- 视频教程:哔哩哔哩网站:黑马大数据Hadoop入门视频教程 总时长:14:22:04
- 教程资源: https://pan.baidu.com/s/1WYgyI3KgbzKzFD639lA-_g 提取码: 6666
- 【P001-P017】大数据Hadoop教程-学习笔记01【大数据导论与Linux基础】【17p】
- 【P018-P037】大数据Hadoop教程-学习笔记02【Apache Hadoop、HDFS】【20p】
- 【P038-P050】大数据Hadoop教程-学习笔记03【Hadoop MapReduce与Hadoop YARN】【13p】
- 【P051-P068】大数据Hadoop教程-学习笔记04【数据仓库基础与Apache Hive入门】【18p】
- 【P069-P083】大数据Hadoop教程-学习笔记05【Apache Hive DML语句与函数使用】【15p】
- 【P084-P096】大数据Hadoop教程-学习笔记06【Hadoop生态综合案例:陌陌聊天数据分析】【13p】
目录
01【Hive SQL DML语法之加载数据】
P069【01-课程内容大纲与学习的目标】
P070【02-Hive SQL-DML-Load加载数据操作】
P071【03-Hive SQL-DML-Insert插入数据】
02【Hive SQL DML语法之查询数据】
P072【04-Hive SQL-DML-Select查询--语法树与学习环境准备】
P073【05-Hive SQL-DML-Select查询--列表达式与distinct去重】
P074【06-Hive SQL-DML-Select查询--Where条件过滤】
P075【07-Hive SQL-DML-Select查询--聚合操作aggregate】
P076【08-Hive SQL-DML-Select查询--Group by分组及语法限制】
P077【09-Hive SQL-DML-Select查询--Having过滤操作】
P078【10-Hive SQL-DML-Select查询--Order by排序】
P079【11-Hive SQL-DML-Select查询--Limit限制语法】
P080【12-Hive SQL-DML-Select查询--执行顺序梳理】
03【Hive SQL Join关联查询】
P081【13-Hive SQL Join关联查询】
04【Hive SQL中的常用函数使用入门】
P082【14-Hive函数概述及分类标准】
P083【15-Hive常用的内置函数】
01【Hive SQL DML语法之加载数据】
P069【01-课程内容大纲与学习的目标】
目录
- Hive SQL DML语法之加载数据
- Hive SQL DML语法之查询数据
- Hive SQL Join关联查询
- Hive SQL中的函数使用
学习目标
- 掌握Hive SQL Load加载数据语句
- 掌握Hive SQL Insert插入数据语句
- 掌握Hive SQL Select基础查询语句
- 掌握Hive SQL Join查询语句
- 掌握Hive SQL 常用函数的使用
P070【02-Hive SQL-DML-Load加载数据操作】
连接成功
Last login: Thu Feb 23 22:01:26 2023 from 192.168.88.1
[root@node1 ~]# pwd
/root
[root@node1 ~]# ll
总用量 84
-rw-r--r-- 1 root root 2 2月 21 21:14 1.txt
-rw-r--r-- 1 root root 4 2月 22 11:03 666.txt
-rw-------. 1 root root 1340 9月 11 2020 anaconda-ks.cfg
-rw-r--r-- 1 root root 34 2月 21 21:36 hello.txt
-rw------- 1 root root 66920 2月 23 22:05 nohup.out
[root@node1 ~]# mkdir hivedata
[root@node1 ~]# cd hivedata/
[root@node1 hivedata]# ll
总用量 0
[root@node1 hivedata]# vim 1.txt
[root@node1 hivedata]# cat 1.txt
1,allen,18
2,james,22
3,kobe,33
[root@node1 hivedata]# jps
7949 Jps
[root@node1 hivedata]# start-all.sh
Starting namenodes on [node1]
上一次登录:五 2月 24 10:54:43 CST 2023从 192.168.88.1pts/1 上
Starting datanodes
上一次登录:五 2月 24 11:00:11 CST 2023pts/0 上
Starting secondary namenodes [node2]
上一次登录:五 2月 24 11:00:14 CST 2023pts/0 上
Starting resourcemanager
上一次登录:五 2月 24 11:00:21 CST 2023pts/0 上
Starting nodemanagers
上一次登录:五 2月 24 11:00:32 CST 2023pts/0 上
[root@node1 hivedata]# jps
8432 NameNode
9640 NodeManager
9944 Jps
9420 ResourceManager
8622 DataNode
[root@node1 hivedata]# nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
[root@node1 ~]# jps
8432 NameNode
9640 NodeManager
11515 RunJar
9420 ResourceManager
14333 Jps
8622 DataNode
[root@node1 ~]# nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
[1] 14827
[root@node1 ~]# nohup: 忽略输入并把输出追加到"nohup.out"
[root@node1 ~]# jps
8432 NameNode
15045 Jps
9640 NodeManager
11515 RunJar
14827 RunJar
9420 ResourceManager
8622 DataNode
[root@node1 ~]#
连接成功
Last login: Fri Feb 24 11:00:35 2023
[root@node1 ~]# jps
8432 NameNode
9640 NodeManager
11515 RunJar
9420 ResourceManager
14333 Jps
8622 DataNode
[root@node1 ~]# nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
[1] 14827
[root@node1 ~]# nohup: 忽略输入并把输出追加到"nohup.out"
[root@node1 ~]# jps
8432 NameNode
15045 Jps
9640 NodeManager
11515 RunJar
14827 RunJar
9420 ResourceManager
8622 DataNode
[root@node1 ~]# hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
[root@node1 ~]# cat 1.txt
1
[root@node1 ~]# cd hivedata/
[root@node1 hivedata]# hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
put: `/user/hive/warehouse/itheima.db/t_1/1.txt': File exists
[root@node1 hivedata]# hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
[root@node1 hivedata]# 连接成功
Last login: Fri Feb 24 10:57:54 2023 from 192.168.88.1
[root@node3 ~]# /export/server/apache-hive-3.1.2-bin/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000> use itheima;
INFO : Compiling command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd): use itheima
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd); Time taken: 1.394 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd): use itheima
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224110613_71182481-e89c-49d0-819f-02beec470edd); Time taken: 0.08 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (1.841 seconds)
0: jdbc:hive2://node1:10000> create table t_1(id int, name string, age int) row format delimited fields terminated by ',';
INFO : Compiling command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045): create table t_1(id int, name string, age int) row format delimited fields terminated by ','
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045); Time taken: 0.225 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045): create table t_1(id int, name string, age int) row format delimited fields terminated by ','
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224111148_4be457ef-f056-4714-9e5e-c1870296f045); Time taken: 2.87 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (3.142 seconds)
0: jdbc:hive2://node1:10000> hadoop fs -put 1.txt /user/hive/warehouse/itheima.db/t_1
. . . . . . . . . . . . . .> ;
Error: Error while compiling statement: FAILED: ParseException line 1:0 cannot recognize input near 'hadoop' 'fs' '-' (state=42000,code=40000)
0: jdbc:hive2://node1:10000> select * from t_1;
INFO : Compiling command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7): select * from t_1
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_1.id, type:int, comment:null), FieldSchema(name:t_1.name, type:string, comment:null), FieldSchema(name:t_1.age, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7); Time taken: 2.749 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7): select * from t_1
INFO : Completed executing command(queryId=root_20230224111528_87b64e1a-d9dd-4c7b-ac15-c73bb7830cc7); Time taken: 0.005 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------+-----------+----------+
| t_1.id | t_1.name | t_1.age |
+---------+-----------+----------+
| 1 | NULL | NULL |
+---------+-----------+----------+
1 row selected (3.728 seconds)
0: jdbc:hive2://node1:10000> select * from t_1;
INFO : Compiling command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944): select * from t_1
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_1.id, type:int, comment:null), FieldSchema(name:t_1.name, type:string, comment:null), FieldSchema(name:t_1.age, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944); Time taken: 0.298 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944): select * from t_1
INFO : Completed executing command(queryId=root_20230224111713_190a3ed2-60b4-497a-b492-14e3d04ab944); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------+-----------+----------+
| t_1.id | t_1.name | t_1.age |
+---------+-----------+----------+
| 1 | allen | 18 |
| 2 | james | 22 |
| 3 | kobe | 33 |
+---------+-----------+----------+
3 rows selected (0.464 seconds)
0: jdbc:hive2://node1:10000> LOCAL本地是哪里?
本地文件系统指的是Hiveserver2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统。
node1:安装hive、启动了metastore服务与hiveServer2服务
node3:客户端
load data local,local:不是客户端所在的本地,而是hive服务器所在的本地;只要访问的是node1这台服务器上运行的hive服务,加载数据时local本地指的就是从node1这台linux加载的本地文件系统。
node1
start-all.sh
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
jps
node3
/export/server/apache-hive-3.1.2-bin/bin/beeline
! connect jdbc:hive2://node1:10000
root
node3
use itheima;
show tables;
load data local inpath '/root/hivedata/students.txt' into table itheima.student_local;
select * from student_local;
[root@node3 ~]# /export/server/apache-hive-3.1.2-bin/bin/beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000> use itheima;
INFO : Compiling command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061): use itheima
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061); Time taken: 0.028 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061): use itheima
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224150749_0991ca1a-f503-44a6-a7f1-74ac128de061); Time taken: 0.015 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.127 seconds)
0: jdbc:hive2://node1:10000> show tables;
INFO : Compiling command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b): show tables
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b); Time taken: 0.028 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224150754_7e131858-4f7a-45c5-ac4c-197fb0ef187b); Time taken: 0.009 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------------------+
| tab_name |
+---------------------+
| student_hdfs |
| student_local |
| t_1 |
| t_archer |
| t_archer1 |
| t_team_ace_player |
| t_team_ace_player2 |
+---------------------+
7 rows selected (0.11 seconds)
0: jdbc:hive2://node1:10000> load data local inpath '/root/hivedata/students.txt' into table itheima.student_local;
INFO : Compiling command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd): load data local inpath '/root/hivedata/students.txt' into table itheima.student_local
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd); Time taken: 0.183 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd): load data local inpath '/root/hivedata/students.txt' into table itheima.student_local
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table itheima.student_local from file:/root/hivedata/students.txt
INFO : Starting task [Stage-1:STATS] in serial mode
INFO : Completed executing command(queryId=root_20230224151134_e01df8a4-14fb-4474-bc35-f751d8a54bcd); Time taken: 0.571 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.77 seconds)
0: jdbc:hive2://node1:10000> select * from student_local;
INFO : Compiling command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e): select * from student_local
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student_local.num, type:int, comment:null), FieldSchema(name:student_local.name, type:string, comment:null), FieldSchema(name:student_local.sex, type:string, comment:null), FieldSchema(name:student_local.age, type:int, comment:null), FieldSchema(name:student_local.dept, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e); Time taken: 0.352 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e): select * from student_local
INFO : Completed executing command(queryId=root_20230224151258_71d2f260-469d-483b-a451-3e34008ab22e); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+--------------------+---------------------+--------------------+--------------------+---------------------+
| student_local.num | student_local.name | student_local.sex | student_local.age | student_local.dept |
+--------------------+---------------------+--------------------+--------------------+---------------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95009 | 梦圆圆 | 女 | 18 | MA |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95012 | 孙花 | 女 | 20 | CS |
| 95013 | 冯伟 | 男 | 21 | CS |
| 95014 | 王小丽 | 女 | 19 | CS |
| 95015 | 王君 | 男 | 18 | MA |
| 95016 | 钱国 | 男 | 21 | MA |
| 95017 | 王风娟 | 女 | 18 | IS |
| 95018 | 王一 | 女 | 19 | IS |
| 95019 | 邢小丽 | 女 | 19 | IS |
| 95020 | 赵钱 | 男 | 21 | IS |
| 95021 | 周二 | 男 | 17 | MA |
| 95022 | 郑明 | 男 | 20 | MA |
+--------------------+---------------------+--------------------+--------------------+---------------------+
22 rows selected (0.581 seconds)
0: jdbc:hive2://node1:10000> select * from student_hdfs;
INFO : Compiling command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23): select * from student_hdfs
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student_hdfs.num, type:int, comment:null), FieldSchema(name:student_hdfs.name, type:string, comment:null), FieldSchema(name:student_hdfs.sex, type:string, comment:null), FieldSchema(name:student_hdfs.age, type:int, comment:null), FieldSchema(name:student_hdfs.dept, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23); Time taken: 0.244 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23): select * from student_hdfs
INFO : Completed executing command(queryId=root_20230224152251_0333fd6a-7ecb-49dd-b5eb-d792308f8e23); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------+--------------------+-------------------+-------------------+--------------------+
| student_hdfs.num | student_hdfs.name | student_hdfs.sex | student_hdfs.age | student_hdfs.dept |
+-------------------+--------------------+-------------------+-------------------+--------------------+
+-------------------+--------------------+-------------------+-------------------+--------------------+
No rows selected (0.299 seconds)
0: jdbc:hive2://node1:10000> load data inpath '/students.txt' into table itheima.student_hdfs;
INFO : Compiling command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807): load data inpath '/students.txt' into table itheima.student_hdfs
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807); Time taken: 0.073 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807): load data inpath '/students.txt' into table itheima.student_hdfs
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table itheima.student_hdfs from hdfs://node1:8020/students.txt
INFO : Starting task [Stage-1:STATS] in serial mode
INFO : Completed executing command(queryId=root_20230224152540_1eafbf79-52a6-4846-8b2a-e1412b020807); Time taken: 0.468 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.552 seconds)
0: jdbc:hive2://node1:10000> select * from student_hdfs;
INFO : Compiling command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db): select * from student_hdfs
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student_hdfs.num, type:int, comment:null), FieldSchema(name:student_hdfs.name, type:string, comment:null), FieldSchema(name:student_hdfs.sex, type:string, comment:null), FieldSchema(name:student_hdfs.age, type:int, comment:null), FieldSchema(name:student_hdfs.dept, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db); Time taken: 0.255 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db): select * from student_hdfs
INFO : Completed executing command(queryId=root_20230224152626_dcf0cf77-73b5-4e51-ab0e-64d00653c5db); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------+--------------------+-------------------+-------------------+--------------------+
| student_hdfs.num | student_hdfs.name | student_hdfs.sex | student_hdfs.age | student_hdfs.dept |
+-------------------+--------------------+-------------------+-------------------+--------------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95009 | 梦圆圆 | 女 | 18 | MA |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95012 | 孙花 | 女 | 20 | CS |
| 95013 | 冯伟 | 男 | 21 | CS |
| 95014 | 王小丽 | 女 | 19 | CS |
| 95015 | 王君 | 男 | 18 | MA |
| 95016 | 钱国 | 男 | 21 | MA |
| 95017 | 王风娟 | 女 | 18 | IS |
| 95018 | 王一 | 女 | 19 | IS |
| 95019 | 邢小丽 | 女 | 19 | IS |
| 95020 | 赵钱 | 男 | 21 | IS |
| 95021 | 周二 | 男 | 17 | MA |
| 95022 | 郑明 | 男 | 20 | MA |
+-------------------+--------------------+-------------------+-------------------+--------------------+
22 rows selected (0.313 seconds)
0: jdbc:hive2://node1:10000> P071【03-Hive SQL-DML-Insert插入数据】
create table t_2(id int, name string);
insert into table t_2 values(1, "zhangsan"); 语法支持,但运行速度太慢!
select * from t_2;

0: jdbc:hive2://node1:10000> create table t_2(id int, name string);
INFO : Compiling command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e): create table t_2(id int, name string)
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e); Time taken: 0.027 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e): create table t_2(id int, name string)
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20230224154557_9d1559c6-d7df-42cb-a0e2-5957691cf26e); Time taken: 0.109 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.164 seconds)
0: jdbc:hive2://node1:10000> insert into table t_2 values(1, "zhangsan");
INFO : Compiling command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a): insert into table t_2 values(1, "zhangsan")
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col1, type:int, comment:null), FieldSchema(name:col2, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a); Time taken: 0.773 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a): insert into table t_2 values(1, "zhangsan")
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a
INFO : Total jobs = 3
INFO : Launching Job 1 out of 3
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1677220144667_0001
INFO : Executing with tokens: []
INFO : The url to track the job: http://node1:8088/proxy/application_1677220144667_0001/
INFO : Starting Job = job_1677220144667_0001, Tracking URL = http://node1:8088/proxy/application_1677220144667_0001/
INFO : Kill Command = /export/server/hadoop-3.3.0/bin/mapred job -kill job_1677220144667_0001
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2023-02-24 15:49:20,742 Stage-1 map = 0%, reduce = 0%
INFO : 2023-02-24 15:49:32,536 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.82 sec
INFO : 2023-02-24 15:49:54,617 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.2 sec
INFO : MapReduce Total cumulative CPU time: 10 seconds 200 msec
INFO : Ended Job = job_1677220144667_0001
INFO : Starting task [Stage-7:CONDITIONAL] in serial mode
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Starting task [Stage-4:MOVE] in serial mode
INFO : Moving data to directory hdfs://node1:8020/user/hive/warehouse/itheima.db/t_2/.hive-staging_hive_2023-02-24_15-48-28_204_7443762290621652108-3/-ext-10000 from hdfs://node1:8020/user/hive/warehouse/itheima.db/t_2/.hive-staging_hive_2023-02-24_15-48-28_204_7443762290621652108-3/-ext-10002
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table itheima.t_2 from hdfs://node1:8020/user/hive/warehouse/itheima.db/t_2/.hive-staging_hive_2023-02-24_15-48-28_204_7443762290621652108-3/-ext-10000
INFO : Starting task [Stage-2:STATS] in serial mode
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 10.2 sec HDFS Read: 15250 HDFS Write: 241 SUCCESS
INFO : Total MapReduce CPU Time Spent: 10 seconds 200 msec
INFO : Completed executing command(queryId=root_20230224154828_64f89674-71a6-413f-8c8d-fbd37f2fba7a); Time taken: 88.299 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (89.096 seconds)
0: jdbc:hive2://node1:10000> select * from t_2;
INFO : Compiling command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3): select * from t_2
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_2.id, type:int, comment:null), FieldSchema(name:t_2.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3); Time taken: 0.224 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3): select * from t_2
INFO : Completed executing command(queryId=root_20230224155036_23fdd103-4a07-4232-aa48-c94335756fe3); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------+-----------+
| t_2.id | t_2.name |
+---------+-----------+
| 1 | zhangsan |
+---------+-----------+
1 row selected (0.275 seconds)
0: jdbc:hive2://node1:10000> show databases;
use itheima;
------------Hive SQL-DML-Load加载数据---------------
--step1:建表
--建表student_local 用于演示从本地加载数据
create table student_local(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
--建表student_HDFS 用于演示从HDFS加载数据
create table student_HDFS(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
--建议使用beeline客户端 可以显示出加载过程日志信息
--step2:加载数据
-- 从本地加载数据 数据位于HS2(node1)本地文件系统 本质是hadoop fs -put上传操作
LOAD DATA LOCAL INPATH '/root/hivedata/students.txt' INTO TABLE student_local;
--从HDFS加载数据 数据位于HDFS文件系统根目录下 本质是hadoop fs -mv 移动操作
--先把数据上传到HDFS上 hadoop fs -put /root/hivedata/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;
------------Hive SQL-DML-Insert插入数据-----------------
--step1:创建一张源表student
drop table if exists student;
create table student(num int,name string,sex string,age int,dept string)
row format delimited fields terminated by ',';
--step2:加载数据
load data local inpath '/root/hivedata/students.txt' into table student;
select * from student;
--step3:创建一张目标表 只有两个字段
create table student_from_insert(sno int, sname string);
--使用insert+select插入数据到新表中
insert into table student_from_insert select num, name from student;
select * from student_from_insert;02【Hive SQL DML语法之查询数据】
P072【04-Hive SQL-DML-Select查询--语法树与学习环境准备】
Select语法树
- 从哪里查询取决于FROM关键字后面的table_reference,这是我们写查询SQL的首先要确定的事即你查询谁?
- 表名和列名不区分大小写。


------------Hive SQL select查询基础语法------------
--创建表t_usa_covid19
drop table if exists t_usa_covid19;
CREATE TABLE t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
row format delimited fields terminated by ",";
--将数据load加载到t_usa_covid19表对应的路径下
load data local inpath '/root/hivedata/us-covid19-counties.dat' into table t_usa_covid19;
--1、select_expr
--查询所有字段或者指定字段
select * from t_usa_covid19;P073【05-Hive SQL-DML-Select查询--列表达式与distinct去重】
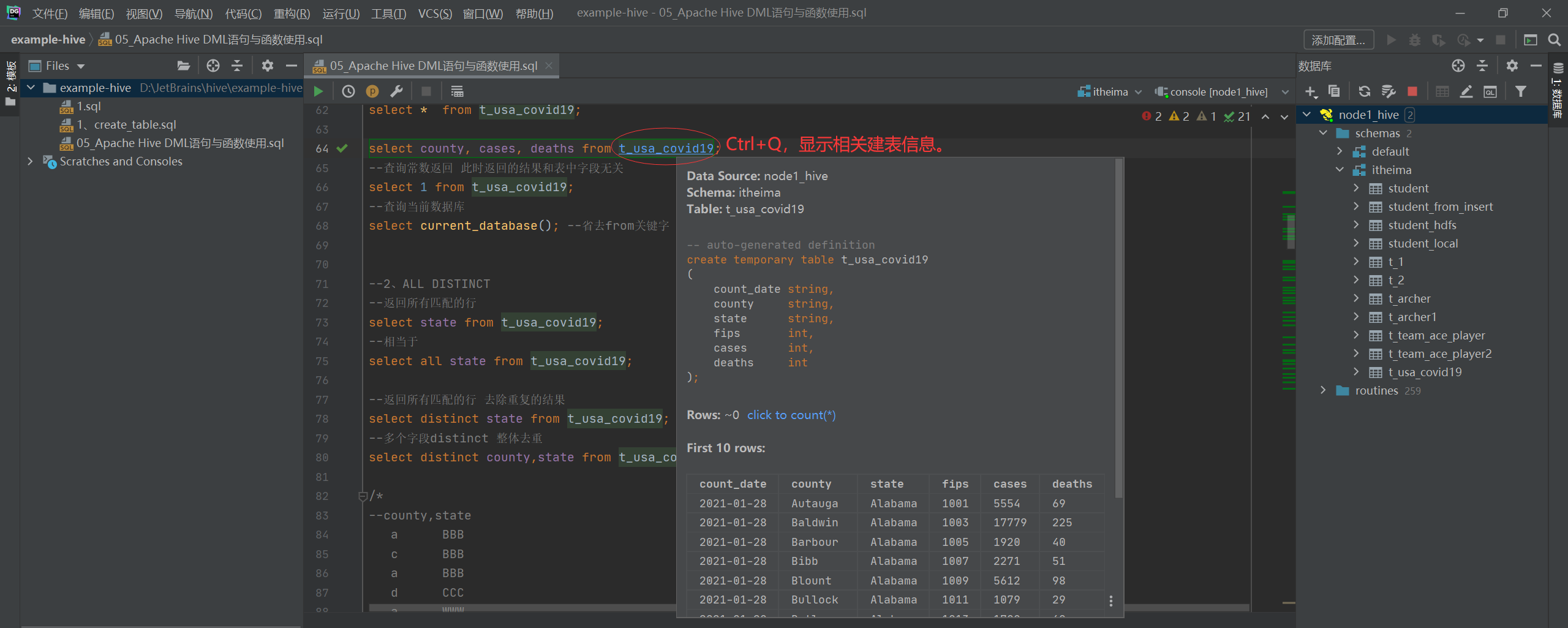
--1、select_expr
--查询所有字段或者指定字段
select * from t_usa_covid19;
select county, cases, deaths from t_usa_covid19;
--查询常数返回 此时返回的结果和表中字段无关
select 1 from t_usa_covid19;
--查询当前数据库
select current_database(); --省去from关键字
--2、ALL DISTINCT
--返回所有匹配的行
select state from t_usa_covid19;
--相当于
select all state from t_usa_covid19;
--返回所有匹配的行 去除重复的结果
select distinct state from t_usa_covid19;
--多个字段distinct 整体去重
select distinct county,state from t_usa_covid19;
/*
--county, state
a BBB
c BBB
a BBB
d CCC
a WWW
a BBB
c BBB
d CCC
*/P074【06-Hive SQL-DML-Select查询--Where条件过滤】
--3、WHERE CAUSE
select * from t_usa_covid19 where 1 > 2; -- 1 > 2 返回false
select * from t_usa_covid19 where 1 = 1; -- 1 = 1 返回true
--找出来自于California州的疫情数据
select * from t_usa_covid19 where state = 'California';
--where条件中使用函数 找出州名字母长度超过10位的有哪些
select * from t_usa_covid19 where length(state) >10 ;P075【07-Hive SQL-DML-Select查询--聚合操作aggregate】
--4、聚合操作
select county from t_usa_covid19;
select count(county) from t_usa_covid19;
--统计美国总共有多少个县county
select county as itcast from t_usa_covid19;
--学会使用as给查询返回的结果起个别名
select count(county) as county_cnts from t_usa_covid19;
--去重distinct
select count(distinct county) as county_cnts from t_usa_covid19;
--统计美国加州有多少个县
select count(county) from t_usa_covid19 where state = "California";
--统计德州总死亡病例数
select sum(deaths) from t_usa_covid19 where state = "Texas";
--统计出美国最高确诊病例数是哪个县
select max(cases) from t_usa_covid19;P076【08-Hive SQL-DML-Select查询--Group by分组及语法限制】
--5、GROUP BY
select * from t_usa_covid19;
--根据state州进行分组 统计每个州有多少个县county
select count(county) from t_usa_covid19 where count_date = "2021-01-28" group by state;
--想看一下统计的结果是属于哪一个州的
select state,count(county) as county_nums from t_usa_covid19 where count_date = "2021-01-28" group by state;
--再想看一下每个县的死亡病例数,我们猜想很简单呀 把deaths字段加上返回 真实情况如何呢?
select state,count(county),sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" group by state;
--很尴尬 sql报错了org.apache.hadoop.hive.ql.parse.SemanticException:Line 1:27 Expression not in GROUP BY key 'deaths'
--为什么会报错??group by的语法限制
--结论:出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段。
--deaths不是分组字段 报错
--state是分组字段 可以直接出现在select_expr中
--被聚合函数应用
select state,count(county),sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" group by state;P077【09-Hive SQL-DML-Select查询--Having过滤操作】
--6、having
--统计2021-01-28死亡病例数大于10000的州
select state,sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" and sum(deaths) >10000 group by state;
--where语句中不能使用聚合函数,语法报错,所以使用having函数!
--先where分组前过滤,再进行group by分组, 分组后每个分组结果集确定 再使用having过滤
select state,sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" group by state having sum(deaths) > 10000;
--这样写更好 即在group by的时候聚合函数已经作用得出结果 having直接引用结果过滤 不需要再单独计算一次了
select state,sum(deaths) as cnts from t_usa_covid19 where count_date = "2021-01-28" group by state having cnts> 10000;P078【10-Hive SQL-DML-Select查询--Order by排序】
--7、order by
--根据确诊病例数升序排序 查询返回结果
select * from t_usa_covid19 ;
select * from t_usa_covid19 order by cases;
--不写排序规则 默认就是asc升序
select * from t_usa_covid19 order by cases asc;
--根据死亡病例数倒序排序 查询返回加州每个县的结果
select * from t_usa_covid19 where state = "California" order by cases desc;P079【11-Hive SQL-DML-Select查询--Limit限制语法】
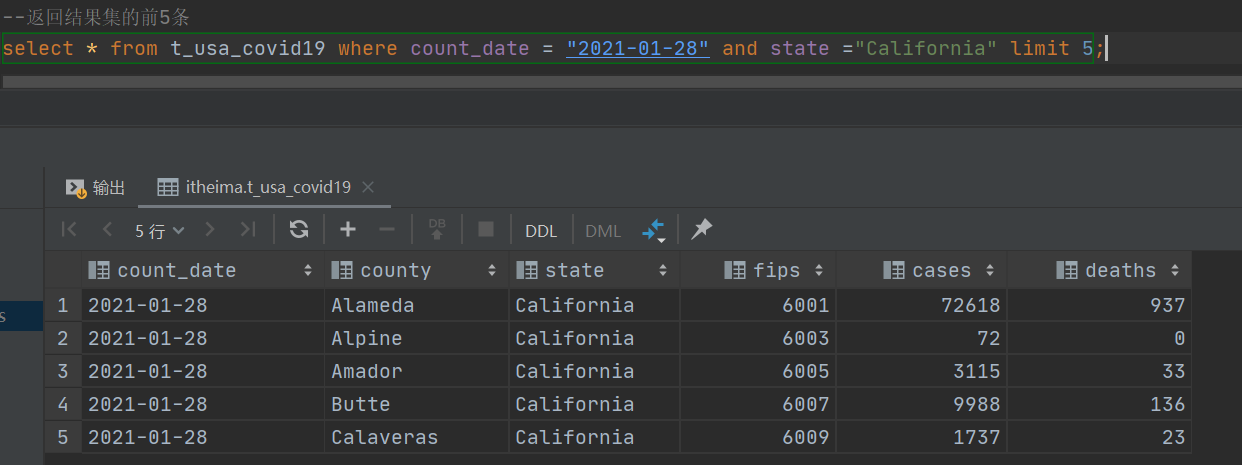
--8、limit
--没有限制返回2021.1.28 加州的所有记录
select * from t_usa_covid19 where count_date = "2021-01-28" and state ="California";
--返回结果集的前5条
select * from t_usa_covid19 where count_date = "2021-01-28" and state ="California" limit 5;
--返回结果集从第1行开始 共3行
select * from t_usa_covid19 where count_date = "2021-01-28" and state ="California" limit 2,3;
--注意 第一个参数偏移量是从0开始的P080【12-Hive SQL-DML-Select查询--执行顺序梳理】
--执行顺序
select state,sum(deaths) as cnts from t_usa_covid19
where count_date = "2021-01-28"
group by state
having cnts> 10000
limit 2;03【Hive SQL Join关联查询】
P081【13-Hive SQL Join关联查询】
在Hive中,使用最多最重要的两种join分别是:inner join(内连接)、left join(左连接)。
employee.txt
1201,gopal,manager,50000,TP
1202,manisha,cto,50000,TP
1203,khalil,dev,30000,AC
1204,prasanth,dev,30000,AC
1206,kranthi,admin,20000,TPemployee_address.txt
1201,288A,vgiri,jublee
1202,108I,aoc,ny
1204,144Z,pgutta,hyd
1206,78B,old city,la
1207,720X,hitec,nyemployee_connection.txt
1201,2356742,gopal@tp.com
1203,1661663,manisha@tp.com
1204,8887776,khalil@ac.com
1205,9988774,prasanth@ac.com
1206,1231231,kranthi@tp.com
------------Hive Join SQL 语法------------
--Join语法练习 建表
drop table if exists employee_address;
drop table if exists employee_connection;
drop table if exists employee;
--table1: 员工表
CREATE TABLE employee(
id int,
name string,
deg string,
salary int,
dept string
) row format delimited
fields terminated by ',';
--table2:员工家庭住址信息表
CREATE TABLE employee_address (
id int,
hno string,
street string,
city string
) row format delimited
fields terminated by ',';
--table3:员工联系方式信息表
CREATE TABLE employee_connection (
id int,
phno string,
email string
) row format delimited
fields terminated by ',';
--加载数据到表中
load data local inpath '/root/hivedata/employee.txt' into table employee;
load data local inpath '/root/hivedata/employee_address.txt' into table employee_address;
load data local inpath '/root/hivedata/employee_connection.txt' into table employee_connection;
select * from employee;
select * from employee_address;
select * from employee_connection;
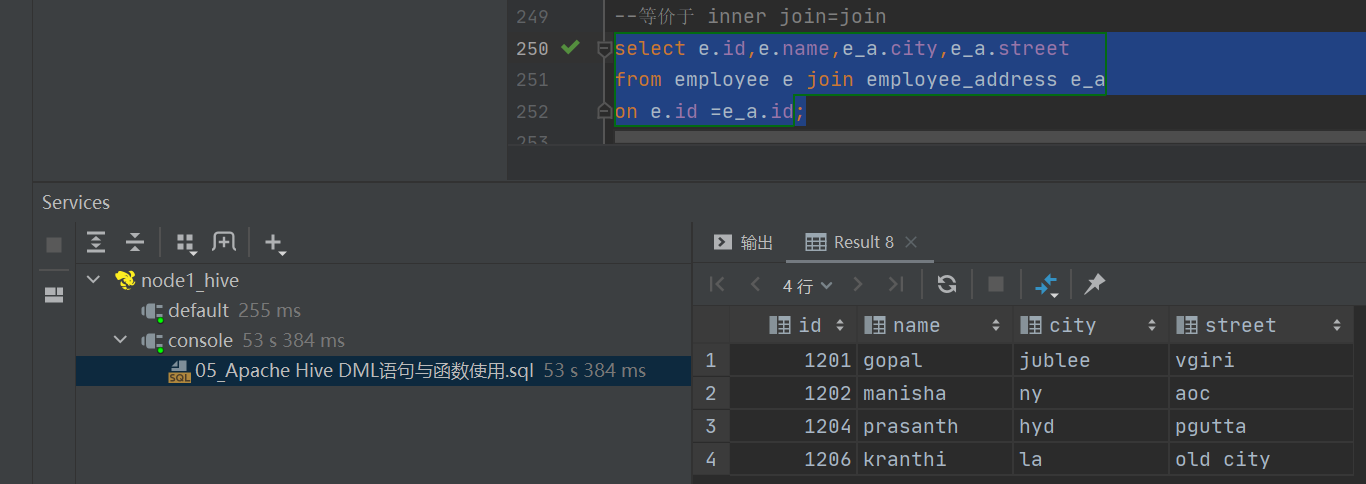
--1、inner join
select e.id,e.name,e_a.city,e_a.street
from employee e inner join employee_address e_a
on e.id =e_a.id;
--等价于 inner join=join
select e.id,e.name,e_a.city,e_a.street
from employee e join employee_address e_a
on e.id =e_a.id;
--等价于 隐式连接表示法
select e.id,e.name,e_a.city,e_a.street
from employee e , employee_address e_a
where e.id = e_a.id;
--2、left join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left join employee_connection e_conn
on e.id = e_conn.id;
--等价于 left outer join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left outer join employee_connection e_conn
on e.id = e_conn.id;04【Hive SQL中的常用函数使用入门】
P082【14-Hive函数概述及分类标准】
概述
Hive内建了不少函数,用于满足用户不同使用需求,提高SQL编写效率。
- 使用show functions查看当下可用的所有函数;
- 通过describe function extended funcname来查看函数的使用方式。
分类标准
Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF(User-Defined Functions):
- 内置函数可分为:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
- 用户定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF。
P083【15-Hive常用的内置函数】
概述
- 内置函数(build-in)指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。
- 官方文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
- 内置函数根据应用归类整体可以分为8大种类型,我们将对其中重要的,使用频率高的函数使用进行详细讲解。
- String Functions,字符串函数
- Date Functions,日期函数
- Mathematical Functions,数学函数
- Conditional Functions,条件函数
-----------------Hive 常用的内置函数----------------------
show functions;
describe function extended count;
------------String Functions 字符串函数------------
select length("itcast");
select reverse("itcast");
select concat("angela", "baby");
--带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('itcast', 'cn'));
--字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])
select substr("angelababy", -2); --pos是从1开始的索引,如果为负数则倒着数
select substr("angelababy", 2, 2);
--分割字符串函数: split(str, regex)
--split针对字符串数据进行切割,返回的是数组array,可以通过数组的下标取内部的元素,注意下标是从0开始的
select split('apache hive', ' ');
select split('apache hive', ' ')[0];
select split('apache hive', ' ')[1];
----------- Date Functions 日期函数 -----------------
--获取当前日期: current_date
select current_date();
--获取当前UNIX时间戳函数: unix_timestamp
select unix_timestamp();
--日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp("2011-12-07 13:01:03");
--指定格式日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp('20111207 13:01:03', 'yyyyMMdd HH:mm:ss');
--UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');
--日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08', '2012-05-09');
--日期增加函数: date_add
select date_add('2012-02-28', 10);
--日期减少函数: date_sub
select date_sub('2012-01-1', 10);
----Mathematical Functions 数学函数-------------
--取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926, 4);
--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
-----Conditional Functions 条件函数------------------
--使用之前课程创建好的student表数据
select * from student limit 3;
--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1 = 2, 100, 200);
select if(sex = '男', 'M', 'W') from student limit 3;
--空值转换函数: nvl(T value, T default_value)
select nvl("allen", "itcast");
select nvl(null, "itcast");
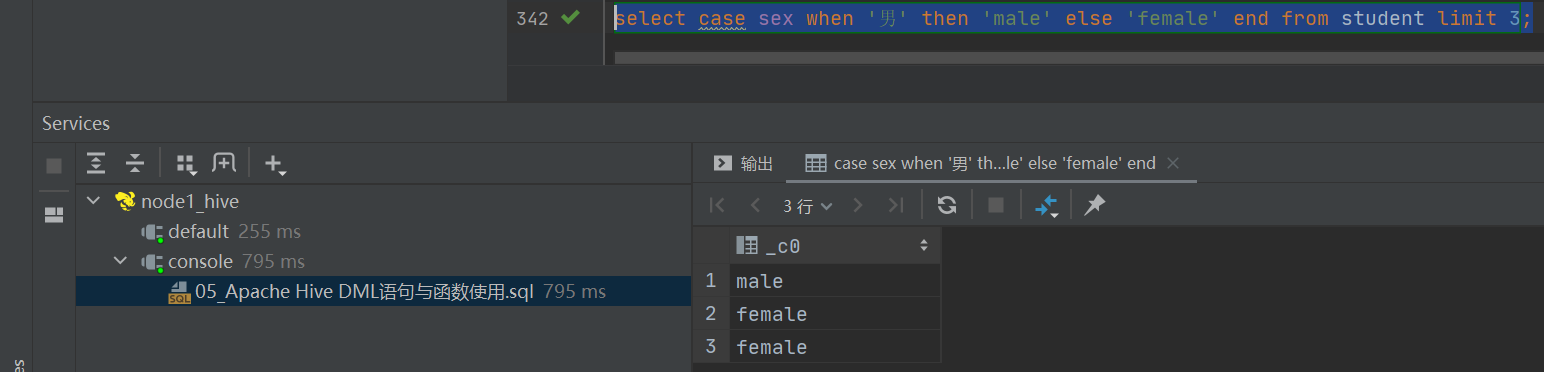
--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'male' else 'female' end from student limit 3;