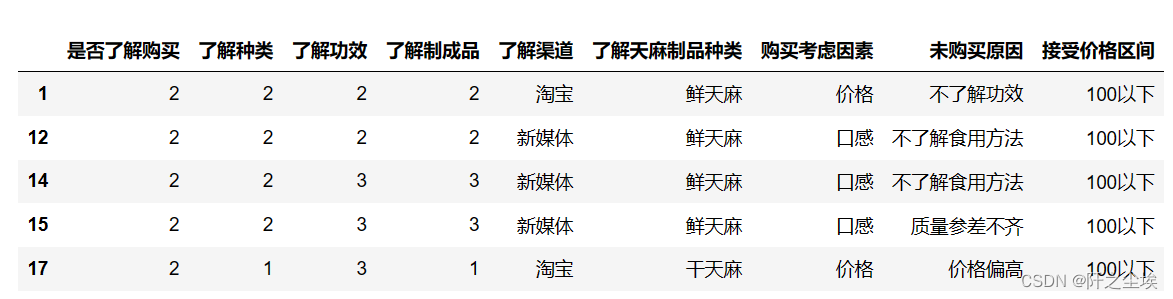
标题:《TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》
链接:https://arxiv.org/pdf/2302.02352.pdf
今天给大家分享的是快手近期发表的终身行为序列建模上的工作,当前工业界主流的方法大都是两阶段的方法,如SIM、ETA和SDIM,这些两阶段的方法面临的主要问题是阶段一致性问题,即一阶段筛选出的行为,并不一定是二阶段所认为的高度相关的行为。如果一阶段不能精确的筛选行为,那么无论二阶段如何设计良好的attention机制,其效果也只能是次优的。论文从这个角度出发,提出了两阶段一致的终身行为序列建模方法,称为TWIN(TWo-stage Interest Network)。接下来,一起了解一下。
1、背景
从用户的行为序列中准确建模用户的兴趣,已经成为CTR预估中的一个重要研究方向。其中一条重要的研究主线就是如何不断扩充用户的行为序列长度,从长度几十到几百,再到几千最终到终身行为序列建模。用户的终身行为序列能够更有效捕捉用户的长期兴趣,但也带来了计算耗时问题。因此业界大多数终身行为序列建模的方法采取一种两阶段的范式:GSU和ESU。
General Search Unit (GSU):从终身行为序列中快速挑选一小部分历史行为,如SIM-Hard按照简单的规则方式,挑选与target item品类相同的item;SIM-Soft通过预训练的embedding和内积进行item的筛选;ETA通过simhash和hamming distance进行相关性的筛选等等。
Exact Search Unit (ESU):通过高效的Target Attention(TA),建模从GSU筛选出的item与target item的相关性,得到用户的兴趣表示。
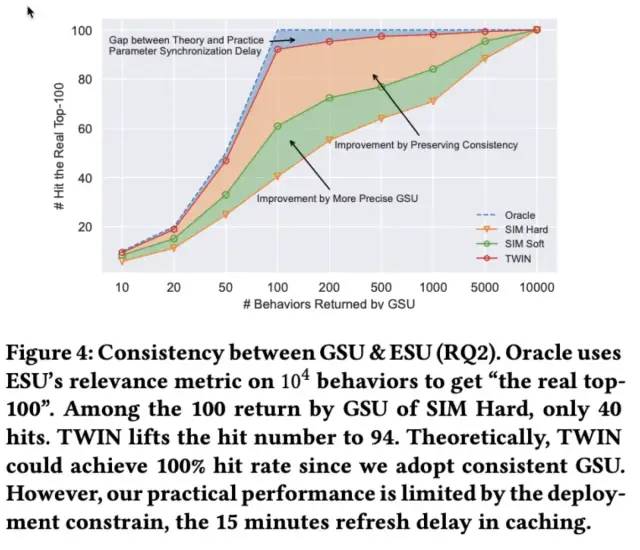
这种两阶段架构的研究重点为如何精确的从长用户行为序列中筛选出少量的item用于第二阶段的建模,上述所提及的工作均从相关性角度对item抽取,从SIM到ETA,实现了两阶段的端到端的建模,但论文认为,光有端到端是不足够的,还有很关键的一点是两阶段的一致性,即GSU筛选出的item也必须是ESU认为更相关的。如果GSU不能精确的筛选item,那么无论ESU如何设计良好的attention机制,其效果也只能是次优的。如下图所示,蓝色线为ESU认为最相关的top100的item,橙色线是SIM-Hard所认为的最相关的100个item,当SIM-Hard筛选100个时,只包含40个ESU所认为的最相关item。
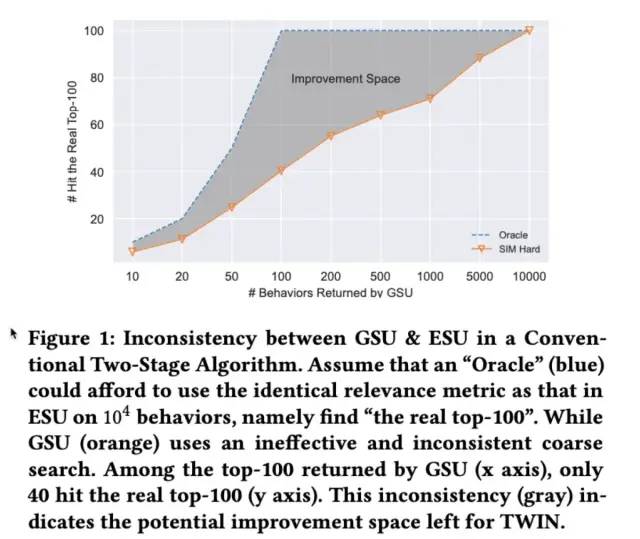
为了解决上述提到的一致性问题,一种思路是如何提升TA的计算效率,即从数百个序列长度扩展到数万个序列长度。沿着这个思路出发,论文提出了两阶段一致性的终身行为序列建模方法,称为TWIN(TWo-stage Interest Network),下一节,将会对TWIN进行详细介绍。
2、方法介绍
2.1 整体结构
TWIN的整体结构如下图所示:
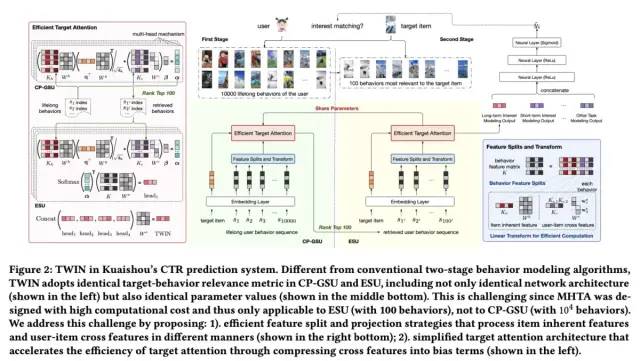
从图的右边可以看到,Embedding层之后,有三部分输入到后续的MLP层,分别是:
1)Short-term behavior modeling/TWIN:即论文重点优化的一致性终身行为序列建模方法,包含两个子模块,CP-GSU和ESU,这两部分将在后文进行详细介绍,这里不再展开
2)Short-term behavior modeling:从用户最近期的50个行为中建模用户的短期兴趣
3)Others Task Modelings:除用户行为建模外的一些信息,包含用户的一些属性信息、target item的属性信息以及一些上下文信息。
接下来,重点介绍TWIN的内容。
2.2 TWIN
为了精确建模用户的兴趣,用户行为通常通过Multi-Head Target Attention(MHTA)进行建模,由于MHTA计算复杂度较高,为满足工业耗时的要求,MHTA输入的用户行为长度通常限制在几百个。而TWIN解决的关键问题是,如何提升MHTA的计算效率,从数百个序列长度扩展到数万个序列长度。为此,论文提出了特征拆分和线性映射的思路。
2.2.1 特征拆分和线性映射
MHTA计算分析
提升Multi-Head Target Attention计算效率的一个思路是能否减少其计算量,将其中的一些计算提前算好并进行存储?MHTA涉及到Q、K、V的计算,以及Q、K的attention的计算,以及attention和V的计算几个过程。那么我们来分析下哪些是线上推理可以减少的计算过程。
1)Q的计算依赖于target item,这块肯定是线上推理所必须的,不可减少,但只用计算一次。
2)K的计算如果包含一些用户相关的特征如user-item的交叉特征等,是不能减少其线上推理计算量的,但如果特征中全是item自身的特征,不包含用户以及上下文信息,那么这块是可以提前计算并进行存储的,线上直接抽取即可。从这个角度出发,论文提出了特征拆分的思路。
3)V的计算可以放在attention计算之后,即放在ESU阶段,只对attention score最高的top行为计算即可,同时无需进行特征拆分。
4)attention计算:内积的方式,这部分耗时其实和SIM-soft是一样的
5)attention和V计算的到用户兴趣表示:ESU阶段计算,暂不考虑。
从上述分析可以看出,主要的优化思路是,通过特征拆解和线性映射,快速计算Q和K的attention score。
特征拆分
特征拆分的主要思路是将item的特征拆解为item的固有属性Kh如item id、作者、主题等和item-user交叉特征Kc如用户的观看时长等。对于固有属性,可以提前计算KhWh并进行存储,线上推理不再进行额外计算;对于交叉特征,通过简单的线性映射,作为偏置项加入到最终的attention score中。特征拆分和attention score的计算如下:
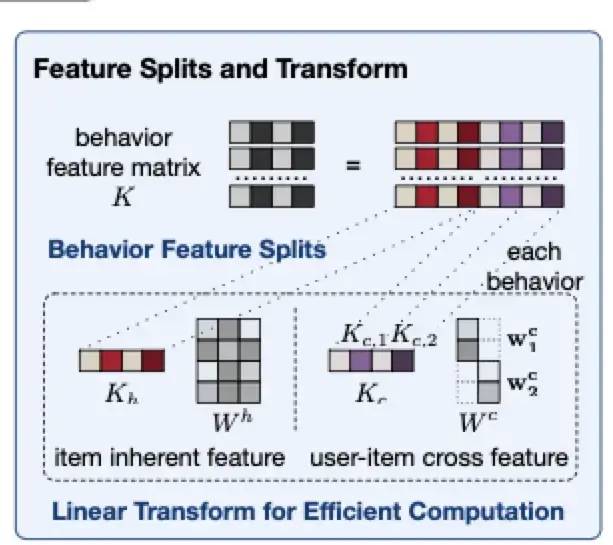
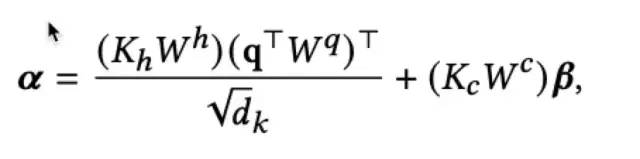
通过上述的两部分来计算attention score,兼顾了相关性和用户的兴趣程度:
1)对于target item,只能拿到固有属性信息,而user-item的交互信息属于穿越特征,线上无法获取。因此第一部分只使用固有属性信息,这可以看作是从相关性角度计算attention score,如品类、作者是否相同。
2)第二部分偏置项可以看作是从用户的兴趣程度出发,计算attention score,如两个相关性相同的视频(如作者、时长、类型相同),用户观看时间长的视频是用户更加感兴趣的,那么优先筛选观看时长长的视频。
2.2.2 Target Attention
计算得到attention score之后,可以筛选出top的行为,并计算最终的用户兴趣向量表示,该过程仅计算top的行为,不需要再对特征K进行拆分。计算如下:
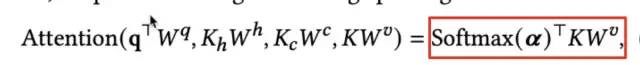
上述是从单头的角度进行介绍,TWIN最终使用4个head的MHTA:
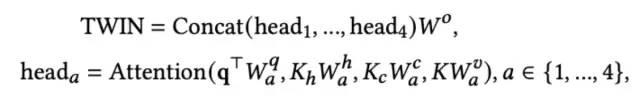
TWIN的相关介绍就到这里,出于篇幅考虑,时间复杂度和部署部分就不再进行介绍,前文或多或少都已经有所提及,感兴趣的同学可以阅读原文。
3、实验结果
最后来看下实验结果,首先是与Base模型的AUC指标对比:
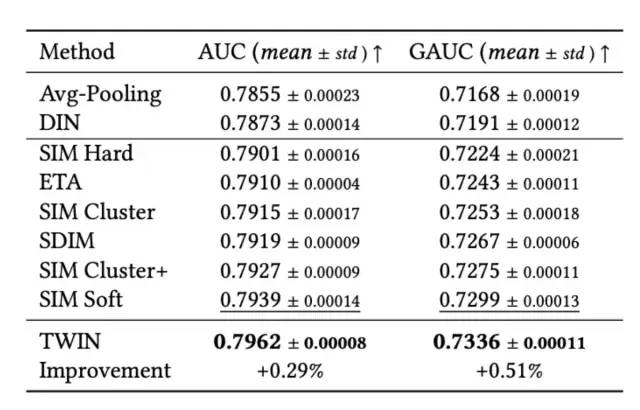
接下来看下一致性指标的对比,TWIN对比SIM有了大幅度的提升(好奇为什么没有贴ETA的对比):
好了论文就介绍到这里,整个论文的思路还是较为清晰,也是给了很多在用户行为序列建模上的启发,感兴趣的同学可以阅读原文~~