cloud_user" eternal="false" maxElementsInMemory="5000" overflowToDisk="false" diskPersistent="false" timeToIdleSeconds="1800" timeToLiveSeconds="1800" memoryStoreEvictionPolicy="LRU"/> </ehcache>
- UserMapper.xml开启缓存
<!--在当前Mapper.xml中使用缓存--> <cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
- 创建自定义缓存MyCache类
package com.wei.pojo; import org.apache.ibatis.cache.Cache; public class MyCache implements Cache { @Override public String getId() { return null; } @Override public void putObject(Object o, Object o1) { } @Override public Object getObject(Object o) { return null; } @Override public Object removeObject(Object o) { return null; } @Override public void clear() { } @Override public int getSize() { return 0; } }

| 属性 | 描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句 |
| parameterType | 将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset) |
| resultType | 期望从这条语句中返回结果的类全限定名或别名。 注意,如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个 |
| resultMap | 对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个 |
| namespace | 映射文件中的namespace是用于绑定Dao接口的,即面向接口编程,namespace绑定接口后,你可以不用写接口实现类,mybatis会通过该绑定自动帮你找到对应要执行的SQL语句 |
🌼 结语:创作不易,如果觉得博主的文章赏心悦目,还请——
点赞👍收藏⭐️评论📝冲冲冲🤞







![推荐系统遇上深度学习(一四三)-[快手]一致性终身用户行为建模方法TWIN](https://img-blog.csdnimg.cn/img_convert/5a570c24ca54e61b7739a8efb6b8bca6.jpeg)