Netty自定义协议
- 一、Netty自定义协议
- 二、 协议设计
- 三、 协议实现
- 编码:
- 解码:
- 时间轮算法
- Netty中的时间轮
一、Netty自定义协议
公有协议(http、tcp)、私有协议(自己定义的,不是行业标准)
我们知道使用最为广泛的是HTTP协议,但是在一些服务交互领域,其使用则相对较少,主要原因有三方面:
1、HTTP协议会携带诸如header和cookie等信息,其本身对字节的利用率较低,这使得HTTP协议比较臃肿,在承载相同信息的情况下,HTTP协议将需要发送更多的数据包;
2、HTTP协议是基于TCP的短连接,在每次请求响应后就断开了连接,下次请求需再次建立新连接,由于服务端的交互设计一般都要求能够承载高并发的请求,因而HTTP协议性能不佳;
3、服务之间往往有一些根据其自身业务特性所独有的需求,而HTTP协议无法很好的服务于这些业务需求;
基于这些原因,一般的服务之间进行交互时都会使用自定义协议,常见的框架比如dubbo就实现了符合其自身业务需求的协议;
二、 协议设计
协议本质上是定义了一个将数据转换为字节或者将字节转换为数据的一个规范和格式,自定义协议一般包含两个部分:消息头和消息体;
消息头定义了消息的一些公有信息,比如当前服务的版本,消息的sessionId,消息的类型等等,消息头的长度一般是固定的或者说是可确定的;
消息体主要是消息所需要发送的内容,一般在消息头的最后的字节中保存当前消息的消息体的长度;
下面是设计一个自定义协议的举例:
1、魔数 magicNumber
2、主版本号 mainVersion
3、次版本号 subVersion
4、修订版本号 modifyVersion
5、会话id sessionId
6、消息类型 messageType
7、附加数据 attachments
8、消息体长度 length
9、消息体 data
对应到Java开发中,可以用一个类来承载这些信息:
public class Message {
private int magicNumber;
private byte mainVersion;
private byte subVersion;
private byte modifyVersion;
private String sessionId;
private MessageTypeEnum messageType;
private Map<String, String> attachments = new HashMap<>();
private Object data;
}
三、 协议实现
自定义协议就是根据定义的协议规范,将消息转换为相应的字节流,然后由TCP传输到目标服务器,目标服务器也根据同样的协议规范将字节流转换为相应的消息,这样就达到了相互交互通信的目的,如何基于该规范将消息转换为字节流和将字节流转换为消息?Netty提供了ByteToMessageDecoder和
MessageToByteEncoder用于进行消息和字节流的相互转换;
编码:
@Override
protected void encode(ChannelHandlerContext ctx, Message message, ByteBuf out) {
System.out.println("报文编码前:\n" + message);
// 判断消息类型,如果是EMPTY类型,则表示当前消息不需要写入到管道中
if (message.getMessageType() != MessageTypeEnum.EMPTY) {
out.writeInt(Constants.MAGIC_NUMBER); // 写入当前的魔数
out.writeByte(Constants.MAIN_VERSION); // 写入当前的主版本号
out.writeByte(Constants.SUB_VERSION); // 写入当前的次版本号
out.writeByte(Constants.MODIFY_VERSION); // 写入当前的修订版本号
if (StringUtils.isNotEmpty(message.getSessionId())) {
String sessionId = UUID.randomUUID().toString();
message.setSessionId(sessionId);
out.writeCharSequence(sessionId, Charset.defaultCharset());
} else {
//先暂时写死一个固定36位的uuid
message.setSessionId("fdda50c1-c483-4395-8f84-6cb692b8664c");
out.writeCharSequence("fdda50c1-c483-4395-8f84-6cb692b8664c", Charset.defaultCharset());
}
out.writeByte(message.getMessageType().getType()); // 写入当前消息的类型
out.writeShort(message.getAttachments().size()); // 写入当前消息的附加参数数量
message.getAttachments().forEach((key, value) -> {
Charset charset = Charset.defaultCharset();
out.writeInt(key.length()); // 写入键的长度
out.writeCharSequence(key, charset); // 写入键数据
out.writeInt(value.length()); // 希尔值的长度
out.writeCharSequence(value, charset); // 写入值数据
});
if (null == message.getData()) {
out.writeInt(0); // 如果消息体为空,则写入0,表示消息体长度为0
} else {
byte[] bytes = SerializeUtil.serialize(message.getData());
out.writeInt(bytes.length);
out.writeBytes(bytes);
}
}
}
解码:
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf byteBuf, List<Object> out) throws Exception {
Message message = new Message();
message.setMagicNumber(byteBuf.readInt()); // 读取魔数
message.setMainVersion(byteBuf.readByte()); // 读取主版本号
message.setSubVersion(byteBuf.readByte()); // 读取次版本号
message.setModifyVersion(byteBuf.readByte()); // 读取修订版本号
CharSequence sessionId = byteBuf.readCharSequence(Constants.SESSION_ID_LENGTH, Charset.defaultCharset()); // 读取sessionId
message.setSessionId((String)sessionId);
message.setMessageType(MessageTypeEnum.get(byteBuf.readByte())); // 读取当前的消息类型
short attachmentSize = byteBuf.readShort(); // 读取附件长度
for (short i = 0; i < attachmentSize; i++) {
int keyLength = byteBuf.readInt(); // 读取键长度和数据
CharSequence key = byteBuf.readCharSequence(keyLength, Charset.defaultCharset());
int valueLength = byteBuf.readInt(); // 读取值长度和数据
CharSequence value = byteBuf.readCharSequence(valueLength, Charset.defaultCharset());
message.addAttachment(key.toString(), value.toString());
}
int dataLength = byteBuf.readInt(); // 读取消息体长度和数据
byte[] dataBytes = new byte[dataLength];
byteBuf.readBytes(dataBytes, 0, dataLength);
message.setData(SerializeUtil.unserialize(dataBytes));
System.out.println("报文解码后:\n" + message);
out.add(message);
}
时间轮算法
时间轮算法是用环形数组实现的,数组的每个元素称为槽,槽的内部用双向链表存储待执行的任务,添加和删除链表里面的任务的时间复杂度都是 O(1),槽本身也代表时间精度,比如一秒扫一个槽,那么这个时间轮的最高精度就是1秒,也就是说延迟1.5秒的任务和1.8秒的任务会被加入到同一个槽中,然后在1秒的时候遍历这个槽中的链表执行任务;
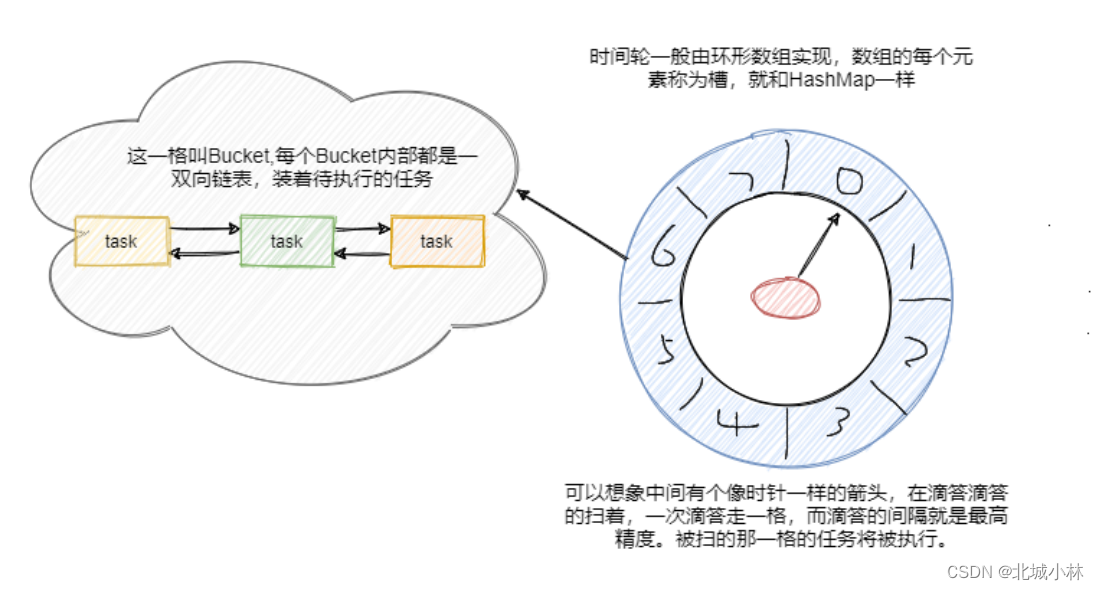
上图中指针指向的是第一个槽,一共有八个槽0~7,假设槽的时间单位为1秒,现在要加入一个延时5秒的任务,计算方式就是 5 % 8 + 1 = 6,即放在槽位为 6,下标为 5 的那个槽中,如果下标为5的槽已经有任务,则把任务拼到槽的双向链表的尾部;
然后每秒指针顺时针移动一格,这样就扫到了下一格,遍历这格中的双向链表执行任务,然后再循环依次继续;
如果要加入一个延迟50秒后执行的任务怎么办?
常见有两种处理方式,一种是增加轮次,50 % 8 + 1 = 3,即应该放在槽位是3,下标是2的位置,然后 (50 - 1) / 8 = 6,即轮数记为 6,也就是说当循环6轮之后扫到下标为2的这个槽位会触发该任务,Netty中的 HashedWheelTimer 使用的就是这种方式;
另外一种是增加层次,与手表相似,秒针走一圈,分针走一格,分针走一圈,时针走一格,多层次时间轮就是这样实现的,假设上图就是第一层,那么第一层走了一圈,第二层就走一格;
由此可知第二层的一格就是8秒,假设第二层也是 8 个槽,那么第二层走一圈,第三层走一格,可以得知第三层一格就是64秒,那么整个时间轮就可以处理最多延迟512秒的任务;
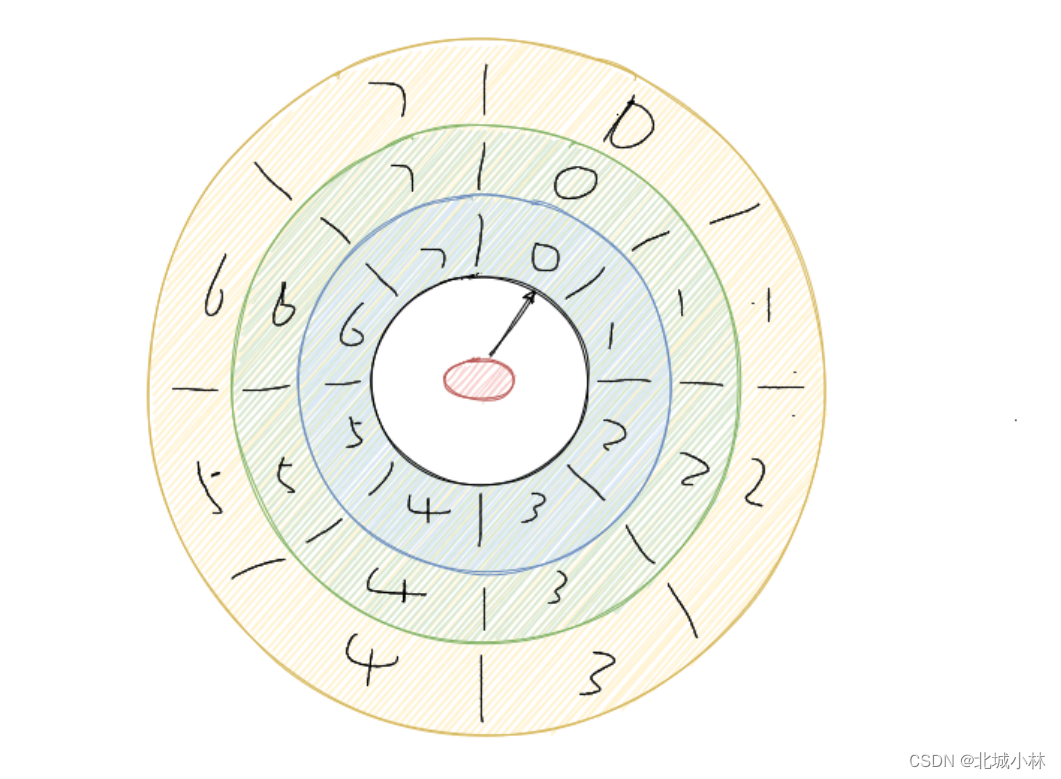
而多层次时间轮还会有降级的操作,假设一个任务延迟 500 秒执行,那么刚开始加进来肯定是放在第三层的,当时间过了 436 秒后,此时还需要 64 秒就会触发任务的执行,而此时相对而言它就是个延迟 64 秒后的任务,因此它会被降低放在第二层中,第一层还放不下它,再过个 56 秒,相对而言它就是个延迟 8 秒后执行的任务,因此它会再被降级放在第一层中等待执行,Kafka内部用的就是多层次的时间轮算法;
多层次时间轮算法相对比较复杂,Netty中没有使用这种方式;
Netty中的时间轮
在Netty中时间轮的实现类是HashedWheelTimer,代码中的wheel 就是上图的循环数组,tickDuration就是数组每一格的时间即精度,可以看到配备了一个工作线程来处理任务的执行;
通过源码分析,Netty的时间精度由 TickDuration 把控,并且工作线程除了处理执行到时的任务还做了其他操作,因此任务不一定会被精准的执行,并且任务的执行如果不是新起一个线程,或者将任务扔到线程池执行,那么耗时的任务会阻塞下个任务的执行;
另外Netty的时间轮算法会有很多无用的 tick 推进,例如 TickDuration 为1秒,此时一个延迟350秒的任务,那就是有349次无用的操作;
Netty时间轮的特点是对定时任务的执行不一定的精确的,适合于任务执行时间较短的情况,如果任务要执行的时间比较长,那么netty的时间轮执行任务会有时间上的误差,因为netty执行任务是单线程的,不是线程池,这样设计是为了大幅度减少维护定时任务的线程数;
使用Netty时间轮值需要创建和维护一个全局(一个服务)单例的HashedWheelTimer对象就可以了,不能在每个客户端连接上都创建一个;
HashedWheelTimer的底层数据结构是一个叫wheel的数组,时间轮的默认大小是512,即wheel数组默认512大小,数组的元素位置就是时间轮里所谓的槽位,可以配置槽位的时间间隔,Netty默认的配置是一个槽位代表100ms,而针对网络应用程序,大部分情况下,不需要额外定制这个时间参数,因为网络I/O的定时任务调度对时间的精确度要求没有那么高,本身网络就是不稳定的,所以这里你不需要额外配置什么,但是当定时任务是海量的时候,可以配置时间轮本身的大小,计算这个wheel大小,以减少时间轮的扫描轮数;
HashedWheelBucket 数组
HashedWheelTimeout 链表
![[Qt]QMainWindow](https://img-blog.csdnimg.cn/img_convert/cc02ebefe70544dba7d8280f323e340e.png)





![[go学习笔记.第十一章.项目案例] 1.家庭收支记账软件项目](https://img-blog.csdnimg.cn/7c2c3e9c709143d690a3462211b7bfaf.png)