php 基于ICMP协议实现一个ping命令
- 网络协议是什么
- ICMP 协议
- 什么是ICMP?
- ICMP 的主要功能
- ICMP 在 IPv4 和 IPv6 的封装
- Wireshark抓包
- ICMP 请求包分析
- PHP构建 ICMP 数据包
- php中的 pack & unpack 函数
- 字节和字符
- pack
- unpack
- ICMP计算校验和步骤
- 总结
网络协议是什么
网络协议(network protocol)是为了进行网络中的数据交换而建立的规则、标准、或约定。协议规定了通信实体之间所交换消息的格式、意义、顺序以及针对收到信息或发生事情所采取的行动。
上面的解释可能不够通俗易懂,所以可以打个通俗的比方,比如有两个人 一个中国人,和一个小日子过得不错的日本人如下:
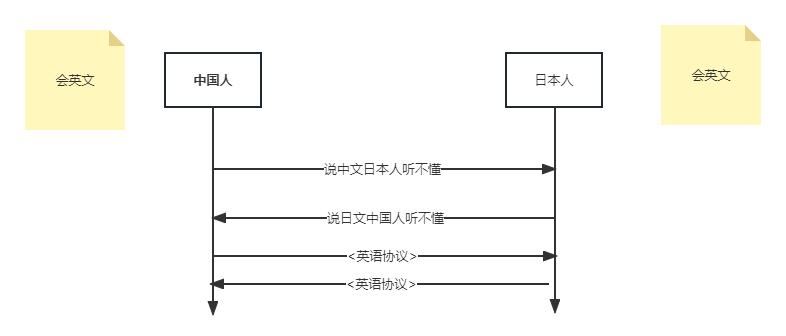
他们现在要交流,就必须讲一门双方都懂的语言。如果大家都不会讲对方的民族语言,那么可以选择双方都懂的第三方的语言来交流,比如“讲英语”。那么这时候“英语”实际上就成为一种“网络协议”。
把网络协议比做通用语言只是一种形象比喻,实际上协议本身比自然语言要简单的多,但是却比自然语言更严谨。协议规定了一种交流信息的格式或者说规范
同一种“规范”遵守的人多了,就成为一种事实上的“标准”。比如TCP/IP协议就成为了一种最流行的网络协议。
ICMP 协议
什么是ICMP?
ICMP 的全称是 Internet Control Message Protocol(互联网控制协议),它是一种互联网套件,它用于IP 协议中发送控制消息。也就是说,ICMP 是依靠 IP 协议来完成信息发送的,它是 IP 的主要部分,但是从体系结构上来讲,它位于 IP 之上,因为 ICMP 报文是承载在 IP 分组中的,就和 TCP 与 UDP 报文段作为 IP 有效载荷被承载那样。这也就是说,当主机收到一个指明上层协议为 ICMP 的 IP 数据报时,它会分解出该数据报的内容给 ICMP,就像分解数据报的内容给 TCP 和 UDP 一样。
ICMP 协议和 TCP、UDP 等协议不同,它不用于传输数据,只是用来发送消息。因为 IP 协议现在有两类版本:IPv4 和 IPv6 ,所以 ICMP 也有两个版本:ICMPv4 和 ICMPv6。
ICMP 的主要功能
对于 ICMP 的功能,主要分为两个
- ICMP 的第一个功能是确认 IP 包是否能够成功到达目标地址,当两个设备通过互联网相连时,任意一个设备发送给另一个设备的 IP 包如果没有到达,就会生成 ICMP 数据包发送给设备共享。
- ICMP 的第二个功能是进行网络诊断,经常使用 ICMP 数据包的两个终端程序是
ping和traceroute,traceroute程序用于显示两台互联网设备之间可能的路径并测量数据包在 IP 网络上的时延。ping 程序是 traceroute 的简化版本,我们经常使用 ping 命令来测试两台设备之间是否互联,ping通常用来测试两台主机之间的连接速度,并准确报告数据包到达目的地并返回后所花费的时间。
现在我们知道了,如果在 IP 通信过程中由于某个 IP 包由于某种原因未能到达目标主机,那么这个具体的原因将由 ICMP 进行通知,下面是一个 ICMP 的通知示意图
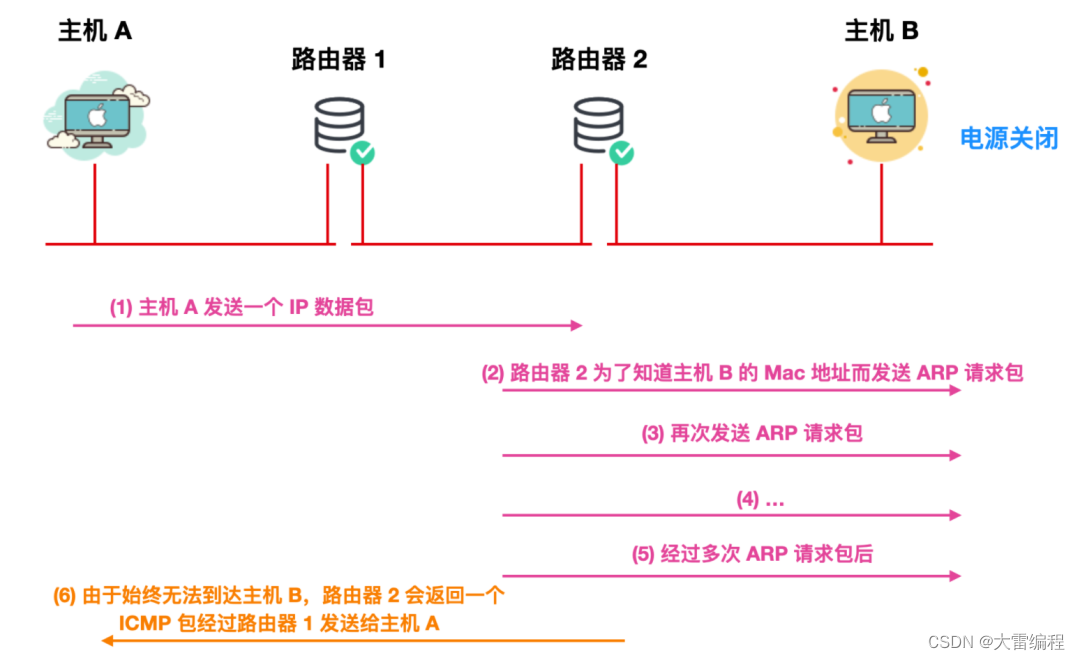
上面我们只是画出了路由器 2 给主机 A 发送了一个 ICMP 数据包,而没有画出具体的通知类型,但实际情况是,上面发送的是目标不可达类型(Destination unreachable),ICMP 也是具有不同的通知类型的,下面我们汇总了 ICMP 数据包的具体通知类型。
| 通知类型(十进制数) | 具体内容 |
|---|---|
| 0 | 回送应答(Echo Reply) |
| 3 | 目标不可达(Destination Unreachable) |
| 4 | 原点抑制(Source Quench) |
| 5 | 重定向或改变路由(Redirect) |
| 8 | 回送请求(Echo Request) |
| 9 | 路由器公告(Router Advertisement) |
| 10 | 路由器请求(Router Solicitation) |
| 11 | ICMP 超时(Time Exceeded) |
| 17 | 地址子网请求(Address Mask Request) |
| 18 | 地址子网应答(Address Mask Reply) |
上表显示的 ICMP 通知类型主要分为两类:有关 IP 数据报传递的 ICMP 报文,这类报文也叫做差错报文(error message),以及有关信息采集和配置的 ICMP 报文,这类报文也被称为查询 query 或者信息类报文。
信息类报文包括回送请求和回送应答(类型 8 和 类型 0 ),路由器公告和路由器请求(类型 9 和 类型 0 )。最常见的差错报文类型包括目标不可达(类型 3 )、重定向(类型 5)、超时(类型 11)。
ICMP 在 IPv4 和 IPv6 的封装
我们知道,ICMP 是承载在 IP 内部的,而且 IPv4 和 IPv6 的封装位置不同:
ICMP 在 IPv4 协议中的封装

ICMP 在 IPv6 协议中的封装

上面两张图显示了 ICMPV4 和 ICMPv6 的报文格式。ICMP头部的 4 个字节在所有的报文中都是一样的。但是其余部分在不同的报文中却不一样。
要构建一个ICMP包,首先我们要了解ICMP包的结构。
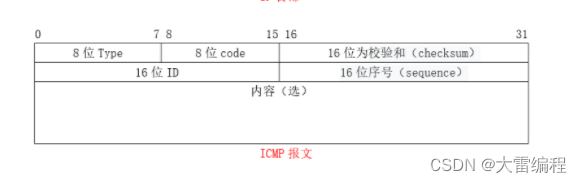
可以看到,一个标准的ICMP包由8(bit)位类型,8(bit)位代码,16(bit)位校验和,16(bit)位ID,16(bit)位序列号和数据组成。ICMPv4 和 ICMPv6 的类型和代码字段是不同的。咱们本次主要讲解 ICMPv4 数据包
Wireshark抓包
通过上面小结我们了解了ICMP 包的结构,咱们现场抓个ICMP 包 分析一下,这里我使用的抓包工具是 Wireshark 学习网络协议这个工具必不可少。
第一步 当你打开wireshark会出现网卡列表(如下图),想要捕获哪个网卡的数据包直接双击就可以了,简单方便(这里我使用的是无线网卡进行演示)。
第二步 通过 wireshark 的流量过滤栏过滤掉不需要的数据包,只展示 ICMP 数据包
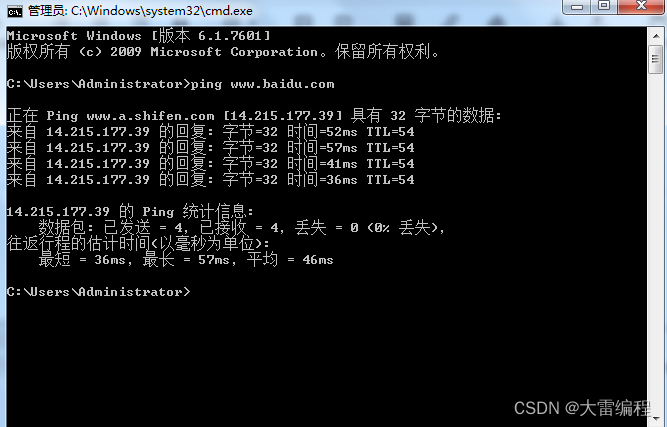
第三步 打开 windows cmd 命令行工具,使用ping 命令 ping 百度
第四步分析ICMP 数据包
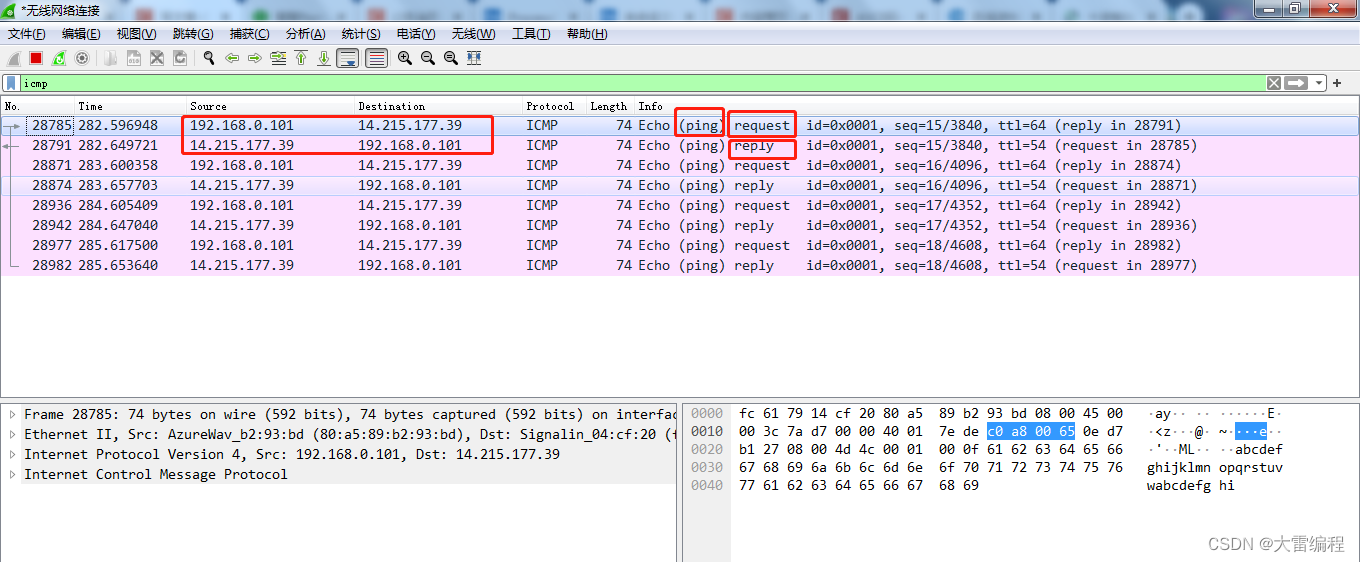
查看上图, wireshark 列表有8条数据,第一条数据 我们通过源IP地址与目标IP地址分析,应该是我这边发送给百度的请求包,因为我本地ip 就是 192.168.0.101,而且 wireshark 还很贴心的告诉我们这个是一个ping 请求 request
第二条数据一看就是百度的响应包了 reply,看后面的都是一个请求包对应一个响应包,一共4组,正好对应 cmd ping 命令有4次响应回复
ICMP 请求包分析
点开数据包后可以发现,上面有几个折叠的信息,越靠近上面的就越靠近物理层,越靠近下面的则越靠近应用层
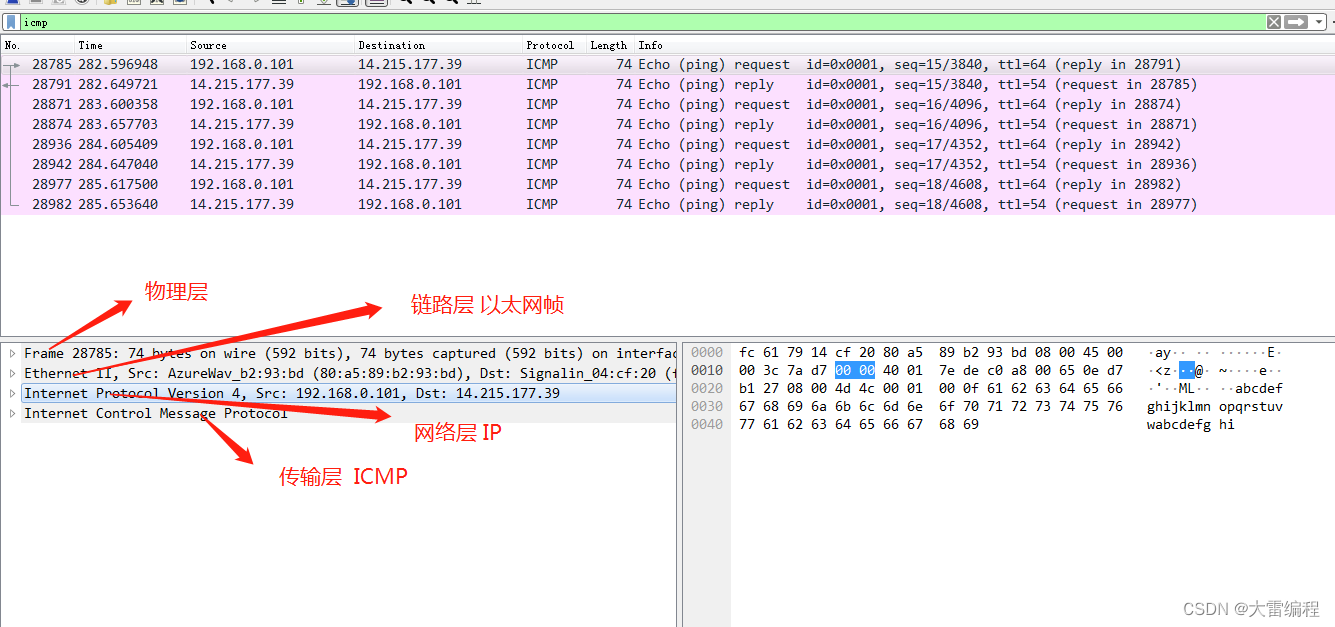
分析 ICMP 包结构和相对应意思
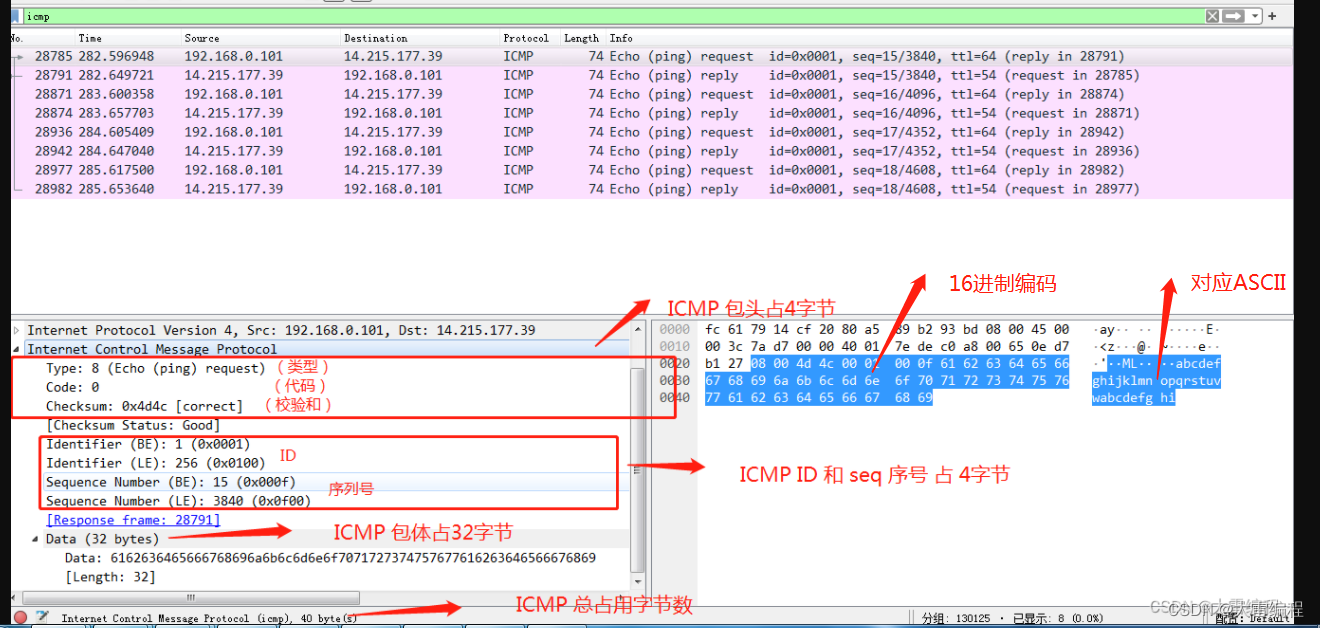
上图中 ICMP包由8位类型,8位代码,16位校验和,16位ID,16位序列号和数据组成。接下来,我们就通过PHP构建一个这样的数据包。
PHP构建 ICMP 数据包
$package = chr(8).chr(0);//模式 8 0
$package .= chr(0).chr(0);//置零校验和
$package .= "R"."C";//ID 这里随便填
$package .= chr(0).chr(1);//序列号 一样 随便填
for($i=strlen($package);$i<64;$i++){//填充满64位
$package .= chr(0);//数据
}
没接触过 chr() 函数的同学可能不太了解php提供的这个函数,这个函数的作用是将十进制编码转换成 ASCII 码。
不了解 ASCll 码的同学可以 访问 ASCll 码表 查看十进制编码和 ASCll 码的对应关系
第一行 chr(8) 代表ICMP包头 类型字段 占8 bit位 1字节,chr(0) 代表ICMP包头 代码字段 占8 bit位 1字节
$package = chr(8).chr(0);//模式 8 0
第二行 chr(0).chr(0) 代表ICMP包头 校验和字段 占16 bit位 2字节,由于要先构建出整个ICMP 包才能计算校验和所以我们需要先把校验和置 0 后面计算出校验和在替换
$package = chr(0).chr(0);//置零校验和
第三行和第四行 任意都填 chr(0).chr(1) 也没关系 不要超过 4字节就好, "R"."C" 代表 ICMP ID 字段,chr(0).chr(1) 代表 ICMP Sequence 字段
$package .= "R"."C";//ID 这里随便填
$package .= chr(0).chr(1);//序列号 一样 随便填
第五行 填充ICMP data 包体 ,这里我填充满 64 位,data 包体也就是占8字节
for($i=strlen($package);$i<64;$i++){//填充满64位
$package .= chr(0);//数据
}
构建好ICMP 数据包后 我们来计算校验和
php中的 pack & unpack 函数
在计算ICMP 校验和之前我们需要先了解两个重要的php函数 pack 和 unpack。在网络编程,读写图像,word/excel文件等场景,这两个函数几乎必不可少,掌握这两个函数是迈向高级PHP编程的基础。
学习 pack 和 unpack 需要一些前置知识的铺垫所以我们先介绍 字节 和 字符 的区别
字节和字符
PHP的优势是简单易用,熟练运用 字符串 和 数组 相关函数就能抗住一般的需求。日常工作中多用到字符串,所以PHP开发对字符都比较熟悉,但字符的伴生概念:字节,不少PHP开发并不熟悉。
字节和 字符 有什么联系和区别呢?简单来说 字节是计算机存储和操作的最小单位,字符是人们阅读的最小单位` ;
-
字节(Byte):字节是通过网络传输信息的单位。字节是计算机信息技术用于计量存储容量和传输容量的一种计量单位,1个字节等于8位二进制,它是一个8位的二进制数,是一个很具体的存储空间。
-
字符:人们使用的记号,抽象意义上的一个符号。就比如说:'字’, ‘0’, ‘A’, ‘.’ 等等。
总结一下就是:字节是 存储(物理)概念 ,字符是 逻辑概念 ;字节代表 数据 (内涵和本质),字符代表其 含义 ; 字符由字节组成 。
需要注意的一点是,相同的字符使用不同的编码占用的字节是不一样的
举个例子说明:
例子1:“中国”包含2个字符,GBK编码表示需要4个字节,UTF-8编码需要6个字节。
var_dump('UTF-8编码占用字节:'.strlen(mb_convert_encoding('中国','UTF-8')));
var_dump('GBK编码占用字节:'.strlen(mb_convert_encoding('中国','GBK')));

例子2:数字“1234567890”,包含10个字符,用 int32 类型表示只需4个字节;
| 十进制 | 二进制 |
|---|---|
| 1234567890 | 01001001 10010110 00000010 11010010 |
pack
pack(string $format, mixed ...$args): string 函数的作用是将参数值转换成二进制字符串,
字面上理解二进制字符串应该是像 01010101这样的东西,其实并不是这样 01010101 是二进制码
二进制字符串就是用二进制码来表示字符以及由多个字符构成的字符串。
通常我们采用美国标准信息交换码ASCII来表示字符
$format 的参数代表了以何种方式将对应的 $args 的参数值转换成[二进制]字符串也就是ASCII码字符串。
| 代码 | 描述 |
|---|---|
| a | 以 NUL 字节填充字符串 |
| A | 以 SPACE(空格) 填充字符串 |
| h | 十六进制字符串,低位在前 |
| H | 十六进制字符串,高位在前 |
| c | 有符号字符 |
| C | 无符号字符 |
| s | 有符号短整型(16位,主机字节序) |
| S | 无符号短整型(16位,主机字节序) |
| n | 无符号短整型(16位,大端字节序) |
| v | 无符号短整型(16位,小端字节序) |
| i | 有符号整型(机器相关大小字节序) |
| I | 无符号整型(机器相关大小字节序) |
| l | 有符号长整型(32位,主机字节序) |
| L | 无符号长整型(32位,主机字节序) |
| N | 无符号长整型(32位,大端字节序) |
| V | 无符号长整型(32位,小端字节序) |
| q | 有符号长长整型(64位,主机字节序) |
| Q | 无符号长长整型(64位,主机字节序) |
| J | 无符号长长整型(64位,大端字节序) |
| P | 无符号长长整型(64位,小端字节序) |
| f | 单精度浮点型(机器相关大小) |
| g | 单精度浮点型(机器相关大小,小端字节序) |
| G | 单精度浮点型(机器相关大小,大端字节序) |
| d | 双精度浮点型(机器相关大小) |
| e | 双精度浮点型(机器相关大小,小端字节序) |
| E | 双精度浮点型(机器相关大小,大端字节序) |
| x | NUL 字节 |
| X | 回退一字节 |
| Z | 以 NUL 字节填充字符串空白 |
| @ | NUL 填充到绝对位置 |
上面表格这么多参数看下来,我第一次是真心懵逼了,大部分说明都很好理解,但是其中的主机、大端、小端等字节序是什么鬼呢?接下的内容比较枯燥,但必须理解才行,坚持吧。
字节序是什么?
在不同的计算机体系结构中,对于数据(比特、字节、字)等的存储和传输机制有所不同,因而引发了计算机领域中一个潜在但是又很重要的问题,即通信双方交流的信息单元应该以什么样的顺序进行传送。如果达不成一致的规则,计算机的通信与存储将会无法进行。目前在各种体系的计算机中通常采用的字节存储机制主要有两种:大端(Big-endian)和小端(Little-endian)。这里所说的大端和小端即是字节序。
端的起源
“endian” 这个词出自 Jonathan Swift 在1726 年写的讽刺小说《格列佛游记》(Gulliver’s Travels)。小人国的内战源于吃水煮鸡蛋时究竟是从大头(Big-endian)敲开还是从小头(Little-endian)敲开,由此曾发生过6次叛乱,其中一个皇帝送了命,另一个丢了王位。
“Lilliput和Blefuscu这两大强国在过去36个月里一直在苦战。战争开始是由于以下的原因:我们大家都认为,吃鸡蛋前,原始的方法是打破鸡蛋较大的一端,可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋时碰巧将一个手指弄破了。因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令者重罚。老百姓们对这项命令极其反感。历史告诉我们,由此曾经发生过6次叛乱,其中一个皇帝送了命,另一个丢了王位。这些叛乱大多都是由Blefuscu的国王大臣们煽动起来的。叛乱平息后,流亡的人总是逃到那个帝国去寻求避难。据估计,先后几次有11000人情愿受死也不肯去打破鸡蛋较小的一端。关于这一争端,曾出版过几百本大部著作,不过大端派的书一直是受禁的,法律也规定该派任何人不得做官。” —— 《格列夫游记》 第一卷第4章
如何理解端这里先来定义两个概念:
-
MSB(Most Significant Bit/Byte):最重要的位或字节。它通常用来表明在一个 bit 序列(如一个 byte是8个 bit 组成的一个序列)或一个 byte 序列(如一个汉字是两个 byte 组成的一个序列)中对整个序列取值影响最大的那个 bit/byte。(即最高位字节) -
LSB(Little Significant Bit/Byte):最不重要的位或字节。它通常用来表明在一个 bit 序列(如一个 byte是8个 bit 组成的一个序列)或一个 byte 序列(如一个汉字是两个 byte 组成的一个序列)中对整个序列取值影响最小的那个bit/byte。(即最低位字节)
比如一个十六进制的整数 0x12345678 里面:
| 进制 | MSB(高字节) | LSB(低字节) | ||
|---|---|---|---|---|
| 16进制 | 0x12 | 0x34 | 0x56 | 0x78 |
| 2进制 | 00010010 | 00110100 | 01010110 | 01111000 |
0x12 就是 MSB(高字节),0x78 就是 LSB(低字节)。而对于 0x78 这个字节而言,它的二进制是 01111000,那么最左边那个 0 就是 MSB(高位),最右边那个 0 就是 LSB(低位)。
虚拟内存中高地址和低地址
在内存中,多字节对象都是被存储为连续的字节序列。假设将int整型在内存中的起始地址(首个字节存储位置)为0x1000,那么另外三个字节就存储在0x1001~0x1003。不管存储的字节顺序是怎样的,内存地址的分配都是从小到大的增长。其中0x1000称为低地址端,0x1003称为高地址端。

大端 和 小端 区别:
- 大端(Big-endian):规定 MSB 在
存储时放在低地址,在传输时放在流的开始;
LSB在存储时放在高地址,在传输时放在流的末尾。(即高位字节在前,低位字节在后。)
简单描述大端:高字节存放在低地址,低字节存放在高地址
- 小端(Little-endian):规定 MSB 在存储时放在高地址,在传输时放在流的末尾;LSB
在存储时放在低地址,在传输时放在流的开始。(即低位字节在前,高位字节在后。)
简单描述小端:低字节存放在低地址,高字节存放在高地址
| 内存地址(低——>高) | 字节存储顺序 | ||
|---|---|---|---|
| 大端(Big Endian) | 0x1000 0x1001 0x1002 0x1003 | 0x07 0x5B 0xCD 0x15 | 高字节存放在低地址 低字节存放在高地址 |
| 小端(Litter Endian) | 0x1000 0x1001 0x1002 0x1003 | 0x15 0xCD 0x5B 0x07 | 低字节存放在低地址 高字节存放在高地址 |
网络字节序和主机字节序
- 大小端一般是由CPU架构决定的。
- 网络字节序(Network Order):TCP/IP各层协议将字节序定义为Big Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
- 主机字节序(Host Order):整数在内存中保存的顺序,它遵循Little Endian规则(不一定,要看主机的CPU架构)。所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数
进行主机序列(Little Endian)和网络序(Big Endian)的转换。
主机字节序在网络传输时会转化成网络字节序
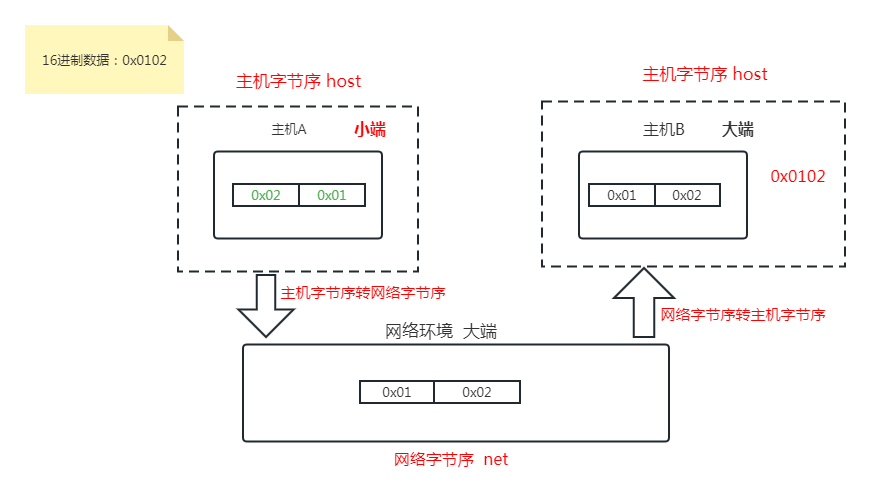
1、网络协议指定了通讯字节序—大端(大端字节序也叫网络字节序)
2、只有在多字节数据作为整体处理时才需要考虑字节序,单字节没有字节序问题,比如ASCII 码字符就没有字节序
3、运行在同一台计算机上的进程相互通信时,一般不用考虑字节序
为什么不统一使用一种字节序?
- 计算机电路先处理低位字节,效率比较高。因为计算就是从低位开始的,所以计算机内部很多都是小端字节序。
- 格式规范是为人类编写的,大端字节序更符合人类习惯。
讲了这么多,现在回归正题,根据php文档的描述pack函数,在 $format 使用诸如 “a,A,h,H” 代码的时候,后面可以加一个长度,这个长度代表了对对应的 $args 参数的前多少字节来进行转换,如果长度为2,则对 $args 参数前2个字节进行转换,后面忽略。如果长度为”*“,则对对应的 $args 参数所有字节进行转换
举个例子
//$format 的参数代码不同,转换出来的数据也不同,这里我们先使用 代码:”a” 来测试
代码:”a”
//官方的说明是:以 NUL 字节填充字符串
//简单的来说就是将 $args 当做字符来转换(可以对照ASCII表),
//那为什么描述上说是 “用NUL来填充“?后面会讲到的。为了方便,后面出现的转换结果都用16进制来表示
$bin = pack("a","w");
//将 "w" 这个字符转换成二进制字符串,直接对照ASCII码表就晓得了
// 对应的二进制字符串的16进制就是:0x77
带长度的转换:
pack("a3","abcde");
// 根据文档说明,我们知道只要转换 "abcde" 的前3个字节
// 对照ASCII表得知其转换结果是:0x61 0x62 0x63
带长度但是参数值字节长度不够的转换:
pack("a8","abcde");
// 根据文档说明,我们要把 "abcde" 字符串来当做8个字节来转换
// 但是参数值的长度不够怎么办,根据文档说明
// PHP会把不够的字节转换成NUL(解答了上面的疑问)
// 所以对照ASCII表得知其最终转换结果是:
// 0x61 0x62 0x63 0x64 0x65 0x00 0x00 0x00
unpack
unpack(string $format, string $string, int $offset = 0): array|false 是用来解包经过pack打包的数据包,如果成功,则返回数组。其中格式化字符和执行pack时一一对应,unpack其实只是将多个字节压缩成一个字节
ICMP计算校验和步骤
- 将校验和字段置为0。
- 将每两个字节(16位)相加(二进制求和)直到最后得出结果,若出现最后还剩一个字节继续与前面结果相加。
- (溢出)将高16位与低16位相加,
直到高16位为0为止。 - 将最后的结果(二进制)取反。得出校验和
$tmp = unpack("n*",$package);//把数据16位一组放进数组里
$sum = array_sum($tmp);//求和
// 判断高16位是否为0,不为0继续相加
while($sum >> 16){
// 取高16位 + 低16位
$sum = ($sum >> 16) + ($sum & 0xFFFF);//结果右移十六位 加上结果与0xFFFF做AND运算
}
$sum = ~ $sum;//做NOT运算
$checksum = pack("n*", $sum);//打包成2字节
$package[2] = $checksum[0];
$package[3] = $checksum[1];//填充校验和
第一步:unpack() 函数把字节数据16位一组放进数组里,为什么是16位,具体看计算校验和的第二条规则,我们打印 unpack() 函数返回的数据得到一个数组,数组的第一个元素2048 其实就是 chr(8).chr(0) ,我们转化一下进制就明白了
首先把2048转化成二进制数100000000000
由于2048是按16位解码的所以我们要把对应的二进制高位补0到16位
十进制:2048
转化————————————
二进制:00001000 00000000
二进制——》十进制
00001000——》8
00000000——》0
数组的第3个元素转化规则一样这里就不再赘述
$tmp = unpack("n*",$package);//把数据16位一组放进数组里
var_dump($tmp);
//打印出来的数据
array(32) {
[1] =>
int(2048)
[2] =>
int(0)
[3] =>
int(21059)
[4] =>
int(1)
...
[32] =>
int(0)
}
第二步: 把unpace 解码出来的10进制数相加(二进制求和)直到最后得出结果
$sum = array_sum($tmp);//求和
var_dump($sum);
23108
第三步: 将高16位与低16位相加,直到高16位为0为止
在讲解第三步之前,我们需要一点前置知识做铺垫
二进制位移运算操作(二进制位移分为逻辑位移和算数位移,下面讲的是逻辑位移)
右移位例子:2 = 4 >> 1(右移一位)
十进制:
- val=4
- res=2
二进制:
-
val=00000100
-
res=00000010
通过逻辑右移例子发现二进,制逻辑右移一位被舍弃,移位后左边补0
逻辑右移
特点:高位补0,低位移出。
左移位例子:8 = 4 << 1(左移一位)
十进制:
- val=4
- res=8
二进制:
-
val=00000100
-
res=00001000
二进制逻辑左移一位被舍弃,移位后右边补0
逻辑左移
特点:低位补0,高位移出。
按位与操作
( 0 = 0000) = ( 0 = 0000) & ( 5 = 0101)
( 1 = 0001) = ( 1 = 0001) & ( 5 = 0101)
( 0 = 0000) = ( 2 = 0010) & ( 5 = 0101)
( 4 = 0100) = ( 4 = 0100) & ( 5 = 0101)
( 0 = 0000) = ( 8 = 1000) & ( 5 = 0101)
$a & $b And(按位与) 把 $a 和 $b 中都为 1 的位设为 1,否则为0。
$sum = ($sum >> 16) + ($sum & 0xFFFF);//结果右移十六位 加上结果与0xFFFF做AND运算
十进制 二进制
23107 => 00000000 00000000 01011010 01000100
($sum >> 16) 得到高16位
高16 低16
00000000 00000000 01011010 01000100
>> 16
00000000 00000000 00000000 00000000
-------------------------------------
00000000 00000000
这里我解释一下为什么32位右移16位可以获得高16位,
我们知道二进制右移高位补0,原来的高位会移动到低位,
这样我们就获得的原来的高位。
($sum & 0xFFFF) 得到低16位
高位 低位
00000000 00000000 01011010 01000100
&
00000000 00000000 11111111 11111111
-------------------------------------
01011010 01000100
第四步(二进制)取反
在讲解取反前我们先来看个例子
$a = 8;
var_dump(~$a); //打印8的二进制取反
int(-9) //结果
结果跟我所想的不一样啊,因为在PHP中文手册中说: ~ $a Not(按位取反) 将 $a 中为 0 的位设为 1,反之亦然。 我只是简单的理解为:0变1,1变0。原来按位取反以十进制输出并不是简单理解成这样。
要解释上面的运算时怎么回事,首先我们需要知道二进制中的原码,反码,补码
有符号数:
对于有符号数而言,符号的正,负机器是无法识别的,但由于
"正,负"恰好是两种截然不同的状态,如果用"0"表示"正",用"1"表示"负"这样符号也被数字化了,并且规定将它放在有效数字的前面,即组成了有符号数。所以,在二进制中使用最高位(第一位)来表示符号,最高位为0,表示正数,最高位为1,表示负数。
无符号数:
无符号数是针对二进制来讲,无符号数的表数范围是
非负数。全部二进制均代表数值(所以位都用于表示数的大小),没有符号位,即第一个"0" 或 “1” 不表示正负
有符号数的性质:
- 二进制的最高位时符号位:0表示正数,1表示负数
- 正数的原码,反码,补码都一样
- 负数的反码 = 它的原码符号位不变,其它位取反 即0变1 ,1变0
- 负数的补码 = 它的反码 +1
- 0的反码,补码都是0
- 在计算机运算的时候,都是以补码的方式运行
我们计算过 (~8) = -9
那么这个-9是怎么得来的呢?
8的原码、反码、补码都是 :
00000000 00000000 00000000 00001000(原码)
00000000 00000000 00000000 00001000(反码)
00000000 00000000 00000000 00001000(补码)
(按位取反,对补码进行按位取反,符号位也会改变)
11111111 11111111 11111111 11110111(补码) //第一位是符号位,1代表负号,表示这是一个负数;记住运算和运算结果都是用补码表示的,这是某个数的补码,我们还需要推导反码和原码
负数的补码 = 它的反码 +1 ,现在我们求反码=补码-1,即:
11111111 11111111 11111111 11110110 (反码)
负数的反码 = 它的原码符号位不变,其它位取反 即0变1 ,1变0,我们需要转变回原码所以也需要相同的操作
10000000 00000000 00000000 00001001(原码)
所以结果是:-9
-8 按位取反
10000000 00000000 00000000 00001000(原码)
11111111 11111111 11111111 11110111 (反码)
11111111 11111111 11111111 11111000 (补码)
(按位取反后,对补码进行按位取反,符号位也会改变)
00000000 00000000 00000000 00000111(补码)
00000000 00000000 00000000 00000111(反码)
00000000 00000000 00000000 00000111(原码)
所以结果是:7
看完上面的例子,下面代码的结果就显而易见了。(这块地方我理解属实耗费了点时间,所以基础很重要!)
$sum = ~ $sum;//做NOT运算
第四步 把得出的校验和用pack函数打包成2字节,为什么打包成2字节,因为校验和占ICMP包16位,也就是2字节,我们需要把前面置0的校验和重新填充。
$checksum = pack("n*", $sum);//打包成2字节
$package[2] = $checksum[0];
$package[3] = $checksum[1];//填充校验和
这样,一个标准的ICMP数据包就构建好了,可以直接发送给目标主机了。
$tmp = unpack("n*",$package);//把数据16位一组放进数组里
$sum = array_sum($tmp);//求和
// 判断高16位是否为0,不为0继续相加
while($sum >> 16){
// 取高16位 + 低16位
$sum = ($sum >> 16) + ($sum & 0xFFFF);//结果右移十六位 加上结果与0xFFFF做AND运算
}
$sum = ~ $sum;//做NOT运算
$checksum = pack("n*", $sum);//打包成2字节
$package[2] = $checksum[0];
$package[3] = $checksum[1];//填充校验和
$host = "www.baidu.com";//设置目标主机
$socket=socket_create(AF_INET, SOCK_RAW, getprotobyname('icmp'));//创建原始套接字
$start = microtime();//记录开始时间
// socket_sendto 函数的作用,向套接字发送消息,无论它是否已建立连接
socket_sendto($socket, $package, strlen($package), 0, $host, 0);//发送数据包
$read = array($socket);//初始化socket
$select = socket_select($read, $write, $except, 5);
if ($select === FALSE){
$icmpError = "socket_select()方法发生错误,原因:".socket_strerror(socket_last_error());
socket_close($socket);
}else if($select === 0){
$icmpError = "请求超时";
socket_close($socket);
}
if($icmpError !== NULL){
echo $icmpError;
exit();
}
socket_recvfrom($socket, $recv, 65535, 0, $host, $port);//接受回传数据
/*回传数据处理*/
$end = microtime();//记录结束时间
$recv = unpack("C*", $recv);
$length = count($recv) - 20;//包长度 减去20字节IP报头
$ttl = $recv[9];//ttl ip头部 第九个字节就是 ttl
$seq = $recv[28];//序列号 ip头20字节 icmp头8个字节,所以28是icmp序列号
$duration = round(($end - $start) * 1000,3);//计算耗费的时间
echo "{$length} bytes from {$host}: icmp_seq={$seq} ttl={$ttl} time={$duration}ms".PHP_EOL;//输出结果
我们尝试来ping 一下百度
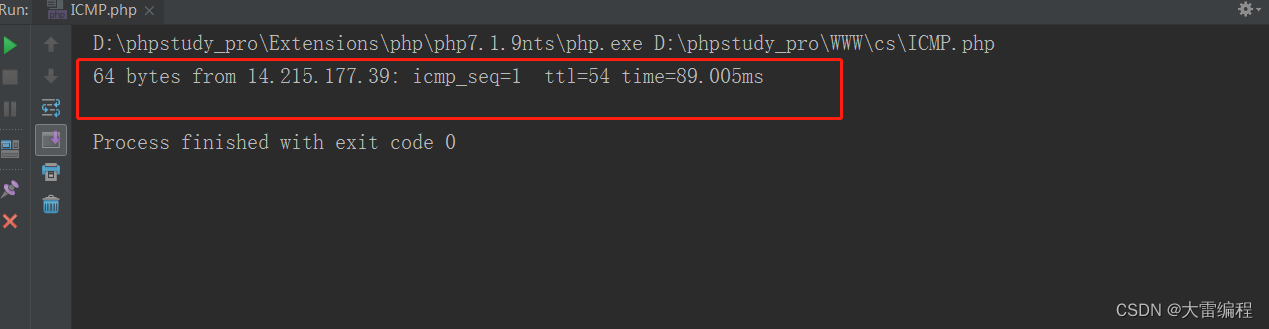
如图返回了一串结果,64 bytes 表示百度返回的icmp响应包大小,其实整个响应包的大小应该是84 bytes,因为ICMP 协议依赖IP协议完成任务,所以ICMP报文中要封装IP头部,我们需要抽离出单独的ICMP报文,就要减去前20字节的IP头部。
14.215.177.39 表示百度响应请求的ip ,icmp_seq 序列号用于关联请求报文和应答报文(对应请求和应答报文的序列号相同),占用2字节,下一个ttl 需要重点解释一下,最后一个time是一个ICMP包请求到响应的消耗时间。
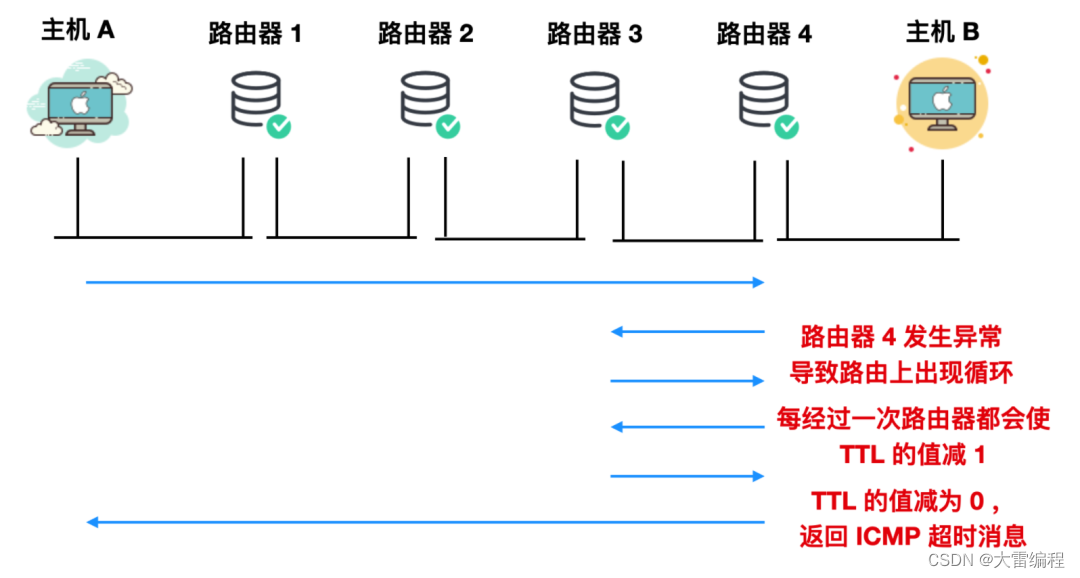
TTL
在 IP 数据包中有一个叫做 TTL(Time To Live, 生存周期) ,它的值在每经过路由器一跳之后都会减 1,IP 数据包减为 0 时会被丢弃。此时,IP 路由器会发送一个 ICMP 超时消息(ICMP TIme Exceeded Message, 错误号 0)发送给主机,通知该包已经被丢弃。
设置生存周期的主要目的就是为了防止路由器控制遇到问题发生循环状况时,避免 IP 包无休止的在网络上转发,如下图所示
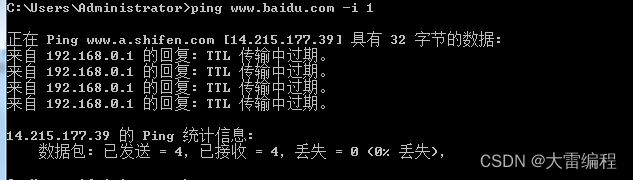
我们也可以用cmd ping 命令测试一下,把ttl 设置为1 ,当穿过第一个路由器,ttl -1 = 0,就会被丢弃。
TTL特点:
没经过一台三层设备会减1,当减到0的时候,三层设备就会丢弃该数据包
三层设备包括 交换机和路由器或者防火墙 ,三层表示的是网络OSI 参考模型的第三层网络层
总结
这次通学习php如果构建一个完整ICMP报文,引出了很多其它知识,比如字符,字节序,二进制的高位低位,有符号无符号等等;这些基础知识很重要,学习它们将对后面我们实现websock协议,MQTT协议提供重要帮助。
还有很重要的几个php 函数,pack,unpack,chr 有了这些函数的帮助我们很容易的处理二进制字节流解析与转换,如果还是对这些函数不是很理解我提供一些文章供大家学习参考。
参考地址
- PHP: 深入pack/unpack (https://www.cnblogs.com/66w66/p/13624016.html)
- PHP中的pack和unpack函数(https://segmentfault.com/a/1190000018264262?utm_source=sf-similar-article)
- PHP: chr和pack、unpack那些事(http://www.javashuo.com/article/p-orppnlys-e.html)
如果文章描述有错误,也请指正谢谢!