Pandas怎么添加数据列
1、直接赋值
# 1、直接赋值
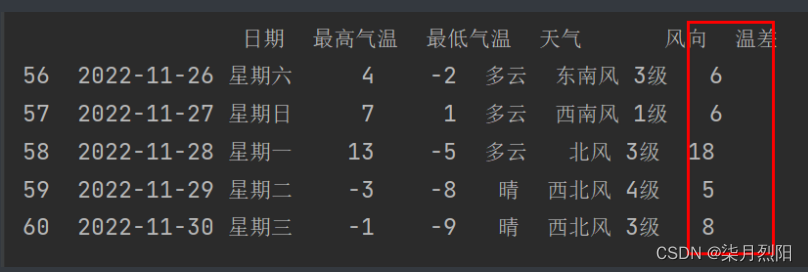
df.loc[:, "最高气温"] = df["最高气温"].str.replace("℃", "").astype("int32")
df.loc[:, "最低气温"] = df["最低气温"].str.replace("℃", "").astype("int32")
df.loc[:, "温差"] = df["最高气温"] - df["最低气温"]
2、df.apply方法
写一个判断
# df.apply
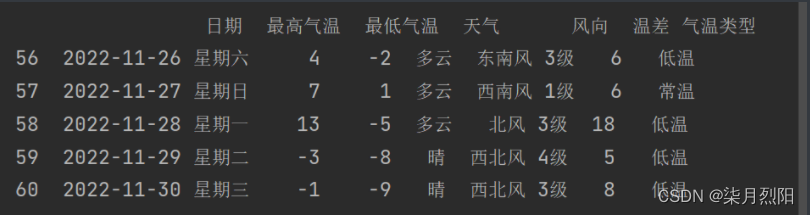
def get_wendu_type(x):
if x["最高气温"] > 20:
return "高温"
if x["最低气温"] < 0:
return "低温"
return "常温"
df.loc[:, "气温类型"] = df.apply(get_wendu_type, axis=1)
print(df.tail())
有趣且有用的方法
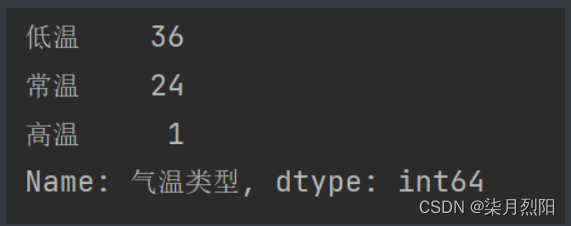
print(df["气温类型"].value_counts())
3、df.assign方法
lambda函数:
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法如下:
lambda [arg1 [,arg2,.....argn]]:expression
# df.assign方法
# 可以同时添加多个新的列
# 是返回一个新的dataFrame
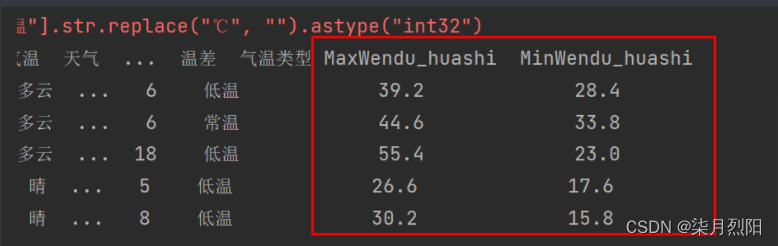
df = df.assign(
MaxWendu_huashi=lambda y: y["最高气温"] * 9 / 5 + 32,
# 摄氏度转华氏度
MinWendu_huashi=lambda y: y["最低气温"] * 9 / 5 + 32
)
print(df.tail())
4、按条件选择分组分别赋值
# 按条件选择分组分别赋值
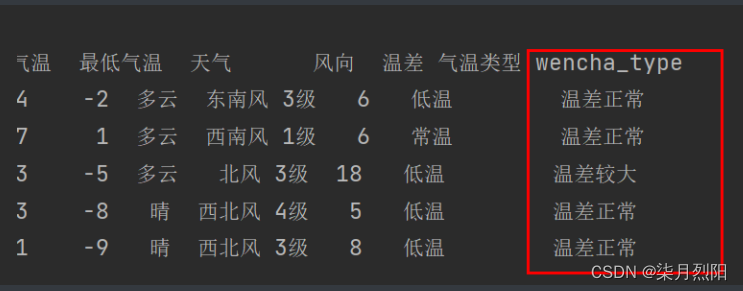
# 先创建空列
df["wencha_type"] = ''
df.loc[df['最高气温'] - df['最低气温'] > 10, "wencha_type"] = "温差较大"
df.loc[df['最高气温'] - df['最低气温'] <= 10, "wencha_type"] = "温差正常"
print(df.tail())
删除列
1、del df[] 改变原始数据
del df['MaxWendu_huashi']
2、df.drop(‘columns’,axis=1)
不改变原始数据,只是返回删除后的数据
3、df.drop(‘columns’,axis=1,inplace=‘True’)
df.drop('MinWendu_huashi', axis=1, inplace=True)