Enhanced Context Attention Network for Image Super Resolution
(基于增强上下文注意网络的图像超分辨率)
深度卷积神经网络(CNN)极大地提高了图像超分辨率(SR)的性能。尽管图像随机共振的目标是恢复高频细节,但大多数随机共振方法仍然侧重于通过深而宽的网络生成高级特征。它们缺乏对隐藏在丰富CNN特征中的高频信息的区分能力,从而阻碍了CNN产生更好的SR结果。为了解决这个问题,我们提出两个新的注意机制:语境加权通道注意(CWCA)和持续空间注意(PSA)。它们通过抑制无用特征和增强感兴趣的特征,以通道和空间的方式对丰富的特征进行调制。然后使网络能够更多地集中于与图像的高频分量密切相关的信息特征。此外,我们提出了具有密集连接的增强注意残差群(EARG-D),不仅捕获短期信息,而且捕获长期信息,以保持更多有用的特征。最后,我们构造了一个深度增强的上下文注意超分辨率网络(EASR),以获得更好的图像重建效果,定量和定性实验表明,该方法的性能优于现有的随机共振方法。
超分辨率(SR)图片是一个高度不适定的逆问题,其目标是从低分辨率(LR)图像重建出视觉上令人愉悦的高分辨率(HR)图像。它是经典的计算机视觉任务之一,越来越受到学者们的关注。近年来,随着深度学习的快速发展,基于卷积神经网络(CNN)的许多方法被提出来解决该逆问题。Dong等人首次尝试利用三层CNN(SRCNN)求解图像SR,Kim等人在引入跳跃连接的同时,提出了更深层次的网络VDSR,以减轻模型训练的难度。遵循类似的思想,已经提出了许多具有诸如递归学习和存储器块之类的仔细网络设计的预放大网络。然而,预放大网络以二次方式增加计算复杂度。为了保存计算资源,Dong等人引入了去卷积层来提高空间分辨率。Shi等人提出了ESPCN ,以使用高效的亚像素卷积层来放大特征图,从而可以直接从LR图像中提取特征。随后,各种工作集中于如何有效地从LR输入中提取特征以提高SR性能。Ledig等人首先利用ResNet中的残差块提出了深度网络SRResNet 。Lim等人提出了两个残差网络EDSR和MDSR ,赢得了NTIRE 2017超分辨率挑战赛。后来,针对SR引入了DenseNet中的密集连接。Zhang等人通过将稠密连接集成到残差块中,提出了一种残差稠密网络RDN 。深度和广度的网络可以获得令人信服的SR性能增益,但它仍然具有局限性。网络中丰富的特征将包含关于图像的不同类型的信息,例如轮廓、纹理和强度。由于图像SR的目标是HR图像的重建,因此,与包含低频信息的特征相比,包含高频信息的特征更有利于图像SR。然而,大多数SR方法没有区分这些层次特征,从而阻碍了CNNs恢复更好的SR结果。
为了解决这个问题,我们提出了两种新的图像SR注意机制:上下文加权通道注意(CWCA)机制和持续空间注意(PSA)机制。CWCA通过对比度上下文加权池(CCWP)自适应地挤压通道特征。然后利用通道依赖性来强调感兴趣的通道特征。PSA修改空间信息统计以重新校准每个空间位置中的特征。在每个PSA单元中,经由增强空间注意力(ESA)单元从输入特征生成粗略空间注意力(SA)图。PSA对先前的空间注意特征图进行密集聚合,并生成残差SA图,以将当前SA图重新校准为更好的SA图,从而形成持久的空间注意记忆机制。CWCA和PSA增强了网络的区分学习能力,使其更加关注信道和空间两方面的信息特征。此外,我们还提出了一个具有稠密连接的增强注意残差群(EARG-D)。EARG-D将不仅收集短期信息,而且收集长期信息,以保持更多有用的特征。最后,我们构造了一个深度增强的上下文注意超分辨率网络(EASR)来更好地重建HR图像。
贡献
1)提出了一种上下文加权信道关注机制(CWCA)来有效利用信道依赖性。CWCA使用对比度上下文加权池(CCWP)以更精确的方式挤压特征。因此,网络可以更加关注信息性特征,从而增强网络区分能力。
2)我们提出持续性空间注意力机制(PSA),以适应性地在空间维度上重新缩放特征。PSA首先利用增强的空间注意力(ESA)单元来生成粗略的空间注意力图。它进一步密集地融合先前的空间注意特征图来微调当前的SA图,从而导致持续的空间注意记忆机制。
3)提出了一种深度增强的上下文注意超分辨率网络(EASR)用于图像SR,定量和定性实验表明,EASR的性能上级现有的SR方法。
相关工作
CNN Based SR Methods
自从Dong等人提出SRCNN以来,许多CNN结构已经被提出用于SR。Kim等人提出了具有20个卷积层的跳跃连接的更深网络VDSR。Kim等人随后提出了一种深度递归网络DRCN,它同时使用了跳跃连接和递归卷积层。然而,这些预放大网络需要对LR图像进行上插,这增加了计算复杂度。为了减轻计算负担,Dong等人引入了去卷积层以提高网络尾部的空间分辨率。Shi等人进一步提出了一种具有高效亚像素卷积层的后上尺度网络ESPCN ,其最近也通过在EUM中级联多尺度特征而得到增强。在ESPCN和SRResNet 之后,EDSR 通过移除不必要的层(例如,批归一化层)来修改使用的残差块。简化残差块已成为基于CNN的随机共振方法中最常用的模块。随后SRDenseNet、RDN和CARN利用稠密连接融合网络中的层次特征,为随机共振提供了更多线索,而这在以前的工作中被忽略了。
利用这种后尺度结构,我们还利用了亚像素卷积层以及残差学习和稠密连接在我们提出的方法。我们进一步利用通道注意和空间注意机制来提高网络对不同层次特征的区分能力。
Attention Mechanism
注意在人类感知中起着重要的作用。它允许人类视觉系统选择性地处理视觉信号并聚焦于显著区域以捕获更好的视觉信息。近年来,已经进行了一些尝试将注意机制集成到高级计算机视觉任务中。Zhang等人首先将通道注意(CA)机制引入图像SR,他们将SE块直接用于极深卷积网络RCAN,并取得了优于以往SOTA方法的性能。Hui等人用标准差和平均值的总和取代了SE块中的全局平均合并,并提出了图像SR的对比度感知通道注意。
然而,CA仍然以全局方式为特征,这导致对SR有益的大部分高频信息被丢弃。Hu等人利用RCAN 中的CA机制和空间注意力(SA)机制以全局和局部的方式动态地重新校准多级特征,但SA仅聚合通道式特征以调制空间信息。为了解决这些缺点,我们提出了上下文加权信道关注(CWCA)和持续空间关注(PSA)。
方法
Context Weighted Channel Attention
通道注意力用于以全局的方式重新校准特征,以增强感兴趣的特征,同时抑制无用的特征。以前的工作利用平均池以全局方式squeeze特征。虽然平均池有助于提高性能,但忽略了高频分量的信息,应引起更多的关注。本文引入对比度上下文加权池(CCWP)作为压缩过程,根据空间区域的对比度信息对全局特征进行加权压缩。
给定输入U =[u1,u2,…,uC]∈
R
C
×
H
×
W
R^{C×H×W}
RC×H×W,该模型有C个H×W大小的特征图,我们首先通过减去每个特征图的均值来归一化每个特征图,得到对比度-上下文特征图
U
c
c
U^{cc}
Ucc =[
u
c
c
1
,
u^{cc}~1~,
ucc 1 ,u{cc}$~2~,…,$u{cc}C ]∈
R
C
×
H
×
W
R^{C×H×W}
RC×H×W:
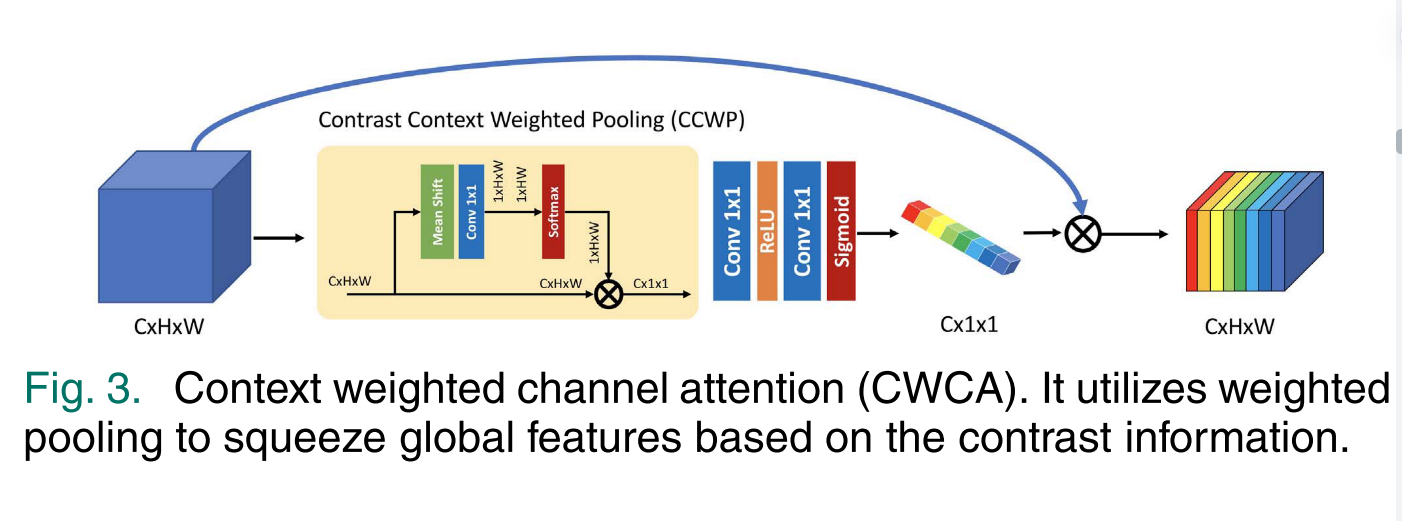
然后我们利用一个1 × 1卷积层和softmax激活函数σ作为变换过程,生成每个位置的像素权重,如图3所示: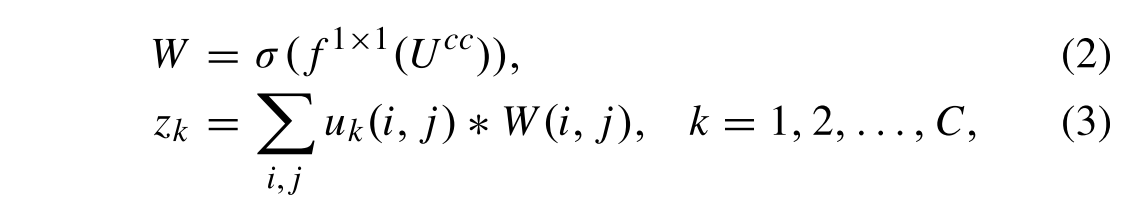
其中W是用于加权池化的权重映射,zk是CCWP的第k个压缩输出。最后,我们使用激励和缩放过程来形成所提出的上下文加权信道关注度,如图3所示。
Enhanced Spatial Attention
由于通道注意力通过挤压和激励全局信息来区分通道方面的特征,空间方面的信息也被去除。对于图像而言,不同的空间区域包含不同的信息特征。边缘和纹理区域通常包含高频分量,而平坦区域更可能包含低频信息。提高网络对不同空间区域的区分能力,对包含高频细节的区域给予更多的关注是必要的。为此,提出了增强空间注意力(ESA)来增强网络的表征能力。与提出的SA方法不同,ESA不是通过简单地挤压通道方面的特征,而是通过聚合空间方面和通道方面的上下文信息来选择不同局部区域中的重要特征。通过第4节中的定量实验证明了其上级性和有效性。ESA包括挤压和激发过程。对于挤压过程,ESA使用4个卷积层。该算法首先将CWCA中的输入特征图U ∈ R C × H × W R^{C×H×W} RC×H×W归一化为 U c c U^{cc} Ucc,然后利用1 × 1卷积层将特征图压缩为降维 R ( C / r ) × H × W R^{(C/r)×H×W} R(C/r)×H×W,压缩比为r。其次,利用两个3×3的深度可分离卷积层提取空间维的上下文特征。最后的1×1卷积层进一步将特征缩减为 R 1 × H × W R^{1×H×W} R1×H×W。最后,激发过程生成一个具有sigmoid激活函数的空间注意特征图βESA ∈ R 1 × H × W R^{1×H×W} R1×H×W。
Persistent Spatial Attention
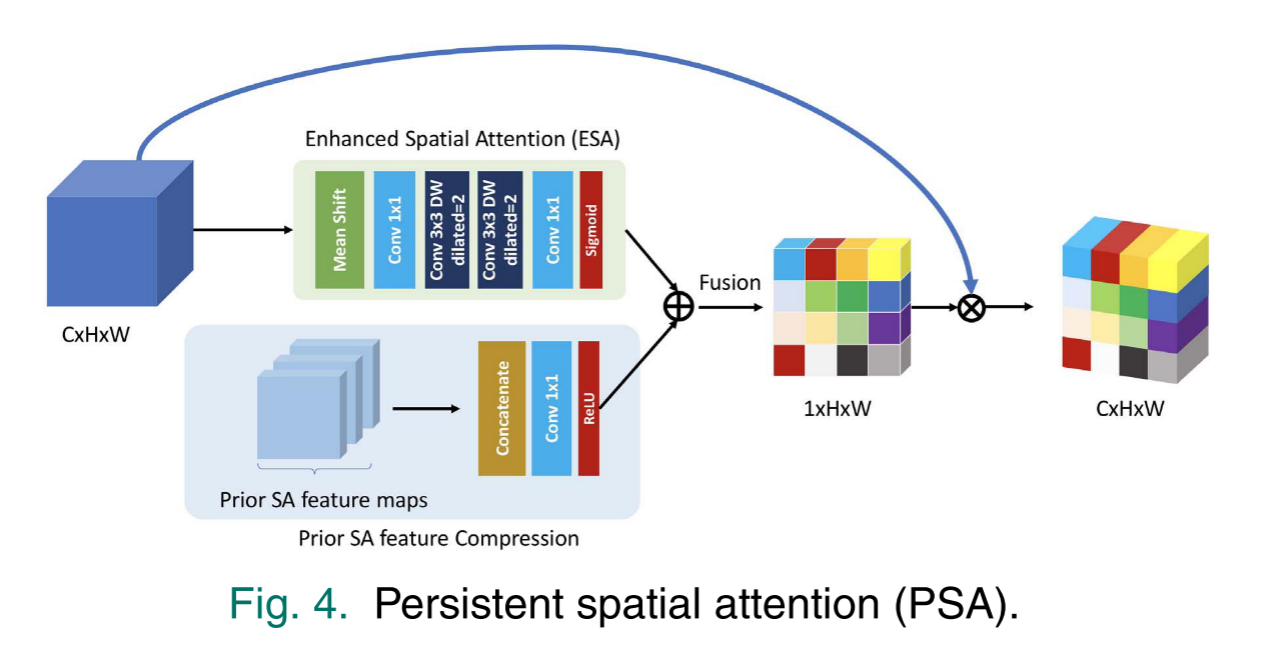
空间的关注(SA)提取空间关注基于特征映射的从前馈输入功能。由于不同的接受域卷积网络层深,中间卷积特性将成为分层。这意味着从不同特征中提取的不同SA特征也包含不同的空间信息。另一方面,图像中高频信息的分布在网络的前馈过程期间不改变。如果结合这些多尺度SA特征,则将有益于网络。我们提出持续空间注意(PSA)来密集融合全局SA特征图。
PSA中有两个过程:压缩和融合。压缩过程融合并压缩网络的先前SA特征以生成残余SA特征图,并且融合过程执行当前SA特征图与残余SA特征图之间的残余连接。对于第n个PSA,其可表示为: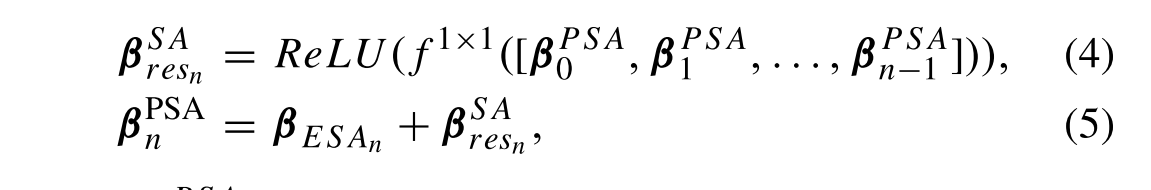
其中
β
P
S
A
n
表示第
n
个
P
S
A
的输出
S
A
特征图,
β
E
S
A
n
表示第
n
个
E
S
A
单元产生的当前
S
A
特征图,
β^{PSA}~n~表示第n个PSA的输出SA特征图,β~ESAn~表示第n个ESA单元产生的当前SA特征图,
βPSA n 表示第n个PSA的输出SA特征图,β ESAn 表示第n个ESA单元产生的当前SA特征图,β^{SA}resn表示PSA中压缩过程产生的残余SA特征图。特别地,当n = 0时,
β
P
S
A
0
=
β
E
S
A
0
。
P
S
A
算法通过密集地聚集先前的
S
A
特征,动态地调整当前的
S
A
特征映射,使其更加准确,从而形成一种持久的空间注意记忆机制。最后,通过输出
S
A
映射
β^{PSA}~0~= β~ESA0~。PSA算法通过密集地聚集先前的SA特征,动态地调整当前的SA特征映射,使其更加准确,从而形成一种持久的空间注意记忆机制。最后,通过输出SA映射
βPSA 0 =β ESA0 。PSA算法通过密集地聚集先前的SA特征,动态地调整当前的SA特征映射,使其更加准确,从而形成一种持久的空间注意记忆机制。最后,通过输出SA映射β^{PSA}$调制输入特征:
Network Architecture
如图2所示,我们的EASR的总体架构由三部分组成:粗图像特征提取模块(IFE)、密集特征提取模块(DFE)和重构模块(RE)。IFE利用一个卷积层来提取粗略的图像特征。DFE包含具有密集连接的级联增强注意残差群(EARG-D)。DFE中有N个EARG-D和两个卷积层。
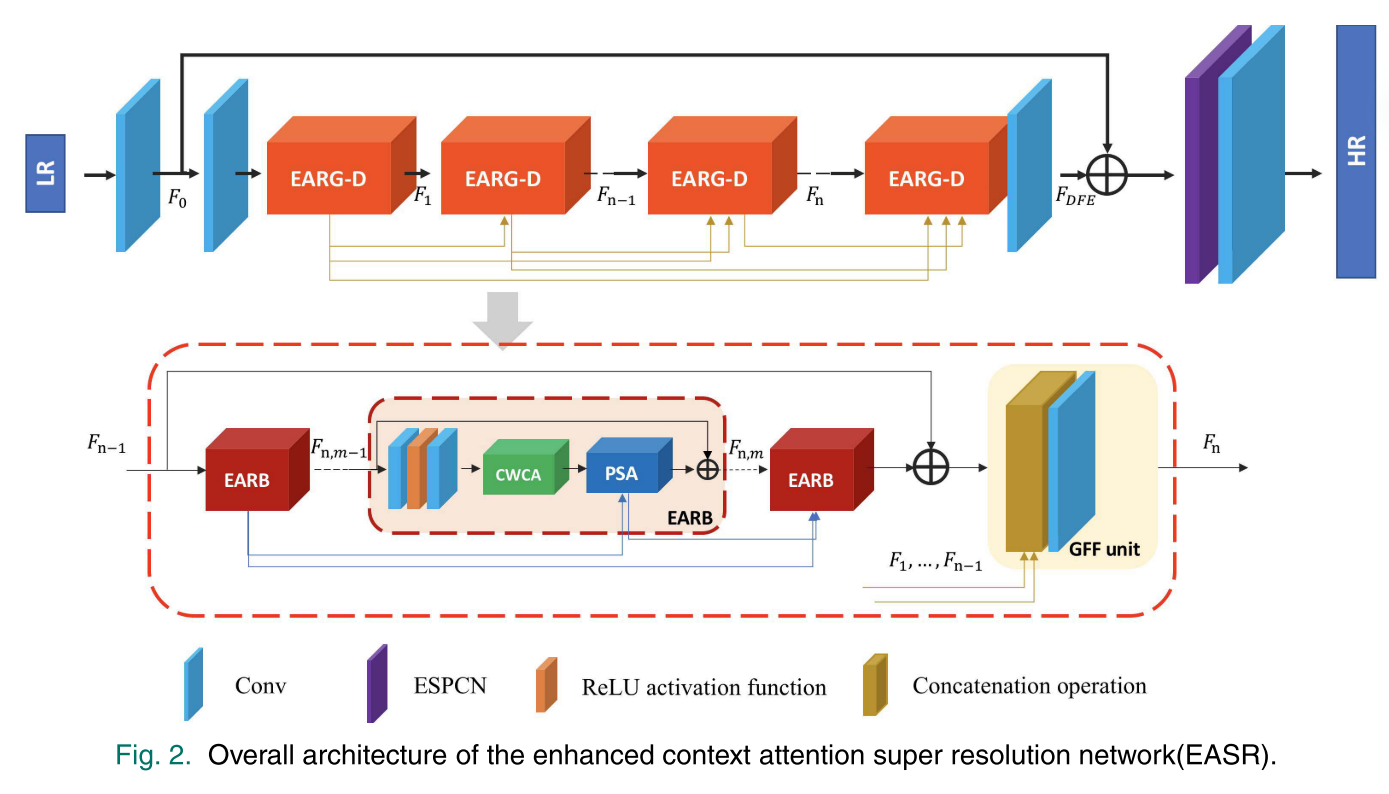
对于单个EARG-D,存在M个堆叠的增强注意残差块(EARB)和尾部的一个全局特征融合(GFF)单元。GFF单元将网络中的前几个EARG-D密集连接起来,融合前几个特征,生成一个1×1卷积层的EARG-D最终输出。在每个EARB中,两个卷积层和一个ReLU激活函数被用作特征提取单元。然后,CWCA单元和PSA单元被顺序地整合以重新校准通道方面和空间方面的特征。特别地,PSA仅聚集来自同一EARG-D中的EARB的先前SA特征。
最后,我们使用ESPCN作为RE模块来生成SR图像。给定训练数据集{
I
n
I^n
InLR,
I
n
I^n
InHR}N n=1,其中N表示训练图像对的数量,我们使用L1损失来训练我们的EASR网络,以最小化HR图像和SR图像之间的差异: