🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
技术要求
GAN 模型入门
什么是 GAN?
使用 GAN 创建新食品
加载数据集
特征工程效用函数
判别器模型
定义参数
构建卷积层
第一个卷积层
第二个卷积层
第三卷积层
第四个卷积层
第五层全连接层(final layer)
生成器模型
第一个转置卷积层
第二个转置卷积层
第三个转置卷积层
第四个转置卷积层
第五个转置卷积层(最后一层)
生成对抗模型
定义模型
配置优化器和损失函数
配置训练循环
训练生成器模型
训练判别器模型
保存生成的假图像
训练 GAN 模型
显示假图像的模型输出
使用 GAN 创建新的蝴蝶物种
GAN 训练挑战
使用 DCGAN 创建图像
额外学习
概括
打造一台能与人类智慧相匹敌的机器,一直是人类的梦想。而智能这个词具有多个维度,例如计算、物体识别、语音、理解上下文和推理;人类智力的任何方面都没有比我们的创造力更人性化。创作一件艺术品的能力,无论是一首音乐、一首诗、一幅画还是一部电影,一直是人类智慧的缩影,擅长这种创造力的人往往被视为“天才” 。 " 仍然完全没有答案的问题是,机器可以学习创造力吗?
我们已经看到机器学习使用各种信息来预测图像,有时甚至使用很少的信息。机器学习模型可以从一组训练图像和标签中学习,以识别图像中的各种对象;然而,视觉模型的成功取决于它们的泛化能力——即识别图像中不属于训练集的对象。这是在深度学习模型学习图像的表示时实现的。您可能会问的逻辑问题是,如果机器可以学习现有图像的表示,我们是否可以扩展相同的概念来教机器生成不存在的图像?
正如您所想象的,答案是肯定的!特别擅长这样做的深度学习算法家族是生成对抗网络(GAN)。各种 GAN 模型已被广泛用于创建不存在的人类图像,甚至是新绘画。其中一些画作甚至在苏富比举办的拍卖会上售出!
GAN 是一种流行的建模方法。在本章中,我们将构建生成模型,看看它们如何创建很酷的新图像。我们将看到 GAN 的高级用途,从已知图像集创建虚构的蝴蝶物种,以及从真实食物中创建假食物的类似图像。然后,我们还将使用另一种架构,即深度卷积生成对抗网络( DCGAN ),以获得更好的结果。
在本章中,我们将介绍以下主题:
- GAN 模型入门
- 使用 GAN 创建新的假食品
- 使用 GAN 创建新的蝴蝶物种
- 使用 DCGAN 创建新图像
技术要求
在本章中,我们将主要使用以下 Python 模块,并在其版本中提及:
- pytorch lightning (version 1.5.2)
- torch (version 1.10.0)
- matplotlib (version 3.2.2)
为了确保这些模块一起工作并且不会不同步,我们使用了特定版本的torch、 torchvision、 torchtext、 torchaudio和 PyTorch Lightning 1.5.2。您还可以使用相互兼容的最新版 PyTorch Lightning 和手电筒。更多详细信息可以在 GitHub 链接上找到:https ://github.com/PacktPublishing/Deep-Learning-with-PyTorch-Lightning
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet
!pip install pytorch-lightning==1.5.2 --quiet我们将使用食物数据集,其中包含 16,643 张食物图像的集合,分为 11 个主要食物类别,可在此处找到:https ://www.kaggle.com/trolukovich/food11-image-dataset 。
我们还将使用与蝴蝶数据集类似的模型,该数据集包含 75 种蝴蝶的 9,285 张图像。蝴蝶数据集可以在这里找到:https ://www.kaggle.com/gpiosenka/butterfly-images40-species 。
这两个数据集都可以在 CC0 下的公共领域获得。
GAN 模型入门
GAN 最令人惊奇的应用之一是生成。看看下面一张女孩的照片;你能猜出她是真实的还是只是由机器生成的?

图 6.1 – 使用 StyleGAN 生成假脸(图片来源 – https://thispersondoesnotexist.com)
创建如此逼真的面孔是 GAN 最成功的用例之一。然而,GAN 不仅限于生成漂亮的面孔或 deepfake 视频;它们还具有关键的商业应用,例如生成房屋图像或创建新的汽车或绘画模型。
虽然生成模型过去曾用于统计,但深度生成模型(如 GAN)相对较新。深度生成模型还包括变分自编码器( VAE ) 和自回归模型。但是,由于 GAN 是最流行的方法,我们将在这里重点介绍它们。
什么是 GAN?
有趣的是,GAN起源不是作为一种生成新事物的方法,而是作为一种提高视觉模型识别物体准确性的方法。数据集中的少量噪声会使图像识别模型给出截然不同的结果。在研究如何挫败的方法时针对用于图像识别的卷积神经网络( CNN ) 模型的对抗性攻击, Ian Goodfellow和他在 Google 的团队提出了一个相当简单的想法。(有一个关于 Ian 和他的团队发现 GAN 的有趣故事,其中涉及大量啤酒和乒乓球,每个也喜欢聚会的数据科学家可能都能与之相关!)
每种 CNN 类型的模型都会获取一张图像并将其转换为一个低维矩阵,该矩阵是该图像的数学表示(这是一组用于捕捉图像本质的数字)。如果我们反过来呢?如果我们从一个数学数字开始并尝试重建图像怎么办?嗯,可能很难直接做到这一点,但是通过使用神经网络,我们可以教机器生成假图像,方法是向机器提供大量真实图像,它们的数字表示,然后创建这些数字的一些变体以获得一个新的假图像。这正是 GAN 背后的理念!
典型的 GAN 架构由三部分组成——生成器、鉴别器和比较模块:
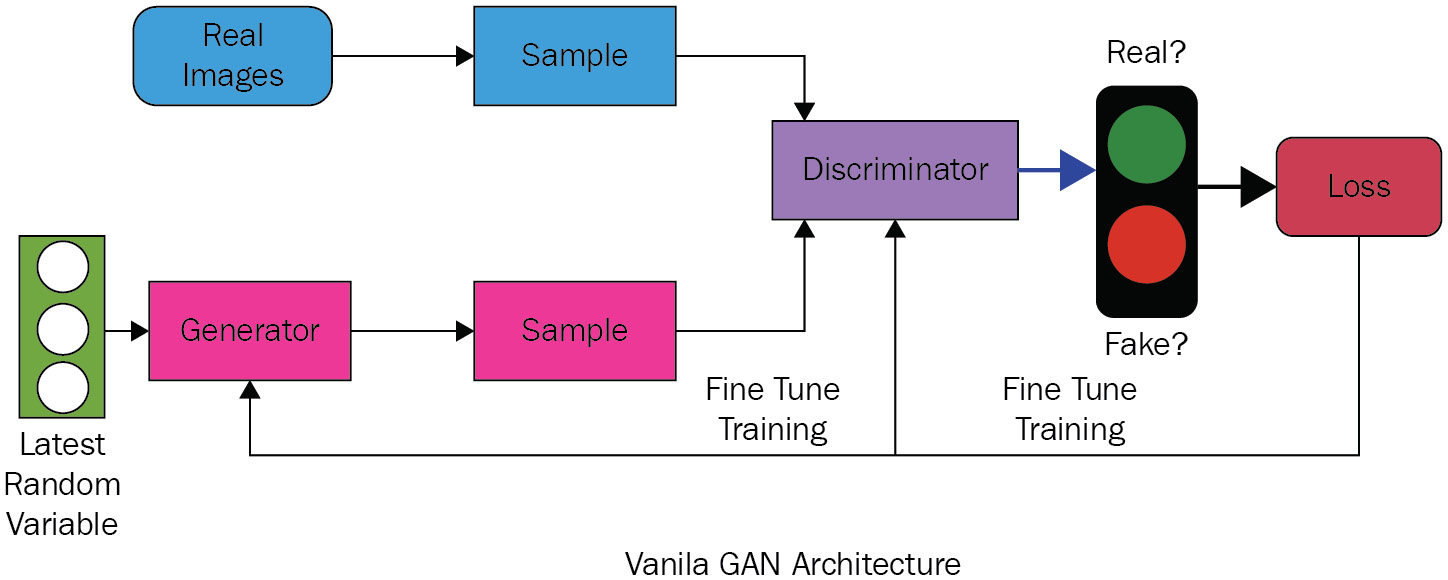
图 6.2 – Vanilla GAN 架构
生成器和判别器都是神经网络。我们从真实图像开始,使用编码器将它们转换为低维实体。生成器和判别器都参加了附加赛,试图互相击败。生成器的工作是使用随机数学值(真实值加上一些随机噪声的组合)生成假图像,鉴别器的工作是确定它是真还是假。损失函数可以衡量谁赢得了附加赛。随着通过不同时期的运行减少了损失,整体架构在生成逼真的图像方面变得越来越好。
GAN 的成功主要依赖于这样一个事实,即它们使用的参数数量非常少,因此可以产生惊人的结果,甚至少量数据的。GAN 有许多变体,例如StyleGAN和BigGAN,每个变体都有不同的神经网络层;但是,它们都遵循相同的架构。前面的假女孩图像使用了 StyleGAN 变体。
使用 GAN 创建新食品
GAN 是最重要的一种生成建模中使用的通用且强大的算法。GAN 被广泛用于生成假脸、图片、动漫/卡通人物、图像风格翻译、语义图像翻译等。
我们将从为我们的 GAN 模型创建架构开始:

图 6.3 – 用于创建新食物的 GAN 架构
首先,我们将定义神经网络对于具有多层卷积和全连接层的生成器和判别器。在我们将要构建的架构中,我们将有四个卷积层和一个全连接层作为鉴别器,我们将使用五个转置卷积层作为生成器。我们将尝试通过添加高斯噪声来生成假图像,并使用鉴别器来检测这些假图像。然后,我们将使用Adam优化器进行优化神经网络。对于这种用途,我们将使用交叉熵损失来最小化损失函数。
还有其他几个超参数,例如图像大小、批量大小、潜在大小、学习率、通道、内核大小、步幅和填充,也经过优化以获得 GAN 模型的输出。这些参数可以根据模型配置进行微调。这里的目标是训练一个 GAN与食物数据集建立模型架构并生成假食物图像,同样,使用与蝴蝶数据集相同的 GAN 模型架构来生成假蝴蝶图像。我们将在每个 epoch 结束时保存生成的图像,以便在每个 epoch 比较新的食物或蝴蝶图像。
在本节中,我们将介绍生成假食物图像的以下主要步骤:
- 加载数据集。
- 对实用程序功能进行特征工程。
- 配置判别器模型。
- 配置生成器模型。
- 配置生成自适应模型。
- 训练 GAN 模型。
- 获取假食品图像的输出。
加载数据集
数据集包含 16,643 种食物图像,分为 11 个主要食品类别。该数据集可以通过以下 URL 从 Kaggle 下载:https ://www.kaggle.com/trolukovich/food11-image-dataset 。
下载数据集的代码如下所示:
dataset_url = 'https://www.kaggle.com/trolukovich/food11-image-dataset'
od.download(dataset_url)在前面的代码中,我们正在使用opendatasets 包中的下载方法将数据集下载到我们的 Colab 环境中。
食物数据集的总大小为 1.19 GB,数据集包含三个子文件夹——训练、验证和评估。每个子文件夹都有存储在 11 个主要食物类别下的嵌套子文件夹中的食物图像。在本章中,为了构建我们的 GAN 模型,我们将在训练图像上训练我们的模型,因此我们将仅使用training子文件夹。所有图像都被着色并存储在与其食物类别相关的嵌套子文件夹中。
以下是数据集中的一些食物样本图像:

图 6.4 – 数据集中食物的原始随机图像
数据处理总是任何模型最重要的一步。因此,我们将对输入图像数据进行一些转换,以使我们的 GAN 模型更好更快地执行。在这个用例中,我们将主要关注四大转换,如以下步骤所示:
- 调整大小:首先,我们将图像大小调整为 64 像素。
- 中心裁剪:然后,我们将在中心裁剪调整大小的图像。这会将我们的图像转换为正方形。中心裁剪是我们的 GAN 模型表现更好的关键转换。
- 转换为张量:一旦图像被调整大小和中心裁剪,我们将把图像数据转换为张量,以便可以在 GAN 模型中进行处理。
- 归一化:最后,我们将在 -1 到 1 的范围内对张量进行归一化,均值为 0,标准差为 0.5。
- 以上所有转换不仅可以帮助我们的 GAN 模型表现得更好,还可以显着减少训练时间。
重要的提示
您可以尝试许多其他转换来提高模型性能,但对于这个用例,前面的转换已经足够开始了。
以下代码片段显示了我们的 GAN 模型的一些关键配置:
image_size = 64
batch_size = 128
normalize = [(0.5, 0.5, 0.5), (0.5, 0.5, 0.5)]
latent_size = 256
food_data_directory = "/content/food11-image-dataset/training"在前面的代码中,我们首先初始化要在下一步中使用的变量。图像大小设置为 64 像素,批量大小为 128,归一化张量的均值和标准差均为 0.5。潜在大小设置为 256,食物训练图像的路径保存为food_data_directory。在下一步中,我们将使用这些变量来转换我们的输入图像,为我们的 GAN 模型做准备:
food_train_dataset = ImageFolder(food_data_directory, transform=T.Compose([
T.Resize(image_size),
T.CenterCrop(image_size),
T.ToTensor(),
T.Normalize(*normalize)]))
food_train_dataloader = DataLoader(food_train_dataset, batch_size, num_workers=4, pin_memory=True, shuffle=True)在前面的代码中,我们使用了torchvision.datasets库中的ImageFolder类来加载图像数据集。我们正在使用torchvision.transforms库中的Compose方法将多个转换组合在一起。在compose方法内部,第一步是Resize方法将图像大小设置为 64 像素。在接下来的变换中,我们使用CenterCrop方法将图像转换为正方形。然后,我们将调整大小和裁剪后的图像转换为张量,最后将它们归一化在 -1 和 1 之间,均值和标准差为 0.5。我们将这些转换后的图像保存在food_train_dataset. 在最后一步中,我们使用来自torch.utils.data库的DataLoader类来创建批量大小为 128 和 4 个工人的food_train_dataloader,并设置一些参数以使数据加载器更好地工作。
到目前为止,在前面的代码中,我们已经加载了数据集并执行了一些转换,并且food_train_dataloader已准备好批量128的图像。
在数据处理步骤中,我们正在对图像进行转换和规范化,因此对我们来说,通过非规范化将它们恢复到原始形式非常重要。我们还需要比较我们的 GAN 模型为每个 epoch 生成的图像,所以我们需要在最后保存图像每个时代。因此,我们将在本章的下一节编写一些实用函数来实现这些功能。
特征工程效用函数
我们需要的第一个实用函数是将图像反规范化回原始形式。非规范化效用函数如下所示:
def denormalize(input_image_tensors):
input_image_tensors = input_image_tensors * normalize[1][0]
input_image_tensors = input_image_tensors + normalize[0][0]
return input_image_tensorsdenormalize效用函数接收张量并通过乘以0.5然后加上0.5对它们进行非规范化。这些归一化值(平均值和标准偏差)在本节开头定义。
所需的第二个实用功能是在每个 epoch 结束时保存图像。以下是第二个实用函数的代码片段:
def save_samples(index, sample_images):
fake_fname = 'generated-images-{}.png'.format(index)
save_image(denormalize(sample_images[-64:]), os.path.join(".", fake_fname), nrow=8)save_samples实用函数将索引(即 epoch 编号)和sample_images (即 GAN 模型在每个 epoch 结束时返回的图像)作为输入。然后,它将最后 64 张图像保存在 8 x 8 的网格中。
重要的提示
在此函数中,传递的同一批输入中共有128张图像,但我们只保存最后64张图像。您可以轻松更改此设置以保存更少或更多图像。更多图像通常需要更多计算 (GPU) 能力和内存。
我们还有其他本章中使用的实用函数,可以在我们本书的 GitHub 页面的完整笔记本中找到。
判别器模型
如前所述,判别器在 GAN 中是一个分类器,它试图将真实数据与创建的数据区分开来由发电机。在这个用例中,鉴别器充当图像的二元分类,将图像分类为真类和假类。
定义参数
让我们从创建开始一个名为FoodDiscriminator的类,它继承自 PyTorch nn模块。Discriminator类的一些重要特性/属性显示在以下代码片段中:
class FoodDiscriminator(nn.Module):
def __init__(self, input_size):
super().__init__()
self.input_size = input_size
self.channel = 3
self.kernel_size = 4
self.stride = 2
self.padding = 1
self.bias = False
self.negative_slope = 0.2FoodDiscriminator的输入是生成器生成的输出,大小为 3 x 64 x 64。我们还设置一些变量,例如通道大小为 3,内核大小为4,步幅为2,填充为1,偏差为False,负斜率为0.2。
输入通道设置为 3,因为我们有彩色图像,并且 3 通道代表红色、绿色和蓝色。内核大小为 4,代表 2D 卷积窗口的高度和宽度。执行卷积时,值为2的步幅将内核移动两步。填充将1像素层添加到图像的所有边界。将偏差设置为False意味着它不允许卷积网络向网络添加任何可学习的偏差。
负斜率设置为 0.2,它控制LeakyReLU激活的负斜率的角度功能。我们将在这里使用Leaky ReLU作为激活函数。有多种激活函数可用,例如 ReLU、tan-h和 sigmoid,但判别器在 Leaky ReLU 激活函数中表现更好。ReLU 激活函数和 Leaky ReLU 激活函数之间的区别在于 ReLU 函数只允许正值作为输出,而 Leaky ReLU 允许负值作为输出。通过设置negative_slope的值,我们允许0.2倍的负值作为Leaky ReLU 激活函数的输出。
构建卷积层
以下是判别器模型各层的代码片段:
#输入大小:(3,64,64)
self.conv1 = nn.Conv2d(self.channel,128,kernel_size=self.kernel_size,stride=self.stride,padding=self.padding,bias=self.bias)
self.bn1 = nn.BatchNorm2d(128)
self.relu = nn.LeakyReLU(self.negative_slope, inplace=True)
#输入大小:(64,32,32)
self.conv2 = nn.Conv2d(128, 256, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias)
self.bn2 = nn.BatchNorm2d(256)
#输入大小:(128,16,16)
self.conv3 = nn.Conv2d(256, 512, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias)
self.bn3 = nn.BatchNorm2d(512)
#输入大小:(256,8,8)
self.conv4 = nn.Conv2d(512, 1024, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias)
self.bn4 = nn.BatchNorm2d(1024)
# nn.LeakyReLU(self.negative_slope, inplace=True)
self.fc = nn.Sequential(
nn.Linear(in_features=16384,out_features=1),
# nn.Flatten(),
nn.Sigmoid()
)在前面的代码中,我们定义鉴别器模型的层来构建一个二进制分类模型,该模型从生成器模型中获取输出,生成器模型是一个大小为 3 x 64 x 64 的图像,并生成0或1的输出。因此,鉴别器能够识别图像是假的还是真实的。
前面显示的判别器模型由四个卷积层和一个全连接层组成,其中第一层接收从生成器模型生成的图像,每个连续层接收前一层的输入并将输出传递到下一层。
我们将把这个代码块分成几个部分以便更好地理解它。让我们详细讨论每一层。
第一个卷积层
以下是我们第一个卷积层的代码片段:
#输入大小:(3,64,64)
self.conv1 = nn.Conv2d(self.channel,128,kernel_size=self.kernel_size,stride=self.stride,padding=self.padding,bias=self.bias)
self.bn1 = nn.BatchNorm2d(128)
self.relu = nn.LeakyReLU(self.negative_slope, inplace=True)第一层conv1将生成器生成的图像作为输入,大小为 3 x 64 x 64,内核大小为4,步幅为1,填充为1 个像素,bias = False。然后conv1层生成128 个通道的输出,每个通道的大小为32——即 128 x 32 x 32。然后,使用批量归一化对卷积输出进行归一化,这有助于卷积网络更好地执行。最后,我们在第一层的最后一步使用 Leaky ReLU 作为我们的激活函数。
第二个卷积层
以下是我们第二个卷积层的代码片段:
#输入大小:(128,32,32)
self.conv2 = nn.Conv2d(128, 256, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias)
self.bn2 = nn.BatchNorm2d(256)
self.relu = nn.LeakyReLU(self.negative_slope, inplace=True)在前面的代码中,我们定义了第二个卷积层conv2,它接收第一个卷积层的输出,大小为 128 x 32 x 32,与第一个卷积层的内核大小、步幅、填充和偏差相同层。现在,该层生成具有 256 个通道的输出,每个通道的大小为 16(即 256 x 16 x 16)并将其传递给批量标准化。同样,我们在第二层的最后一步使用 Leaky ReLU 作为我们的激活函数。
第三卷积层
以下是我们第三个卷积层的代码片段:
#输入大小:(256,16,16)
self.conv3 = nn.Conv2d(256, 512, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias)
self.bn3 = nn.BatchNorm2d(512)
self.relu = nn.LeakyReLU(self.negative_slope, inplace=True)第三个卷积层self.conv3将第二层的输出作为输入,其大小为 256 x 16 x 16,与前两个卷积具有相同的内核大小、步幅、填充和偏差层。该层应用卷积生成具有 512 个通道的输出,每个通道的大小为 8(即 512 x 8 x 8),并将其传递给批量归一化。同样,我们在第三层的最后一步使用 Leaky ReLU 作为我们的激活函数。
第四个卷积层
以下是我们第四个卷积层的代码片段:
#输入大小:(512,8,8)
self.conv4 = nn.Conv2d(512, 1024, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias)
self.bn4 = nn.BatchNorm2d(1024)
self.relu = nn.LeakyReLU(self.negative_slope, inplace=True)第四个卷积层self.conv4将第三层的输出作为输入,其大小为 512 x 8 x 8,与前三个卷积层具有相同的内核大小、步幅、填充和偏差。该层应用卷积生成具有 1,024 个通道的输出,每个通道的大小为 4(即 1,024 x 4 x 4),并将其传递给批量归一化。同样,我们在第四层的最后一步使用 Leaky ReLU 作为我们的激活函数。
第五层全连接层(final layer)
以下是我们最终全连接层的代码片段:
self.fc = nn.Sequential(
nn.Linear(in_features=16384,out_features=1),
nn.Sigmoid()
)
# 输出大小:1 x 1 x 1判别器模型的最后一层如前所示,是使用顺序函数构建的。最后一层有一个全连接层,它接收第四层的输出,大小为 1,024 x 4 x 4。因此,全连接线性层的特征总数为 16,384。由于这是一个二元分类任务,最终的全连接层将生成具有 1 个通道的输出,每个通道的大小为 1,即大小为 1 x 1 x 1。这个输出然后传递给sigmoid激活函数,该函数生成0和1之间的输出,并帮助鉴别器作为二元分类模型工作。
总而言之,我们将鉴别器模型的层定义为卷积层和全连接线性网络的组合。这些层将从生成器生成的图像作为输入,以将它们分类为假的或真实的。现在,是时候传入来自不同层和激活函数的数据了。这可以通过覆盖forward方法来实现。FoodDiscriminator类的forward方法的代码如下所示:
def forward(self, input_img):
validity = self.conv1(input_img)
validity = self.bn1(validity)
validity = self.relu(validity)
validity = self.conv2(validity)
validity = self.bn2(validity)
validity = self.relu(validity)
validity = self.conv3(validity)
validity = self.bn3(validity)
validity = self.relu(validity)
validity = self.conv4(validity)
validity = self.bn4(validity)
validity = self.relu(validity)
validity=validity.view(-1, 1024*4*4)
validity=self.fc(validity)
return validity- 我们在第一个卷积层 ( self.conv1 ) 中传递数据(生成器模型的图像输出)。self.conv1的输出被传递给批量归一化函数self.bn1,批量归一化函数的输出被传递给 Leaky ReLU 激活函数self.relu。
- 然后,输出被传递到第二个卷积层(self.conv2)。同样,第二个卷积层的输出被传递给批量归一化函数self.bn2,然后传递给 Leaky ReLU 激活函数self.relu。
- 同样,输出现在传递到第三个卷积层(self.conv3)。并且,与前两个卷积层一样,此输出被传递给批量归一化函数self.bn3,然后传递给泄漏的 ReLU 激活函数self.relu。
- 对第四个卷积层 ( self.conv4 )、批量归一化函数 ( self.bn4 ) 和泄漏 ReLU 激活 ( self.relu ) 重复相同的传递。
- 数据通过卷积层,这些层的输出是多维的。为了将输出传递给我们的线性层,它被转换为一维形式。这可以使用张量视图方法来实现。
- 一旦数据以一维形式准备好,它就会通过全连接层,并返回最终输出,即二进制 1 或 0。
重申一下,在前向方法中,作为生成器输出的图像数据首先通过四个卷积层,然后卷积层的输出通过一个全连接层。最后,返回输出。
重要的提示
我们在判别器模型中使用的激活函数是 Leaky ReLU,它往往表现得更好,有助于 GAN 表现得更好。
现在我们已经完成了架构的鉴别器部分,我们将继续构建生成器。
生成器模型
介绍中提到,生成器的作用GAN 的一部分是通过合并反馈来创建假数据(在这种情况下为图像)从鉴别器。生成器的目标是生成非常接近真实图像的假图像,以便鉴别器无法将它们识别为假图像。
让我们首先创建一个名为FoodGenerator的类,该类继承自 PyTorch nn模块。一些重要的FoodGenerator类的特性/属性如下所示代码片段:
class FoodGenerator(nn.Module):
def __init__(self, latent_size = 256):
super().__init__()
self.latent_size = latent_size
self.kernel_size = 4
self.stride = 2
self.padding = 1
self.bias = False潜在大小是生成器模型中最重要的特征之一。它表示输入的压缩低维表示(在本例中为食物图像),此处默认设置为 256。然后,我们将内核大小设置为 4,步长为 2,这在执行卷积时将内核移动了两步。我们还将填充设置为 1,这会为食物图像的所有边界添加一个额外的像素。最后,将偏差设置为False,这意味着它不允许卷积网络向网络添加任何可学习的偏差。
我们将使用 Torch 库 ( torch.nn )的神经网络模块中的 Sequential 函数来构建生成器模型的层。以下是构建生成器模型的代码片段:
self.model = nn.Sequential(
#input size: (latent_size,1,1)
nn.ConvTranspose2d(latent_size, 512, kernel_size=self.kernel_size, stride=1, padding=0, bias=self.bias),
nn.BatchNorm2d(512),
nn.ReLU(True),
#input size: (512,4,4)
nn.ConvTranspose2d(512, 256, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.BatchNorm2d(256),
nn.ReLU(True),
#input size: (256,8,8)
nn.ConvTranspose2d(256, 128, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.BatchNorm2d(128),
nn.ReLU(True),
#input size: (128,16,16)
nn.ConvTranspose2d(128, 64, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.Tanh()
# output size: 3 x 64 x 64
)在前面的代码中,我们定义了生成器模型的层以生成大小为 3 x 64 x 64 的假图像。之前显示的生成器模型由五个反卷积层组成,其中每一层接收输入并将输出传递到下一层。
发电机模型与判别器的层数几乎相反模型,除了一个完全连接的线性层。
比较转置卷积和反卷积
这两个术语在深度学习社区中经常互换使用,本书就是如此。从数学上讲,反卷积是一种反转卷积效果的数学运算。想象一下通过卷积层抛出输入并收集输出。现在,通过反卷积抛出输出层,你会得到完全相同的输入。它是多元卷积函数的反函数。
我们在这里所做的并不是取回完全相同的输入。因此,虽然操作相似,但严格来说不是反卷积,而是转置卷积。转置卷积有点相似,因为它产生的空间分辨率与假设的反卷积层相同。但是,对这些值执行的实际数学运算是不同的。转置卷积层执行常规卷积,但反转其空间变换。
正如所讨论的,反卷积不是很流行,并且社区通常将转置卷积称为反卷积,这就是这里所指的。
我们将把这个代码块分成几个部分以便更好地理解它。让我们详细讨论每一层。
第一个转置卷积层
这是代码片段对于我们的第一个ConvTranspose2d层:
#input size: (latent_size,1,1)
nn.ConvTranspose2d(latent_size, 512, kernel_size=self.kernel_size, stride=1, padding=0, bias=self.bias),
nn.BatchNorm2d(512),
nn.ReLU(True),第一个ConvTranspose2d层将latent_size作为输入,即 256,内核大小为4,步幅为1,填充为0像素,bias = False。然后ConvTranspose2d层生成 512 的输出。然后,使用批量归一化对转置卷积输出进行归一化,这有助于转置卷积网络更好地执行。最后,我们在第一层的最后一步使用 ReLU 作为我们的激活函数。
第二个转置卷积层
以下是我们的第二个ConvTranspose2d层的代码片段:
#input size: (512,4,4)
nn.ConvTranspose2d(512, 256, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.BatchNorm2d(256),
nn.ReLU(True),在前面的代码中,我们定义了第二个转置卷积层,它接收第一个转置卷积层的输出,大小为 512 x 4 x 4,内核大小为4,步幅为2,填充为1像素,并且偏差 = False。现在,该层生成具有 256 个通道的输出并将其传递给批量归一化。同样,我们正在使用 ReLU作为我们在第二层最后一步的激活函数。
第三个转置卷积层
以下是我们第三个ConvTranspose2d层的代码片段:
#input size: (256,8,8)
nn.ConvTranspose2d(256, 128, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.BatchNorm2d(128),
nn.ReLU(True),第三个转置卷积层将第二层的输出作为输入,其大小为 256 x 8 x 8,与第二个转置卷积层具有相同的内核大小、步幅、填充和偏置。该层应用转置卷积生成具有 128 个通道的输出,并将其传递给批量归一化。同样,我们在第三层的最后一步使用 ReLU 作为我们的激活函数。
第四个转置卷积层
以下是我们第四个ConvTranspose2d层的代码片段:
#input size: (128,16,16)
nn.ConvTranspose2d(128, 64, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.BatchNorm2d(64),
nn.ReLU(True),第四个转置卷积层将第三层的输出作为输入,其大小为 128 x 16 x 16,与最后两个转置卷积具有相同的内核大小、步幅、填充和偏置卷积层。该层应用转置卷积来生成具有 64 个通道的输出,并将其传递给批量归一化。同样,我们在第四层的最后一步使用 ReLU 作为我们的激活函数。
第五个转置卷积层(最后一层)
以下是我们第五个也是最后一个ConvTranspose2d层的代码片段:
nn.ConvTranspose2d(64, 3, kernel_size=self.kernal_size, stride=self.stride, padding=self.padding, bias=self.bias),
nn.Tanh()
# output size: 3 x 64 x 64在最后的反卷积神经网络层中,我们生成3个64 x 64大小的通道和激活函数为Tanh的输出。在这里,我们使用了不同的激活函数,因为这是一个生成器模型,它与Tanh配合得更好。
请注意,对于第一个转置卷积层,我们使用的步幅为 1,没有填充,而对于其余层,我们使用的填充大小为 1,步幅为 2。
总而言之,我们将生成器模型的层定义为五个转置卷积层。这些层将潜在大小作为输入,经过多个反卷积层,并将通道从256扩大到512,然后缩小到256到128,最后扩大到3个通道。
现在,是时候传入来自不同层和激活函数的数据了。这可以通过覆盖forward方法来实现。FoodGenerator类的forward方法的代码如下所示:
def forward(self, input_img):
input_img = self.model(input_img)
return input_img在前面的代码中,FoodGenerator类的forward方法将图像作为输入,通过它到模型,这是一个转置卷积层的序列,并返回输出,即生成的假图像。
生成对抗模型
现在我们已经定义了我们的鉴别器和生成器模型,是时候将它们结合起来构建我们的 GAN 模型了。我们将配置GAN 模型中的损失函数和优化器,并将数据传递给生成器和判别器。为了得到好的结果(这意味着生成和真实图像一样好看的假图像),我们会尽量减少损失。让我们详细看看 GAN 的 PyTorch Lightning 实现。
使用 PyTorch Lightning 构建我们的 GAN 模型主要包括以下步骤:
- 定义模型。
- 配置优化器和损失函数。
- 配置训练循环。
- 保存生成的假图像。
- 训练 GAN 模型。
让我们详细看看这些步骤。
定义模型
让我们创建一个名为FoodGAN的类,它继承自 PyTorch LightningModule。Module类采用构造函数中的以下参数:
- latent_size:这表示食物图像的压缩低维表示。默认值为 256。
- lr:这是用于鉴别器和生成器的优化器的学习率。默认值为0.0002。
- bias1和bias2:b1和b2是用于鉴别器和生成器的优化器的偏差值。b1的默认值为0.5,而b2的默认值为0.999。
- batch_size:这表示将通过网络传播的图像数量。批量大小的默认值为128。
现在,我们将使用__init__方法初始化、配置和构建我们的FoodGAN类。以下是__init__方法的代码片段:
def __init__(self, latent_size = 256,learning_rate = 0.0002,bias1 = 0.5,bias2 = 0.999,batch_size = 128):
super().__init__()
self.save_hyperparameters()
# networks
# data_shape = (channels, width, height)
self.generator = FoodGenerator()
self.discriminator = FoodDiscriminator(input_size=64)
self.batch_size = batch_size
self.latent_size = latent_size
self.validation = torch.randn(self.batch_size, self.latent_size, 1, 1)前面定义的__init__方法将潜在大小、学习率、 bias1、bias2和批大小作为输入。这些是鉴别器和生成器所需的所有超参数模型,因此这些变量保存在__init__方法中。最后,我们还创建了一个名为validation的变量,我们将使用它来验证模型。
配置优化器和损失函数
我们还要定义FoodGAN模型中用于计算损失的效用函数,如前文所述部分,因为我们希望最小化损失以获得更好的结果。以下是损失函数的代码片段:
def adversarial_loss(self, preds, targets):
return F.binary_cross_entropy(preds, targets)在前面的代码片段中,adversarial_loss方法有两个参数——preds是预测值,targets是真实目标值。然后,它使用binary_cross_entropy函数从预测值和目标值计算损失,最后返回计算的熵值。
重要的提示
生成器和鉴别器也可以有不同的损失函数。在这里,我们保持简单,只使用二元交叉熵损失。
下一个重要方法用于配置优化器,因为我们有两个模型,鉴别器和生成器,在FoodGAN模型中,每个模型都需要自己的优化器。这可以使用一种名为configure_optimizer的 PyTorch Lightning 生命周期方法轻松实现。以下是configure_optimizer方法的代码片段:
def configure_optimizers(self):
learning_rate = self.hparams.learning_rate
bias1 = self.hparams.bias1
bias2 = self.hparams.bias2
opt_g = torch.optim.Adam(self.generator.parameters(), lr=learning_rate, betas=(bias1, bias2))
opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=learning_rate, betas=(bias1, bias2))
return [opt_g, opt_d], []在__init__方法中,我们调用了一个名为self.save_hyperparameters()的方法。这会将发送到init方法的所有输入保存到一个名为hparams的特殊变量中。在configure_optimizer方法中利用这个特殊变量来访问我们的学习率和偏差值。在这里,我们创建了两个优化器——opt_g是生成器的优化器,而opt_d是鉴别器的优化器,因为它们每个都需要自己的优化器。配置优化器方法返回两个列表——第一个列表包含多个优化器,第二个列表在我们的例子中是空的,是我们可以传递 LR 调度程序的地方。
总而言之,我们正在创建两个优化器,一个用于生成器,一个用于鉴别器,通过访问来自hparams特殊变量的超参数。此方法返回两个列表作为输出,其中第一个列表的第一个元素是生成器的优化器,第二个元素是鉴别器的优化器。
重要的提示
configure_optimizer方法返回两个值;两者都是一个列表,其中第二个是一个空列表。该列表有两个值 -索引0处的值具有生成器的优化器,索引1处的值具有鉴别器的优化器。
另一个重要的生命周期方法是前向方法。以下是此方法的代码片段:
def forward(self, z):
return self.generator(z)在前面的代码中,forward方法接收输入,将其传递给生成器模型,然后返回输出。
配置训练循环
我们已经覆盖了方法为鉴别器和生成器模型配置优化器。现在,是时候为鉴别器和生成器配置训练循环了。在训练 GAN 模型期间访问正确的判别器和生成器优化器非常重要,这可以通过在训练期间使用 PyTorch Lightning 模块作为输入传递的数据来完成。让我们尝试更详细地了解为训练生命周期方法和训练过程传递的输入。
- batch:这表示由food_train_dataloader提供的批处理数据。
- batch_idx:这是用于训练的批次的索引。
- optimizer_idx:这有助于我们识别生成器和判别器的两个不同优化器。这个输入参数有两个值,0代表生成器,1代表鉴别器。
训练生成器模型
现在我们明白了我们如何识别鉴别器和生成器的优化器,是时候了解如何使用它们来训练我们的 GAN 模型了。训练生成器的代码片段如下:
real_images, _ = batch
# train generator
if optimizer_idx == 0:
# Generate fake images
fake_random_noise = torch.randn(self.batch_size, self.latent_size, 1, 1)
fake_random_noise = fake_random_noise.type_as(real_images)
fake_images = self(fake_random_noise) #self.generator(latent)
# Try to fool the discriminator
preds = self.discriminator(fake_images)
targets = torch.ones(self.batch_size, 1)
targets = targets.type_as(real_images)
loss = self.adversarial_loss(preds, targets)
self.log('generator_loss', loss, prog_bar=True)
tqdm_dict = {'g_loss': loss}
output = OrderedDict({
'loss': loss,
'progress_bar': tqdm_dict,
'log': tqdm_dict
})在前面的代码中,我们首先将从批次接收到的图像存储在一个名为real_images的变量中。这些输入是张量格式。重要的是要确保所有的张量都在使用相同的设备——在我们的例子中是 GPU,以便它可以在 GPU 上运行。为了将所有张量转换为相同的类型,以便它们将其指向相同的设备,我们正在利用 PyTorch Lightning 推荐的名为type_as()的方法。type_as方法会将张量转换为与其他张量相同的类型,以确保所有张量类型相同并且可以使用 GPU,同时还可以使我们的代码扩展到任意数量的 GPU 或 TPU。有关此方法的更多信息,请参阅 PyTorch Lightning 文档。
正如我们在上一节中所讨论的,确定生成器的优化器以训练我们的生成器非常重要模型。我们通过检查optimizer_idx来识别生成器的优化器,生成器必须为 0。训练生成器模型的三个主要步骤——创建随机噪声数据、转换随机噪声的类型以及从随机噪声生成假图像。以下是演示这一点的代码片段:
fake_random_noise = torch.randn(self.batch_size, self.latent_size, 1, 1)
fake_random_noise = fake_random_noise.type_as(real_images)
fake_images = self(fake_random_noise)在上述代码中,执行了以下步骤:
- 第一步是创建一些随机噪声数据。为了创建随机噪声数据,我们利用了 torch 包中的randn方法,该方法返回一个张量,其中填充了大小等于潜在大小的随机数。这个随机噪声被保存为fake_random_noise变量。
- 下一步是将随机噪声的张量类型转换为与我们的real_images张量相同的类型。这是通过前面描述的type_as方法实现的。
- 最后,随机噪声被传递给自我对象,它正在将随机噪声数据传递给我们的生成器模型以生成假图像。这些被保存为fake_images。
既然我们已经生成现在我们的假图像,下一步是计算损失。然而,重要的是在计算损失之前确定我们的假图像与真实图像的接近程度。我们已经定义了我们的鉴别器,并且可以通过将我们的假图像传递给鉴别器并比较输出来轻松地利用它来识别它。因此,我们将在上一步中生成的假图像传递给我们的鉴别器并保存预测,其中值可以是0或1。以下代码片段显示了如何将假图像传递给鉴别器:
# Try to fool the discriminator
preds = self.discriminator(fake_images)
targets = torch.ones(self.batch_size, 1)
targets = targets.type_as(real_images)在前面的代码中,我们首先将假图像传递给鉴别器并将它们保存在变量preds中。然后,我们创建一个除一个之外的所有目标变量,假设生成器生成的所有图像都是真实图像。随着 GAN 模型的训练,这将在几个 epoch 后开始改善。最后,我们将目标的张量类型转换为与我们的real_images张量相同的类型。
下一步,我们将计算损失。这是通过使用我们的adversarial_loss实用函数来实现的,如下所示:
loss = self.adversarial_loss(preds, targets)
self.log('generator_loss', loss, prog_bar=True)adversarial_loss方法从鉴别器和目标值中获取预测值,它们都是 1作为输入并计算损失。损失记录为generator_loss,如果您想稍后使用 TensorBoard 绘制损失,这很重要。
最后,我们将返回损失函数和其他属性,以利用正在记录并显示在进度条上的损失,如下所示:
tqdm_dict = {'g_loss': loss}
output = OrderedDict({
'loss': loss,
'progress_bar': tqdm_dict,
'log': tqdm_dict
})
return output在前面的代码中,损失和其他属性存储在名为output的字典中,并在训练生成器的最后一步中返回。一旦在训练步骤中返回此损失值,PyTorch Lightning 将负责更新权重。
训练判别器模型
与生成器模型类似,我们将从比较优化器索引开始,仅在索引为1时训练鉴别器,如下所示:
# 训练判别器
if optimizer_idx == 1:有四个步骤我们将遵循训练我们的判别器模型——训练我们的判别器以识别真实图像,保存判别器模型的输出,将张量的类型转换为判别器的输出,并计算损失。这些步骤是通过此处显示的代码片段实现的:
real_preds = self.discriminator(real_images)
real_targets = torch.ones(real_images.size(0), 1)
real_targets = real_targets.type_as(real_images)
real_loss = self.adversarial_loss(real_preds, real_targets)在前面的代码中,我们首先将真实图像传递给鉴别器并将输出保存为real_preds。然后,我们创建一个虚拟张量,其值为全为 1,称为real_targets。将所有真实目标值设置为 1 的原因是我们将真实图像传递给鉴别器。我们还将真实目标的张量类型转换为与真实图像的张量相同。最后,我们正在计算我们的损失并将其称为real_loss。
现在,鉴别器已经用真实图像进行了训练,是时候用生成器模型生成的假图像来训练它了。这一步类似于训练我们的生成器。因此,我们将创建虚拟随机噪声数据,将其传递给生成器以创建假图像,然后将其传递给鉴别器以对其进行分类。用假图像训练判别器的过程如下面的代码片段所示:
# 生成假图片
real_random_noise = torch.randn(self.batch_size, self.latent_size, 1, 1)
real_random_noise = real_random_noise.type_as(real_images)
fake_images = self(real_random_noise) #self.generator(latent)
# 通过鉴别器传递假图像
fake_targets = torch.zeros(fake_images.size(0), 1)
fake_targets = fake_targets.type_as(real_images)
fake_preds = self.discriminator(fake_images)
fake_loss = self.adversarial_loss(fake_preds, fake_targets)
# fake_score = torch.mean(fake_preds).item()
self.log('discriminator_loss', fake_loss, prog_bar=True)在前面的代码中,我们首先按照我们在训练生成器时遵循的相同步骤生成假图像。这些假图像存储为fake_images。
接下来,我们将创建一个值全为零的虚拟张量,称为fake_targets。然后,我们将 fake_targets 的张量类型转换为与real_images的张量相同。然后,我们将假图像通过鉴别器进行预测并将预测保存为fake_preds。最后,我们通过利用adversarial_loss效用函数来计算损失,该函数将fake_preds和fake_targets作为输入来计算损失。这也记录在 self-object 中,稍后调用以使用 TensorBoard 绘制损失函数。
训练的最后一步训练判别器后的GAN模型是计算总损失,即用真实图像训练判别器时计算的损失和假损失的总和,也就是用假图像训练判别器时计算的损失。以下是演示这一点的代码片段:
# 更新判别器权重
loss = real_loss + fake_loss
self.log('total_loss', loss, prog_bar=True)在前面的代码中,我们添加了real_loss和fake_loss来计算总损失并将其存储在变量 loss 中。此损失也记录为总损失,稍后将在 TensorBoard 中调用以进行观察。
最后,我们返回损失函数和其他属性以记录损失值并在进度条中显示它们。以下是返回损失和其他属性的代码片段:
tqdm_dict = {'d_loss': loss}
output = OrderedDict({
'loss': loss,
'progress_bar': tqdm_dict,
'log': tqdm_dict
})
return output在前面的代码中,我们正在保存损失函数和其他属性在名为output的字典中,然后在训练结束时返回。一旦在训练步骤中返回此损失值,PyTorch Lightning 模块将负责更新权重。这样就完成了我们的训练配置。
总结一下训练循环,我们首先获取优化器索引,然后根据索引值训练生成器或鉴别器,最后返回损失值作为输出。
重要的提示
当optimizer_idx值为0时,正在训练生成器模型,当值为1时,正在训练判别器模型。
保存生成的假图像
检查也很重要我们的 GAN 模型在各个时期的训练和改进情况如何,看看它是否可以生成任何新的食物菜肴。我们可以通过在每个 epoch 结束时保存一些图像来在每个 epoch 跟踪我们的 GAN 模型。这可以通过利用称为on_epoch_end()的 PyTorch Lightning 方法之一来实现。此方法在每个 epoch 结束时调用,因此我们将使用它来保存 GAN 模型生成的假图像。以下是演示这一点的代码:
def on_epoch_end(self):
# import pdb;pdb.set_trace()
z = self.validation.type_as(self.generator.model[0].weight)
sample_imgs = self(z) #self.current_epoch
ALL_FOOD_IMAGES.append(sample_imgs.cpu())
save_generated_samples(self.current_epoch, sample_imgs)在on_epoch_end()方法中,我们正在保存z变量中生成器模型的权重,然后使用self方法将样本图像存储为sample_imgs。然后,我们将这些示例图像添加到ALL_FOOD_IMAGES列表中。最后,我们使用我们的save_generated_samples实用程序函数将假食品图像保存为.png文件。
训练 GAN 模型
最后,我们都准备好了训练 GAN 模型。以下是训练我们的 GAN 模型的代码:
model = FoodGAN()
trainer = pl.Trainer( max_epochs=100, progress_bar_refresh_rate=25, gpus=1)#gpus=1,
trainer.fit(model, food_train_dataloader)在前面的代码中,我们首先初始化我们的FoodGAN模型,将其保存为model。然后,我们从 PyTorch Lightning 包中调用Trainer方法,最大数量为 100 个 epoch 并启用 1 个 GPU。最后,我们使用fit方法通过传递我们的FoodGAN模型以及本节前面创建的数据加载器来开始训练。

图 6.5 – GAN 模型训练 100 轮的输出
我们还可以利用 TensorBoard 可视化并观察 GAN 模型在训练时的损失,如下所示:
%load_ext 张量板
%load_ext tensorboard
%tensorboard --logdir lightning_logs/%tensorboard --logdir 闪电日志/
这将产生以下输出:

图 6.6 – GAN 模型总损失的输出
我们还可以观察生成器损失和鉴别器损失(完整的代码和输出可在 GitHub 存储库中获得)。
显示假图像的模型输出
我们首先训练模型100 个epoch,但捕获多个结果以显示进展:

图 6.7 – 3 个 epoch 后生成的图像
下图展示了 9 个 epoch 后的进度:

图 6.8 – 9 epochs 后生成的图像

图 6.9 – epoch 100 的假食物图像
如您所见,我们现在有一些原始数据集中不存在的食物,因此它们是假食物(至少到目前为止基于数据集,因此您可以尝试在家制作)。
您可以为更多的时期训练模型,并且质量将继续提高。例如,尝试训练200、300、400和500个epoch。(更多结果可以在我们本书的 GitHub 页面上找到。)总会有一些输出完全嘈杂,看起来像不完整的图像。
GAN 对批量大小、潜在大小和其他超参数很敏感。要提高性能,可以尝试运行 GAN 模型对于更多的时期和不同的超参数。
使用 GAN 创建新的蝴蝶物种
在本节中,我们将使用我们在上一节中构建的相同 GAN 模型,稍作调整以生成新的蝴蝶物种。
由于我们在这里遵循相同的步骤,因此我们将保持描述简洁并观察输出。(完整的代码可以在本章的 GitHub 存储库中找到。)
我们将首先尝试使用之前用于生成食物图像的架构(即 4 个卷积层、1 个全连接层和 5 个转置卷积层)。然后我们将尝试另一种具有 5 个卷积层和 5 个转置卷积层的架构:
- 下载数据集:
dataset_url = 'https://www.kaggle.com/gpiosenka/butterfly-images40-species' od.download(dataset_url) - 初始化图像的变量:
image_size = 64 batch_size = 128 normalize = [(0.5, 0.5, 0.5), (0.5, 0.5, 0.5)] latent_size = 256 butterfly_data_directory = "/content/butterfly-images40-species/train" - 为蝴蝶数据集创建一个数据加载器:
Butterfly_train_dataset = ImageFolder(butterfly_data_directory,transform=T.Compose([ T.Resize(image_size), T.CenterCrop(image_size), T.ToTensor(), T.Normalize(*normalize)])) buttefly_train_dataloader = DataLoader(butterfly_train_dataset, batch_size, num_workers=4, pin_memory=True, shuffle=True) - 非规范化图像并显示它们。
在本节中,我们将执行以下操作:
- 定义一个效用函数来对图像张量进行非规范化。
- 定义一个实用函数来加载蝴蝶图像的显示。
- 调用 display images 函数显示原始蝴蝶图像。
此代码与我们在前面的示例中看到的相同,因此您可以重用它。这将显示原始图像,如下所示:

图 6.10 – 原始蝴蝶图像
现在,我们可以定义生成器和鉴别器模块,然后是优化器。架构是相同的,所以请随意重新使用以前的代码。测试完成后,您可以训练模型。
- 训练蝴蝶 GAN 模型:
model = ButterflyGAN() trainer = pl.Trainer( max_epochs=100, progress_bar_refresh_rate=25, gpus=1)#gpus=1, trainer.fit(model, buttefly_train_dataloader)
在此代码片段中,我们将 Butterfly GAN 模型训练 100 个 epoch

图 6.11 – GAN 模型生成的蝴蝶种类
重要的提示
检测 GAN 生成的假货来自真实物体是一个真正的挑战,也是深度学习社区积极研究的一个领域。在这里可能很容易检测到假蝴蝶,因为有些颜色很奇怪,但不是全部。你可能会看到一些蝴蝶物种是异国情调的太平洋蝴蝶,但不要搞错——它们都是假的。您可以使用一些技巧来识别假货,例如缺乏对称性或颜色失真。然而,它们并非万无一失,而且通常情况下,人类会被 GAN 生成的图像所欺骗。
GAN 训练挑战
GAN 模型需要大量的计算资源用于训练模型以获得良好的结果,特别是当数据集不是很干净并且图像中的表示不是很容易学习时。为了在我们的假生成图像中获得具有清晰表示的非常干净的输出,我们需要将更高分辨率的图像作为输入传递给我们的 GAN 模型。然而,更高的分辨率意味着模型中需要更多的参数,这反过来又需要更多的内存来训练模型。
这是一个示例场景。我们已经使用 64 像素的图像大小训练了我们的模型,但是如果我们将图像大小增加到 128 像素,那么 GAN 模型中的参数数量会从15.9 M急剧增加到93.4 M。反过来,这需要更多的计算能力来训练模型,并且由于 Google Collab 环境中的资源有限,在 20 到 25 个 epoch 之后,您可能会收到类似于此的错误:
RuntimeError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 15.78 GiB total capacity; 13.94 GiB already allocated; 50.75 MiB free; 14.09 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF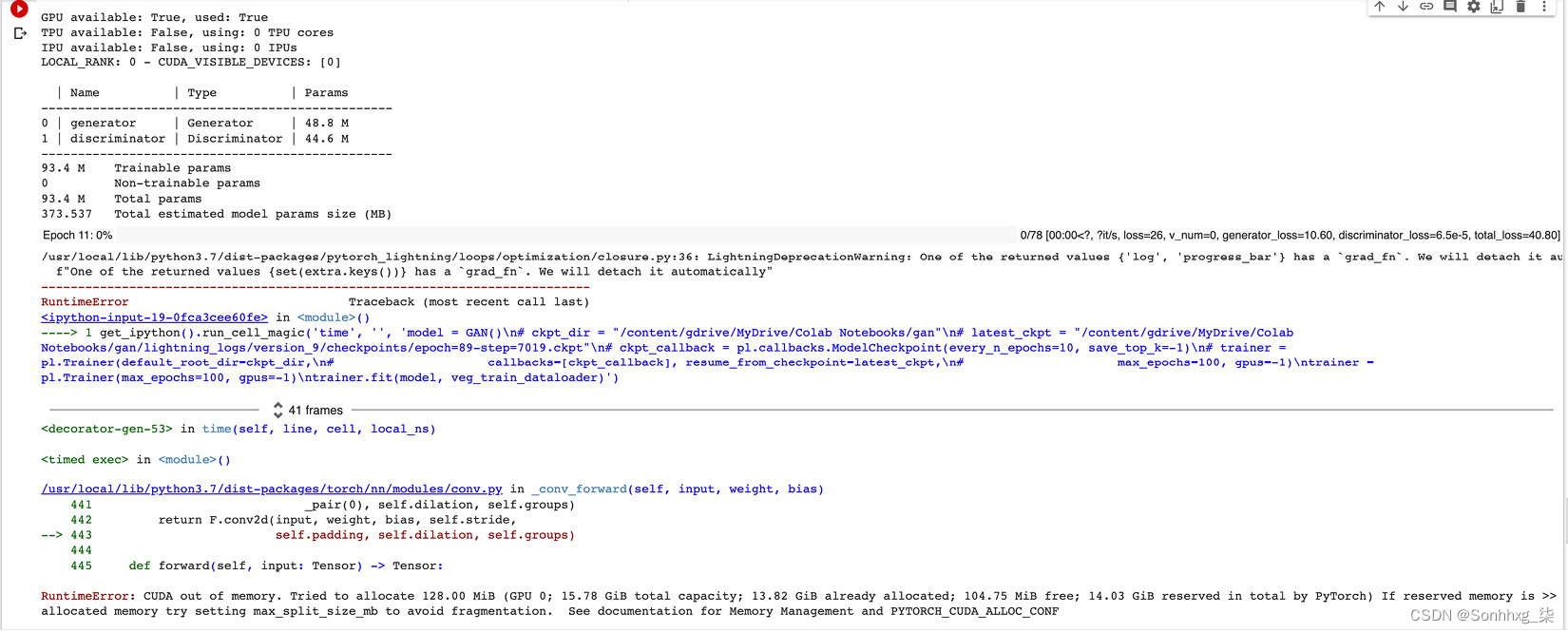
图 6.12 – 高分辨率图像上的内存错误
有一些技巧可以减少内存利用率,例如减少批量大小或梯度累积。但是,这些变通办法也有限制。例如,如果您将批量大小从 128 减少到 64,则模型将花费更长的时间来学习图像中的表示。当您减少批量大小并训练模型时,您可以在生成的图像中观察到这一点。
当批量大小较低时,模型会振荡,因为梯度是较少数据实例的平均值。在这种情况下,可以使用梯度累积技术,它为n个批次添加参数的梯度。这可以通过在Trainer实例中使用accumulate_grad_batches参数来实现,如下所示:
# Accumulate gradients for 16 batches
trainer = Trainer(accumulate_grad_batches=16)因此,您可以结合这些两个参数,批量大小和accumulate_grad_batches,以获得类似的有效批量大小来训练更高分辨率的图像,如下所示:
batch_size = 8
trainer = pl.Trainer(max_epochs=100, gpus=-1, accumulate_grad_batches=16)这意味着将针对 128 的有效批量大小进行训练。但是,限制再次是训练时间,因此要训练我们的模型远高于 100 个 epoch,以便使用这种技术获得体面的结果,同时避免内存不足错误。
许多深度学习研究领域都受到研究人员可用计算资源数量的限制。大多数大型科技公司(例如 Google 和 Facebook)通常会在该领域取得新的进展,主要是因为它们可以访问大型服务器和大型数据集。
使用 DCGAN 创建图像
DCGAN 是直接扩展讨论的 GAN 模型在上一节中,除了它在鉴别器中显式使用卷积和卷积转置层和发电机分别。DCGAN 最早被提出在Alec Radford、Luke Metz 和 Soumith Chintala的论文《使用深度卷积生成对抗网络的无监督表示学习》中:
图 6.13 – DCGAN 架构概览
DCGAN 架构基本上由5 层卷积和 5 层转置卷积组成。该架构中没有全连接层。我们还将使用 0.0002 的学习率来训练模型。
我们还可以更深入地了解 DCGAN 的生成器架构,看看它是如何工作的:
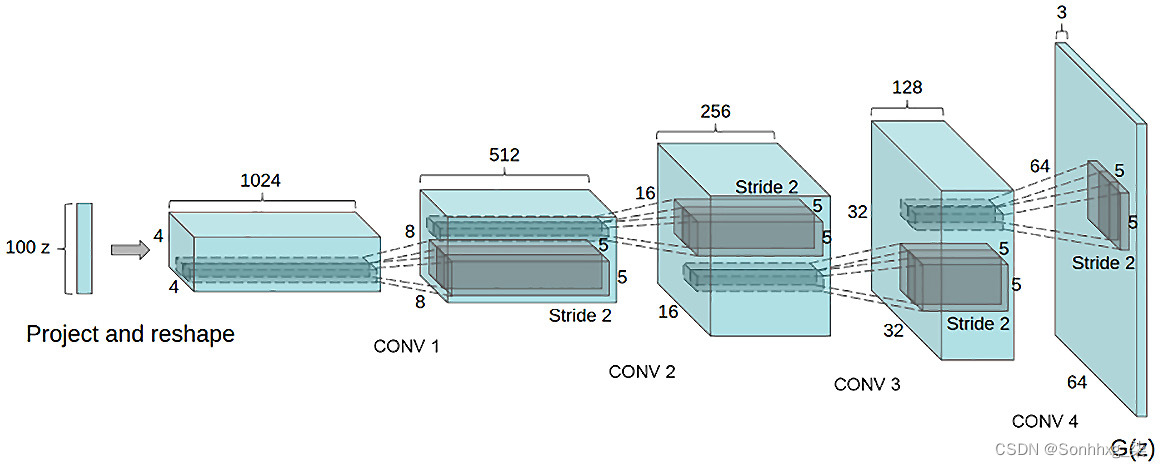
图 6.14 – 论文中的 DCGAN 生成器架构
可以观察到从 DCGAN 生成器架构图中没有全连接或这里使用的池化层。这是 DCGAN 模型的架构变化之一。DCGAN 优于 GAN 的关键优势在于其内存和计算效率。可以在 PyTorch 网站上找到 DCGAN 的教程。
我们将在同一个 DCGAN 模型上使用这两个数据集(食物数据和蝴蝶数据)。
该代码将由以下块组成:
- 定义输入
- 加载数据中
- 权重初始化
- 判别器模型
- 发电机型号
- 优化器
- 训练
- 结果
代码非常相似对于我们刚刚看到的那个在上一节中。有关完整的工作代码,请参阅本章的 GitHub 存储库:https ://github.com/PacktPublishing/Deep-Learning-with-PyTorch-Lightning/tree/main/Chapter06 。
我们为两个数据集训练了 100 个 epoch 的模型,以下是我们看到的损失。

图 6.15 – DCGAN 模型训练期间的生成器和判别器损失
根据训练,我们得到食物的以下结果和蝴蝶数据集:

图 6.16 – DCGAN 模型在 500 个 epoch 后生成的假食物图像
下图显示了蝴蝶数据集的结果:

图 6.17 – DCGAN 模型在 500 个 epoch 后生成的假蝴蝶种类
正如你将看到的,我们得到的不仅仅是很多使用 DCGAN 架构获得更好质量的结果,但使用更少时代。DCGAN 的内存和计算要求也低于 vanilla GAN,并且使用相同数量的 GPU,我们可以运行更长时间的模型。这是由于 DCGAN 的固有优化,使其更加高效和有效。
额外学习
- 您可以对模型架构进行的第一个更改是更改卷积的数量和转置卷积层。大多数型号使用八层结构。您应该更改前面的代码以添加更多层并比较结果。
- 虽然我们使用了 GAN 和 DCGAN 架构,但您也可以尝试其他 GAN 架构,例如 BigGAN 和 StyleGAN。
- GAN 需要高度内存密集型训练。为了减少计算需求,您可以使用预训练模型。然而,预训练的模型可能只适用于他们训练的原始对象。例如,您可以使用在人脸数据集上训练的预训练 StyleGAN 模型生成新人脸。但是,如果没有针对蝴蝶的预训练模型(例如本章中的数据集),那么它可能效果不佳,从头开始训练可能是唯一的选择。
- 另一种选择是仅将预训练模型用于鉴别器。有很多论文只对判别器使用了 ImageNet 预训练,并取得了不错的效果。您也应该在此示例中尝试相同的操作。
- 最后,继续创造任何你梦寐以求的新事物。GAN 创造的艺术是一个蓬勃发展的新领域。你可以组合任何东西并生成任何东西。谁知道——你的 GAN 艺术 NFT 可能有一天会被高价拍卖!
概括
GAN 是一种强大的方法,不仅可以生成图像,还可以生成绘画,甚至 3D 对象(使用 GAN 的更新变体)。我们看到了如何使用鉴别器和生成器网络(每个都有五个卷积层)的组合,我们可以从随机噪声开始并生成模仿真实图像的图像。生成器和判别器之间的平衡通过最小化损失函数和多次迭代来不断产生更好的图像。最终结果是在现实生活中从未存在过的假图片。
这是一种强大的方法,人们担心它的道德使用。虚假图像和物品可用于欺骗他人;然而,它也创造了无穷无尽的新机会。例如,想象一下在购买新衣服时看着时装模特的照片。无需依赖无休止的图像拍摄,使用 GAN(和 DCGAN),您可以生成具有所有体型、尺寸、形状和颜色的模型的逼真图片,从而帮助公司和消费者。时装模特不是唯一的例子。想象一下出售房屋但没有家具。使用 GAN,您可以创建逼真的家居装饰——再次为房地产开发商节省大量资金。GAN 也是用于增强和深度学习数据生成目的的强大数据源。还,
接下来,我们将继续我们的生成建模之旅。现在我们已经了解了如何教机器生成图像,我们将尝试教机器如何在给定图像的上下文中写诗和生成文本。在下一章中,我们将探索半监督学习,我们将结合 CNN 和 RNN 架构,通过让机器理解图像内部的上下文 来生成类似人类的文本、诗歌或歌词。
![[go学习笔记.第十一章.项目案例] 1.家庭收支记账软件项目](https://img-blog.csdnimg.cn/7c2c3e9c709143d690a3462211b7bfaf.png)

![[数据结构]实现双向链表](https://img-blog.csdnimg.cn/be04ba3b987d4fe48b9ad837a29da3b6.png)