这是在线文档技术的第二篇文章,本文将对目前市面上所有的主流编辑器和在线文档进行一次深入的剖析和研究,从而使大家对在线文档技术有更深入的了解,也让更多人能够参与其开发与设计中来。
注意:出于对主流文档产品的尊重,故在分析这阶段会比较简单,旨在让开发者发现重点,不会深入去解析其前端代码实现。
主流编辑器分析
Slate
架构简析
Slate 是一个完全可订制的富文本编辑器框架,其所有的逻辑都是通过插件来实现的,用户拥有高度的自由,不会被 slate 多定制的规则所约束。
为什么要编写 slate,作者在其编写文档中这样写道,“在发明 Slate 之前,我尝试了大量的富文本编辑器库,我发现使用它们构建简单的 demo 是没有问题的,但是当你开始构建类似于 Medium,Dropbox Paper 或者 Google Docs 这样的项目,你会遇到深层次的问题:编辑器的 “schema” 是硬编码的,编程式转换文档是非常复杂的,对 HTML,MarkDown 等内容的序列化支持看起来像是事后加上的,重新发明一个视图层似乎是效率低并且有局限的,协同编辑不是预先设计好的,代码仓库是庞大的,并非小而可复用的,无法构建复杂,嵌套的文档。”
在 Slate 的世界里,插件是“一等公民”,all in plugin,可以通过插件定制所需要的任何功能,而不受到约束;同时 slate 保持了与 DOM 相同的数据模型,这使得在 DOM 上能做的操作,在 slate 中也可以实现;slate 在设计之处就做了明确的边界划分,将核心和定制版边界描述的十分清晰;同时 slate 在设计之初就考虑到了协同,使用者不需要在接入协同的时候去做彻底重构,可以简单的实现接入。
Slate Core部分架构图如下所示:
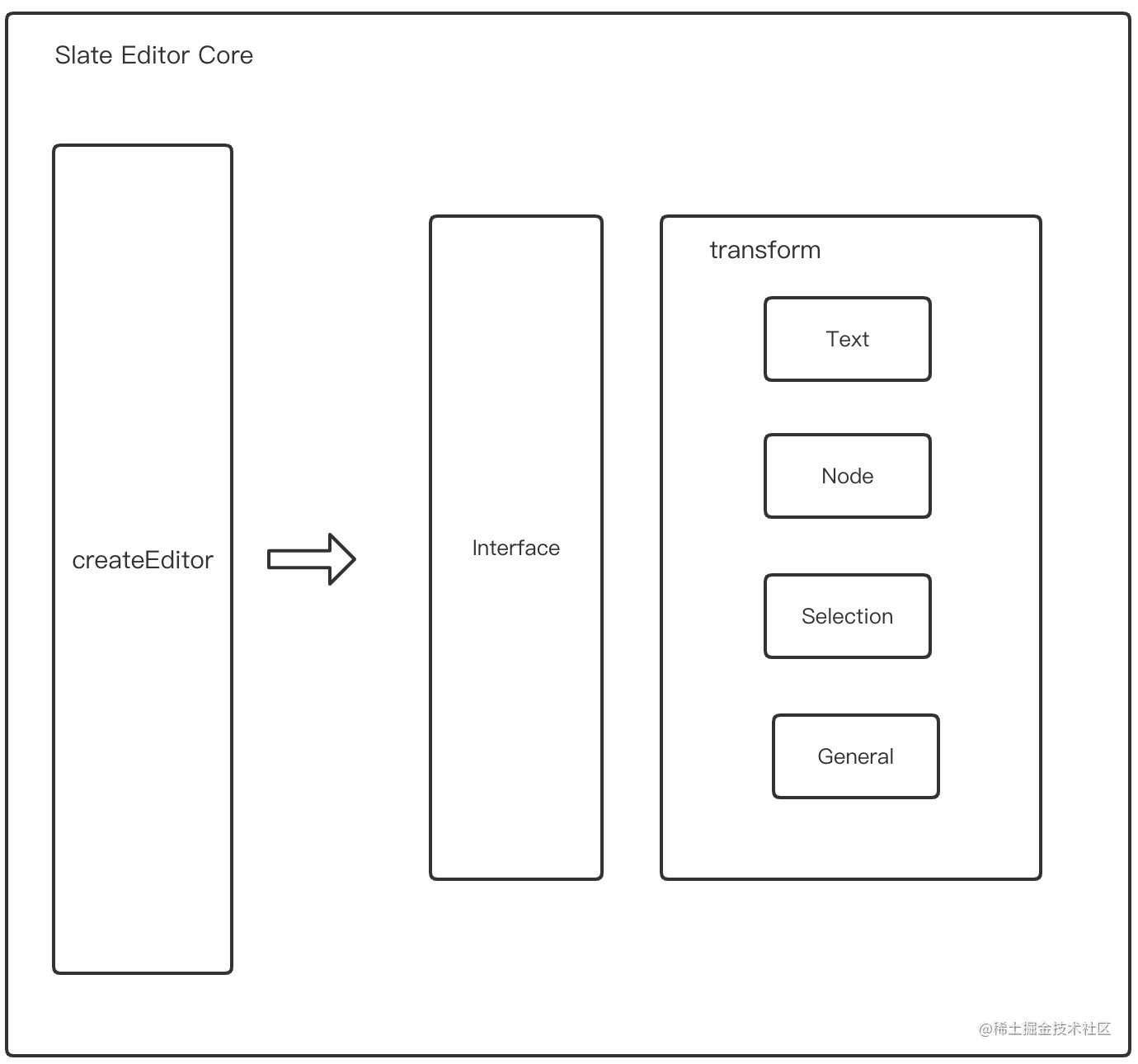
CreateEditor为外部可以直接调用的创建编辑器的方法,常见实用操作如下所示。
const editor = useMemo(() => withHistory(withReact(createEditor())), [])
上述代码就是创建了一个基于React渲染的且支持undo,redo的编辑器,我们可以通过创建方法发现,其扩展功能的方法就是实现一个类似withReact的东西,这个就是slate世界的一等公民:“插件”。
Slate Core部分的代码非常的简洁,仅仅提供了插件扩展能力以及基本的数据流操作能力,其是默认不提供渲染层的,这一点需要我们去进行编写,当然作为一个前端工程师,我相信这并不难。
接着深入createEditor方法,我们会发现createEditor是一个完备的编辑器方法,在内部实现了包括数据原子操作,属性操作,节点操作等编辑器所需的所有基础能力,可以说其架构能力非常之强,具体方法接口如下所示,由于源码中作者为进行接口抽象,这里为了减少代码量,我这里直接用的Interface的方式进行展示。
// IBaseEditor slate的基础能力,基本上都是对原子数据的操作
type interface IBaseEditor {
apply(op: Operation); // 应用op
addMark(key: string, value: any); // 添加属性
deleteBackward(unit: TextUnit);
deleteForward(unit: TextUnit);
deleteFragment(direction?: 'forward' | 'backward');
getFragment();
insertBreak(): void; // 插入回车
insertSoftBreak(): void; // 插入软回车
insertFragment(fragment: Node[]); // 插入Fragment
insertNode(node: Node); // 插入节点
insertText(text: string); // 插入文字
removeMark(key: string); // 移除属性
getDirtyPaths(op: Operation): Path[]; // 获取脏区
}
插件扩展
既然我们说在Slate中插件是一等公民,那么我们如何编写一个插件呢?其方式也是非常的简单,这里我直接copy一个官方React渲染插件进行说明。
- 继承扩展BaseEditor,主要是自己定制化的能力。
- withReact实现接口定制的能力。
- 最后withReact(createEditor());完成插件的使用。
// ReactEditor 扩展基础的编辑器能力
export interface ReactEditor extends BaseEditor {}
export const withReact = (
editor: T,
clipboardFormatKey = 'x-slate-fragment'
): T & ReactEditor => {
// 实现对应的编辑器方法
};
// 最后创建并使用编辑器
const editor = withReact(createEditor())
通过上述操作我们就可以完成一个基于Slate的插件开发工作。
基本数据结构
在 slate 官网中提到,其拥有近似于浏览器 DOM 的 API,其模型为基于 DOM 的一颗嵌套树,其命名,事件定义均符合浏览器标准,能够让开发者很轻易的理解和上手,同时也降低了浏览器处理变更产生的成本。
export type Node = Editor | Element | Text;
export interface Element {
children: Node[];
[key: string]: unknown;
}
export interface Text {
text: string;
[key: string]: unknown;
}
- Element 类型含有 children 属性,可以作为其他 Node 的父节点
- Editor 可以看作是一种特殊的 Element ,它既是编辑器实例类型,也是文档树的根节点
- Text 类型是树的叶子结点,包含文字信息
用户可以自行拓展 Node 的属性,例如通过添加 type 字段标识 Node 的类型(paragraph, ordered list, heading 等等),或者是文本的属性(italic, bold 等等),来描述富文本中的文字和段落。
其中[key: string]: unknown用于属性添加。
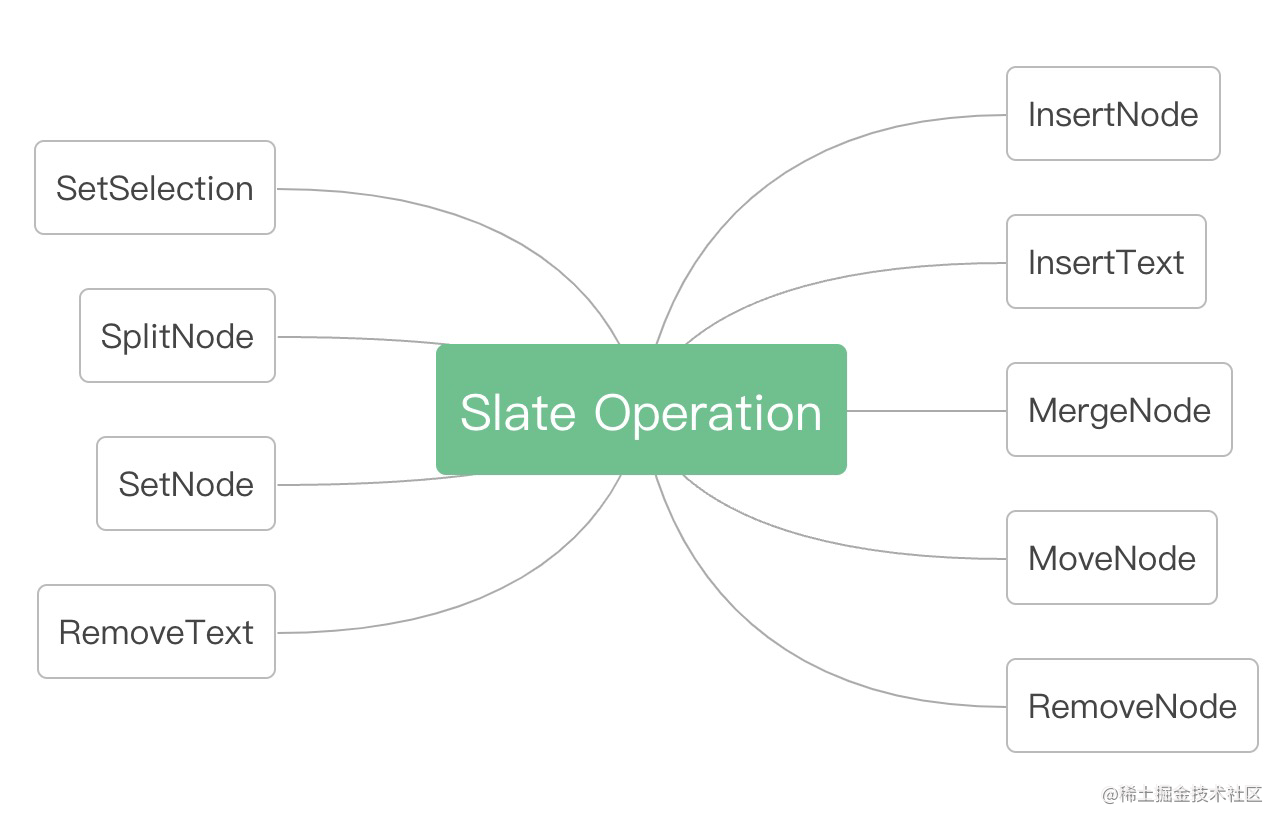
原子操作类型
Slate提供的原子操作类型有9种,涵盖了文字处理,节点处理,选区处理等。
Prosemirror
Prosemirror的设计就更改的模块化了,不像是Slate数据层的处理是在一起的,Prosemirror所有的模块都被剥离为独立的模块,数据Op,Transform,state,View都独立存在。其设计思路高度定制化,使得用户的代码可以完全控制项目,让开发更像是乐高积木,而不是一个整体的汽车。
架构解析
Prosemirror的核心模块主要分为四部分,开发者可以独立维护各自部分。
prosemirror-model定义了编辑器的基础模型,用于描述编辑器内容的数据结构。prosemirror-state提供描述编辑器整个状态的数据结构,类似于Context的玩意儿。prosemirror-view视图层,提供一个用户组件界面,使得用户可以直接操作编辑。prosemirror-transform包含以可以记录和重放的方式修改文档的功能(基础编辑能力的实现),这是模块中事务的基础state,并且使撤消历史记录和协作编辑成为可能。
大概架构设计如下所示:
View为渲染的视图层,State为编辑器状态管理,编辑器的核心能力都在这里可以实现,类似于Context的玩意儿,Transform和Model咱们就不细细分析了,大家的思路大差不差。
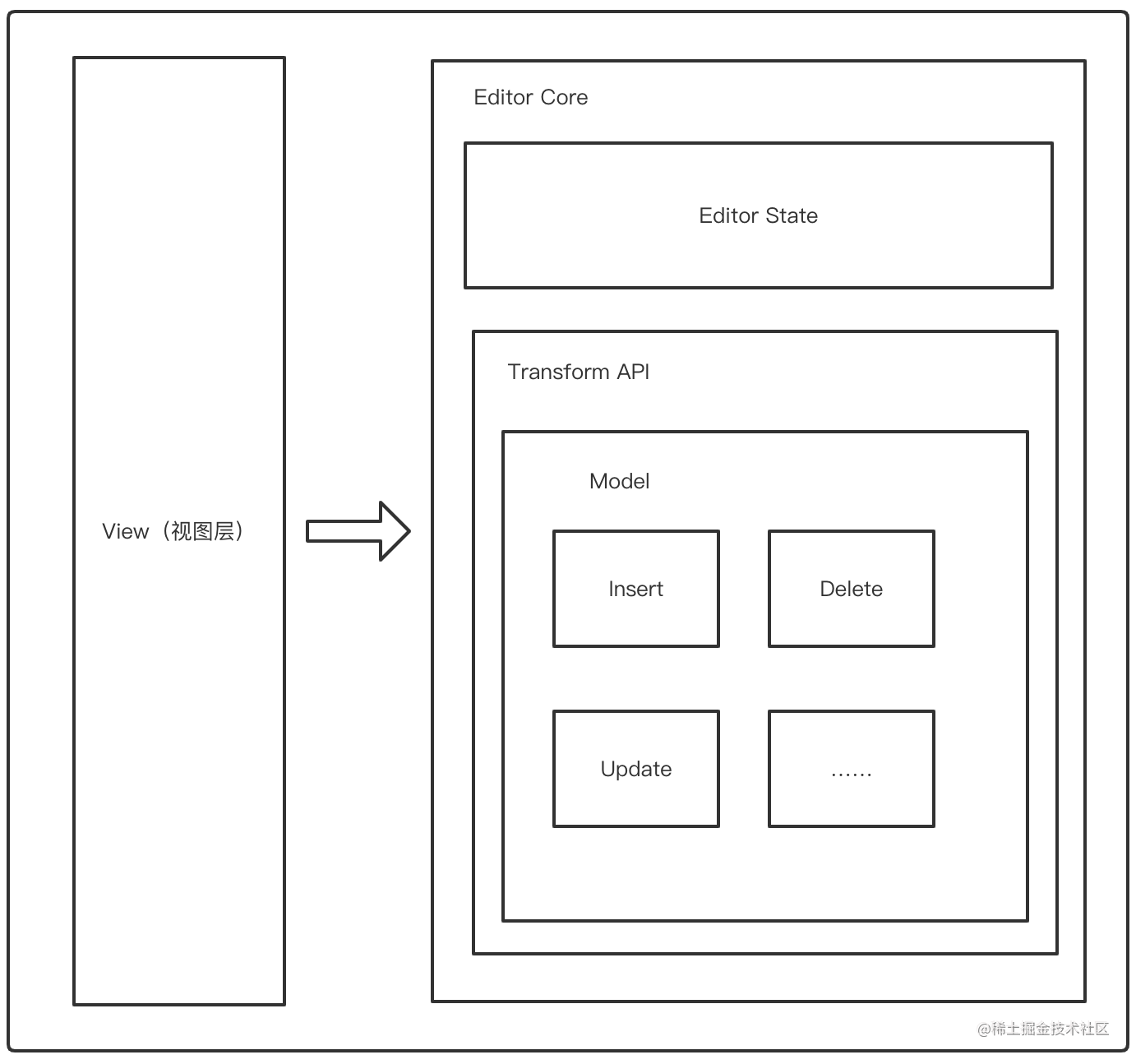
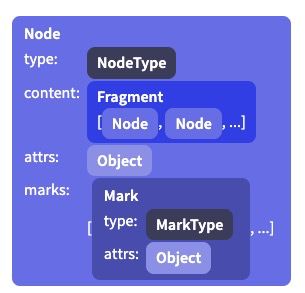
同时在数据结构的设计上Prosemirro也是遵循了和浏览器DOM相似的原则,具体图如下所示(图片来自于Prosemirror官方文档)。
Ace
相比前面的Prosemirror和Slate,Ace的完成度就相当的高了,代码量也相当的庞大。其特征包括(来自github/ace的readme文件):
- Syntax highlighting for over 120 languages (支持超过120种语言的语法高亮)
- Over 20 themes (支持超过20种主题)
- Automatic indent and outdent(自动缩进的能力)
- An optional command line (支持可选命令)
- Handles huge documents (能够处理巨大的文档)
- Fully customizable key bindings including vim and Emacs modes(可定制快捷键)
- Search and replace with regular expressions(支持使用正则表达式搜索和替换)
- Highlight matching parentheses(突出显示)
- Toggle between soft tabs and real tabs(选项卡切换)
- Displays hidden characters(字符的隐藏和显示)
- Drag and drop text using the mouse(支持鼠标拖拽文本)
- Line wrapping(换行)
- Code folding(代码折叠)
- Multiple cursors and selections(多光标和选择)
- Live syntax checker(语法检查)
- Cut, copy, and paste functionality(复制粘贴)
通过上面的的特征描述,我们可以毫不客气的说,ace编辑器只需要简单改改就可以直接进行商业化,此编辑器已经具备的完备的能力。
因为篇幅关系,我这里就不再向前两个一样详细分析了,如果要做产品,我会比较推荐这个。
主流在线文档产品分析
腾讯文档
腾讯文档是基于多人实时在线编辑技术的文档协作与文件共享平台。同时提供包含帐号、品类、盘、管理后台、API、安全等能力与企业内部系统进行无缝集成,从而实现自动化文档工作流。
因为腾讯文档的品类众多,所以我们暂时只分析其在线编辑器部分,首先我们先通过Chrome的搜索能力,搜索一些关键词看看其有么有使用开源的编辑器。通过DOM我们可以发现,腾讯文档的编辑器不同于前面所分析的各种编辑器,而是采用的Canvas渲染,至于这种渲染的优劣我也不太好评价。

我们通过前端页面渲染的DOM可以发现,虽然这里展示主要是依赖Canvas渲染,其还是有部分是挂的DOM,至于原因我也不知道,估计是其业务比较复杂有些能力Canvas无法支持,所以选择外挂的形式进行补充。
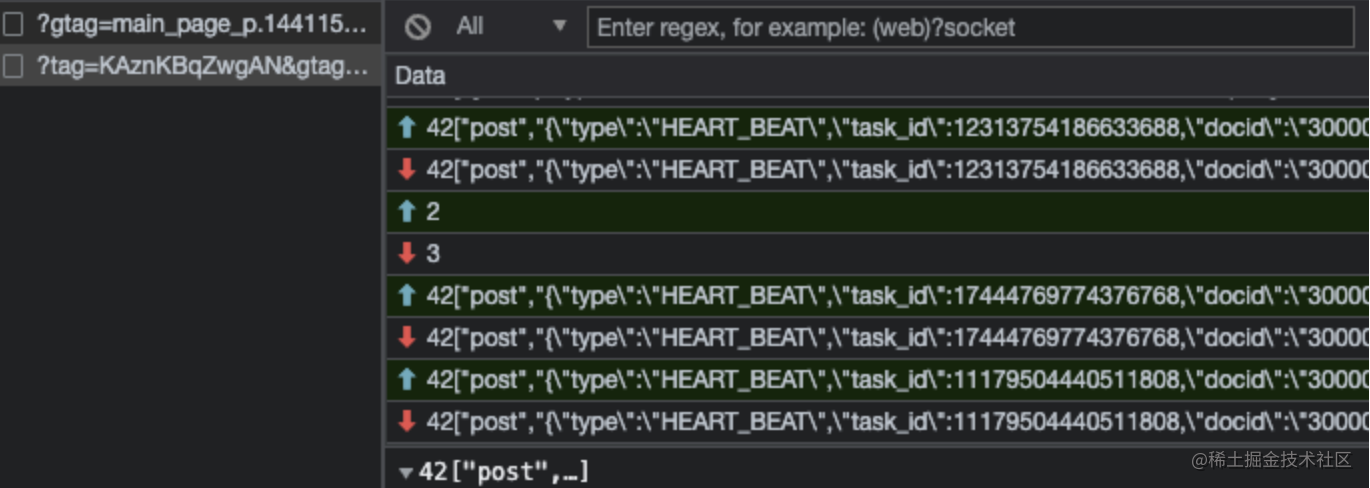
打开Chrome的控制台选择Network,我们会发现腾讯文档的数据更新与同步是采用WS的形式进行传递的,这一点和Google Doc不同,GoogleDoc是采用轮询API的方式进行同步的。
金山云文档
金山文档是由珠海金山办公软件有限公司发布的一款可多人实时协作编辑的文档创作工具软件。 [1] 金山文档可应用于常见的办公软件,如文字Word、表格Excel、演示PPT。
金山文档做了两套在线文档Doc,我们先分析第一个。
这个在线文档我们很容易在节点中发现其使用了开源编辑器Prosemirror,基本是按照Prosemirror的结构来展示的。
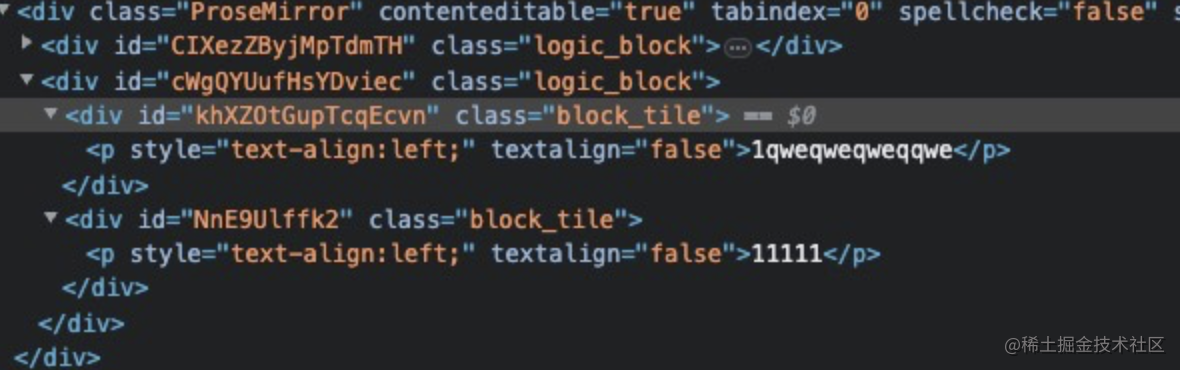
在数据交换上,金山文档和腾讯文档类似都采用WS的方向进行通讯,其中一个WS通道负责心跳检测,另一个负责数据交换。
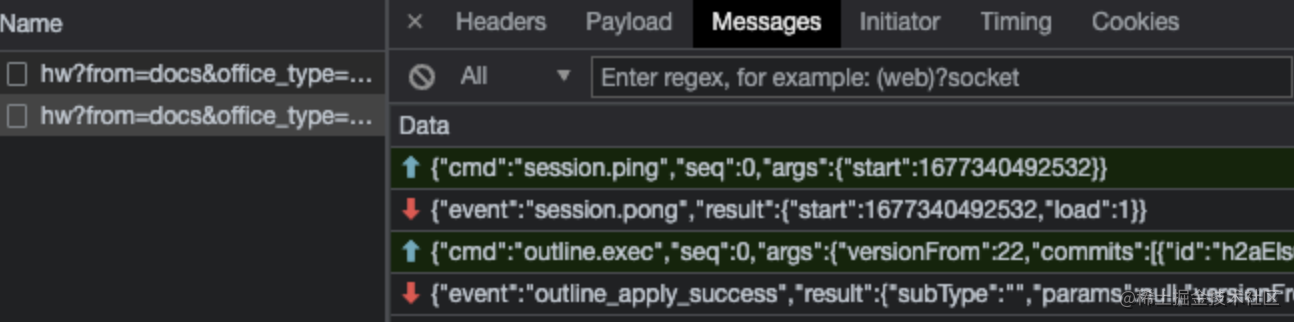
飞书文档
飞书文档作为后起之秀,其设计,用户体验已经逐渐超越腾讯文档和金山文档,同样老规矩我们先看他用的啥编辑器。打开控制台,我们会发现ace字样,我们推测其使用的是ace编辑器,同样通过控制台,我们可以看到其数据结构也是个树形。
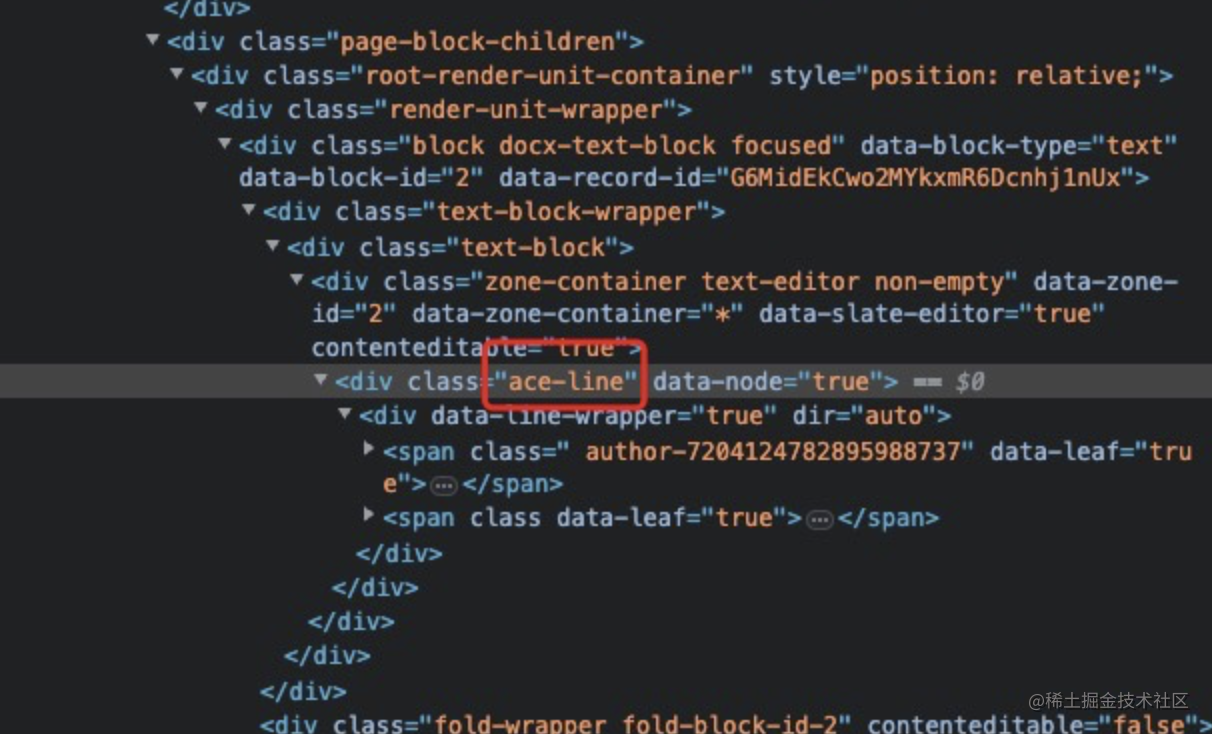
其中飞书的后台提交和其他几家不同,飞书采用的是cgi的提交方式,这一点和Google很像。
谷歌文档
谷歌文档作为在线文档界的鼻祖,那在行业的积累那是相当炸裂的,体验也是几家最好的。google和腾讯文档一样也采用的canvas渲染,据说这个canvas渲染google内部研究了好几年,作者对比了一下腾讯文档和google文档的体验,毫不客气的说google做的cavnas渲染比腾讯文档好很多倍。
其次,Google文档前端的混淆也是相当的厉害,几乎达到了完全不可读的程度。当然也不是完全没办法。
打开控制台,我们通过如下命令可以获取到Google编辑器的数据结构,
window.KX_kixApp
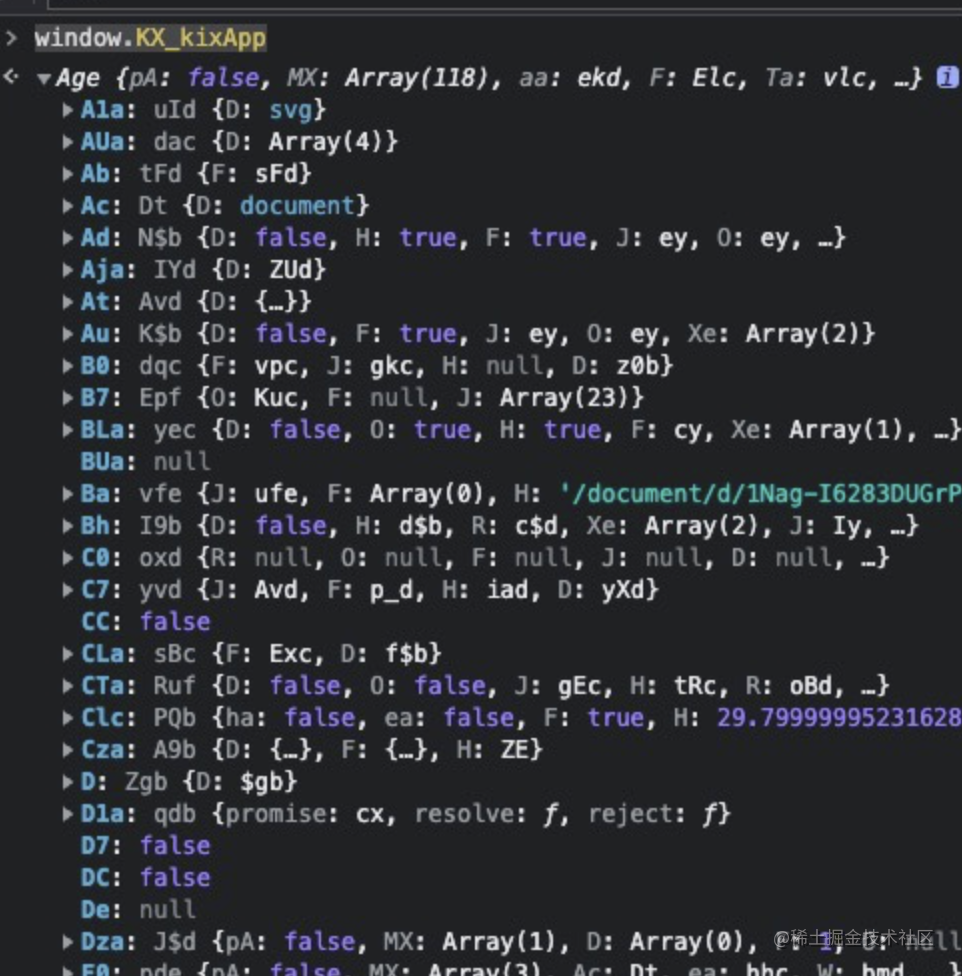
虽然可读性很差,但是慢慢debug,总体还是可以查看的。当然如果大佬们有时间可以通过映射字符还原文档,比如如下这种。
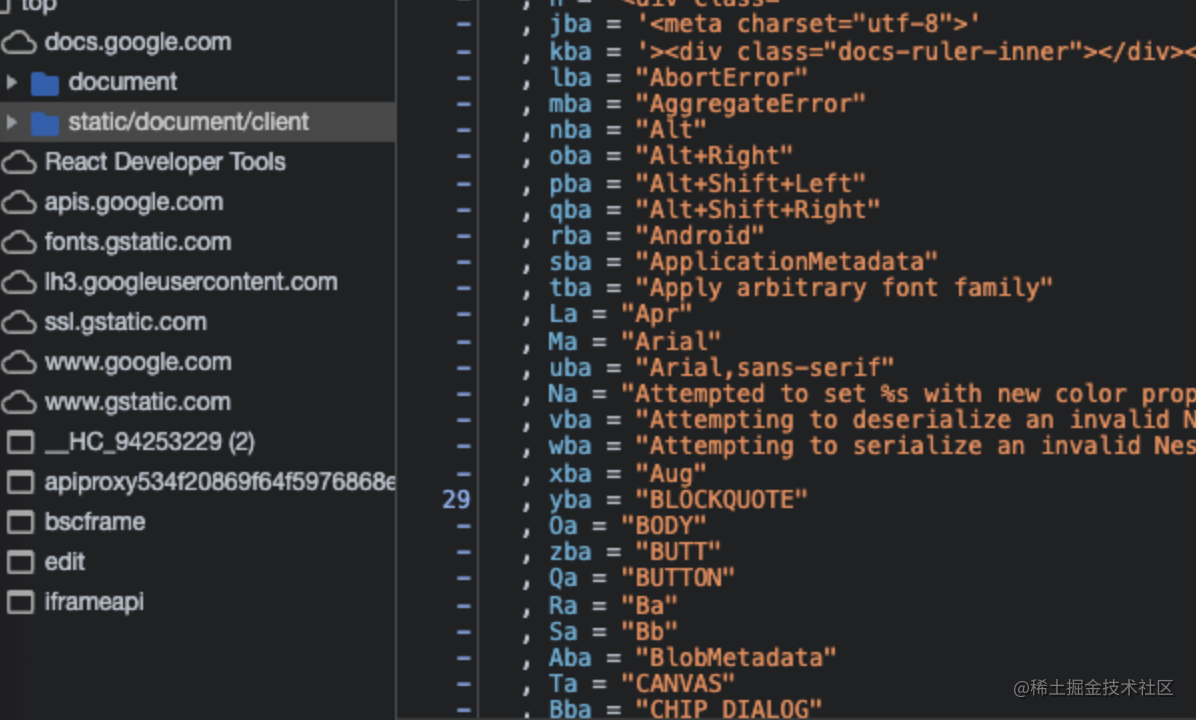
Google的数据提交和飞书一样是采用轮询CGI的方式进行提交,数据结构如下所示,为了方便理解我在下方做了一定的解释。
[
{
"commands":[
{
"ty":"is", // Operation类型
"ibi":11, // 插入坐标
"s":"1" // 插入内容
}
],
"sid":"151f773a331f21bc",
"reqId":1
}
]
没错is就是GoogleDocs的一个Op,我们可以通过同样的方式继续挖掘google 的op设计,从而完成产品的分析。
对比
| 产品 | 编辑器渲染类型 | 数据提交方式 | 协同算法 | 采用框架 |
|---|---|---|---|---|
| 腾讯文档 | Canvas | websocket | OT算法 | 自研Canvas引擎 |
| 金山文档 | DOM | websocket | OT算法 | Prosemirror |
| 飞书文档 | DOM | CGI轮询 | OT算法 | Ace |
| 谷歌文档 | Canvas | CGI轮询 | OT算法 | 自研Canvas引擎 |
通过上述表格,我们就可以知道各家的产品都是啥样了。
最后
最后希望大家能在我的文章中有所收获,欢迎交流。
参考链接
https://www.kdocs.cn/latest?from=docs 金山文档
https://ace.c9.io/#nav=embedding Ace编辑器
https://prosemirror.net/ Prosemirror编辑器
https://www.slatejs.org Slate源码